В этой статье разберем, что такое парный трейдинг и как происходит торговля на корреляциях. Также создадим советник для автоматизации парного трейдинга и добавим возможность автоматической оптимизации такого торгового алгоритма на исторических данных. Кроме того, в рамках проекта узнаем, как рассчитывать расхождения двух пар с помощью z-оценки.
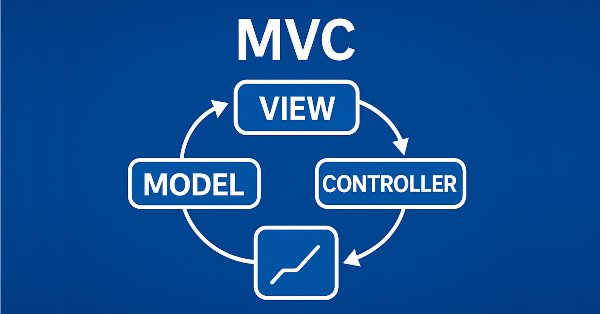
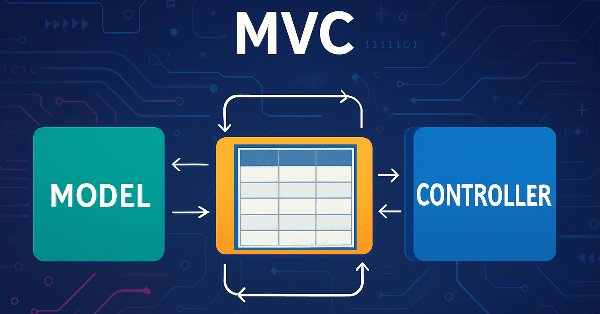
Это вторая часть статьи, посвященной реализации модели таблицы в MQL5 с использованием архитектурной парадигмы MVC (Model-View-Controller). В статье рассматривается разработка классов таблицы и её заголовка, основанных на ранее созданной модели таблицы. Разработанные классы станут основой для дальнейшей реализации компонентов представления (View) и управления (Controller), которые будут рассмотрены в следующих статьях.
В статье использованы альтернативные ежедневные данные Федерального резервного банка Сент-Луиса по обобщенному индексу доллара США и набор других макроэкономических показателей для прогнозирования будущего обменного курса EURUSD. К сожалению, хотя данные, по-видимому, имеют почти идеальную корреляцию, нам не удалось получить никаких существенных преимуществ в точности нашей модели, что, наводит нас на мысль, что инвесторам, возможно, лучше использовать обычные рыночные котировки.
Статья рассматривает теоретические и практические аспекты метода сингулярного спектрального анализа (SSA), который представляет собой эффективный метод анализа временных рядов, позволяющий представить сложную структуру ряда в виде разложения на простые компоненты, такие как тренд, сезонные (периодические) колебания и шум.
В настоящем проекте исследуется сочетание глубокого обучения и технического анализа для тестирования торговых стратегий на рынке Форекс. Для быстрого экспериментирования используется скрипт на Python, использующий модель ONNX наряду с традиционными индикаторами, такими как PSAR, SMA и RSI, для прогнозирования движения пары EUR/USD. Затем скрипт MetaTrader 5 переносит эту стратегию в реальную среду, используя исторические данные и технический анализ для принятия обоснованных торговых решений. Результаты тестирования на исторических данных свидетельствуют об осторожном, но последовательном подходе, направленном на управление рисками и устойчивый рост, а не на агрессивную погоню за прибылью.
В статье мы рассмотрим, как использовать ИИ для оптимизации размера позиции и количества ордеров, чтобы максимизировать доходность портфеля. Мы покажем, как алгоритмически определить оптимальный портфель и адаптировать его к вашим ожиданиям по доходности или уровню устойчивости к риску. Мы используем библиотеку SciPy и язык MQL5 для создания оптимального и диверсифицированного портфеля, используя все имеющиеся у нас данные.
Этот инновационный торговый бот интегрирует платформу MetaTrader 5 с языком Python в целях использования анализа настроений в социальных сетях в режиме реального времени для автоматизированного принятия торговых решений. Путем анализа настроений в Twitter, связанных с конкретными финансовыми инструментами, бот преобразует тенденции социальных сетей в действенные торговые сигналы. Он использует архитектуру «клиент-сервер» с сокетной связью, обеспечивая бесперебойное взаимодействие между торговыми возможностями MetaTrader 5 и вычислительной мощностью Python.
Раскройте свой потенциал! Вас окружают возможности. Узнайте 3 главных секрета, с помощью которых вы начнете изучать MQL5 или перейдете на новый уровень владения этим языком. Погрузимся в обсуждение советов и рекомендаций, в равной степени полезных и начинающим, и профи.
В этой статье мы рассмотрим, что такое динамический массив и массив статический. И есть ли разница между использованием одного или другого. Или они всегда одинаковы? Когда следует использовать один, а когда другой? А как насчет константных массивов? Для чего они существуют, и какому риску я подвергаюсь, если не инициализирую все значения в массиве? Предположим, что они будут равны нулю.
В этой статье мы рассмотрим особенности применения некоторых критериев тренда на практике. А также сделаем попытку разработать несколько новых критериев. Основное внимание будет уделено эффективности применения этих критериев для анализа рыночных данных и трейдинга.
Фреймворк Actor–Director–Critic — это эволюция классической архитектуры агентного обучения. В статье представлен практический опыт его реализации и адаптации к условиям финансовых рынков.
В статье мы продемонстрируем, как можно создавать торговые приложения на базе ИИ, способные учиться на собственных ошибках. Мы рассмотрим технику, известную как стекинг (stacking), при которой мы используем 2 модели для создания 1 прогноза. Первая модель, как правило, является более слабым обучающимся алгоритмом, а вторая - более мощной моделью, которая обучается на результатах более слабого алгоритма. Наша цель — создать ансамбль моделей, чтобы достичь более высокой точности.
Что такое угловой анализ финансовых рынков? Как использовать углы движения цен и машинное обучение для точного прогнозирования с точностью 67? Как совместить регрессионную и классификационную модель с угловыми признаками и получить работающий алгоритм? Причем тут Ганн? Почему углы движения цен являются хорошим признаком для машинного обучения?
В настоящей статье мы сосредоточимся на визуальном оформлении графического интерфейса пользователя (GUI) нашей торговой панели администратора с использованием MQL5. Мы рассмотрим различные методы и функции, доступные в MQL5, которые позволяют настраивать и оптимизировать интерфейс, обеспечивая его соответствие потребностям трейдеров при сохранении привлекательной эстетики.
Мы проанализируем альтернативные данные, собранные Чикагской опционной биржей (Chicago Board of Options Exchange, CBOE), чтобы повысить точность наших глубоких нейронных сетей при прогнозировании символа XAUEUR.
В данной статье представлен комплексный анализ алгоритма оптимизации коралловых рифов (CRO) — метаэвристического метода, вдохновленного биологическими процессами формирования и развития коралловых рифов. Алгоритм моделирует ключевые аспекты эволюции кораллов: внешнее и внутреннее размножение, оседание личинок, бесполое размножение и конкуренцию за ограниченное пространство в рифе. Особое внимание в работе уделяется усовершенствованной версии алгоритма.
В данной статье продемонстрирован подход к созданию торговых стратегий для золота с помощью машинного обучения. Рассматривая предложенный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов.
Определяем перекупленность и перепроданность рынка по теории хаоса: интеграция принципов теории хаоса, фрактальной геометрии и нейронных сетей для прогнозирования финансовых рынков. Исследование демонстрирует применение показателя Ляпунова, как меры рыночной хаотичности, и динамическую адаптацию торговых сигналов. Методология включает алгоритм генерации фрактального шума, гиперболическую тангенциальную активацию и оптимизацию с моментом.
Предлагаем познакомиться с фреймворком Actor-Director-Critic, который сочетает в себе иерархическое обучение и многокомпонентную архитектуру для создания адаптивных торговых стратегий. В этой статье мы подробно рассмотрим, как использование Режиссера для классификации действий Актера помогает эффективно оптимизировать торговые решения и повышать устойчивость моделей в условиях финансовых рынков.
Parabolic Stop-and-Reversal (SAR) - это индикатор точек подтверждения и окончания тренда. Поскольку он отстает в определении трендов, его основной целью было позиционирование скользящих стоп-лоссов по открытым позициям. Мы рассмотрим, можно ли его использовать в качестве сигнала советника с помощью пользовательских классов сигналов советников, собранных с помощью Мастера.
Пошаговое руководство по автоматической оптимизации на MQL5 для советников. Мы рассмотрим надежную логику оптимизации, лучшие практики по выбору параметров, а также как реконструировать стратегии с помощью бэк-тестирования. Кроме того, будут рассмотрены методы более высокого уровня, такие как пошаговая форвард-оптимизация, которые улучшат ваш подход к трейдингу.
Мы добавим Глубокое обучение к тем трем примерам, которые были опубликованы в предыдущих статьях, и сравним результаты с предыдущими. Цель состоит в том, чтобы научиться каким образом добавлять Глубокое обучение (DL) в другие советники.
RSI — популярный импульсный осциллятор, который измеряет темп и размер недавнего изменения цены ценной бумаги для оценки ситуаций переоценки или недооценки ее цены. Эти знания о скорости и масштабах имеют ключевое значение для определения точек разворота. Мы применим этот осциллятор в работе очередного пользовательского класса сигналов и изучим особенности некоторых из его сигналов. Однако начнем мы с того, что подведем итог нашему разговору о полосах Боллинджера.
Статья разбирает алгоритм Battle Royale Optimizer — метаэвристику, в которой решения конкурируют с ближайшими соседями, накапливают “повреждения”, заменяются при превышении порога и периодически сужают пространство поиска вокруг лучшего. Показаны псевдокод и реализация класса CAOBRO в MQL5, включая поиск соседей, движение к лучшему и адаптивный интервал delta. Результаты тестов на функциях Hilly, Forest и Megacity демонстрируют сильные и слабые стороны подхода. Читатель получает готовую основу для экспериментов и настройки popSize и maxDamage.
В этой статье мы научимся создавать и настраивать объекты графиков в MQL5, используя текущие и исторические данные. Здесь также представлено практическое руководство, с которым вы сможете отображать сделки на графике и использовать другие объекты MQL5 на практике.
В статье рассматривается практическая реализация фреймворка HiSSD в задачах алгоритмического трейдинга. Показано, как иерархия навыков и адаптивная архитектура могут быть использованы для построения устойчивых торговых стратегий.
Помните советник Ilan 1.6 Dymanic? Попробуем улучшить его с помощью машинного обучения! Реанимируем старую разработку в статье и добавляем машинное обучение с Q-таблицей. По шагам.
В настоящей статье рассматривается алгоритм отбора признаков, представленный в статье "Выбор локальных признаков для классификации данных» ('Local Feature Selection for Data Classification') Наргеса Арманфарда и соавторов (Narges Armanfard et al.). Алгоритм реализован на Python для построения моделей бинарных классификаторов, которые могут быть интегрированы с приложениями MetaTrader 5 для логического вывода.
В данной статье рассматривается подход к торговле только в выбранном направлении (на покупку или на продажу). Для этого используется техника причинно-следственного вывода и машинное обучение.
Полосы Боллинджера — очень распространенный индикатор конвертов, используемый многими трейдерами для ручного размещения и закрытия сделок. Мы изучим этот индикатор, рассмотрев как можно больше различных сигналов, которые он генерирует, и посмотрим, как их можно использовать в советнике, собранном с помощью Мастера.
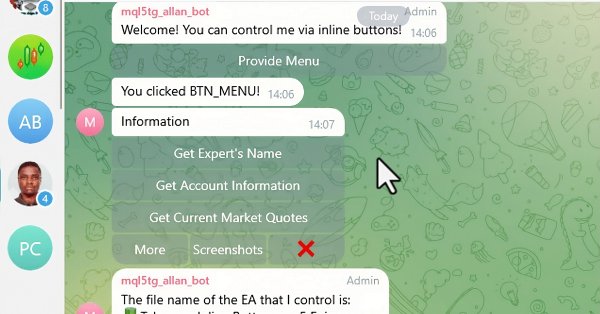
В этой статье мы интегрируем интерактивные встроенные кнопки в MQL5-советник, что позволяет осуществлять управление в режиме реального времени через Telegram. Каждое нажатие кнопки запускает определенные действия и отправляет ответы обратно пользователю. Мы также создадим функции для эффективной обработки Telegram-сообщений и callback-запросов.
Предлагаем познакомиться с фреймворком HiSSD, который объединяет иерархическое обучение и мультиагентные подходы для создания адаптивных систем. В этой работе мы подробно рассмотрим, как этот инновационный подход помогает выявлять скрытые закономерности на финансовых рынках и оптимизировать стратегии торговли в условиях децентрализации.
В процессе работы над проектами в MetaEditor разработчики сталкиваются с необходимостью управления версиями кода. Недавно начался переход на GIT и запуск MQL5 Algo Forge для версионного хранения кода и возможности совместной разработки. В статье рассматриваются способы эффективной работы с текущими инструментами.
Настоящая статья является началом серии разработок для библиотеки под названием “Connexus”, предназначенной для облегчения выполнения HTTP-запросов с помощью MQL5. Цель настоящего проекта - предоставить конечному пользователю такую возможность и показать, как использовать эту вспомогательную библиотеку. Я намеревался сделать его как можно более простым, чтобы облегчить изучение и обеспечить возможность для будущих разработок.
В статье рассмотрим процесс разработки модели таблицы на языке MQL5 с использованием архитектурной концепции MVC (Model-View-Controller) для разделения логики данных, представления и управления, что помогает создавать структурированный, гибкий и масштабируемый код. Рассмотрим реализацию классов для построения модели таблицы, включая использование связанных списков для хранения данных.
В настоящей статье улучшим оперативность работы панели администратора, созданную нами ранее. Кроме того, мы рассмотрим важность быстрого обмена сообщениями в контексте торговых сигналов.
Новый авторский алгоритм оптимизации NOA2 (Neuroboids Optimization Algorithm 2), объединяет принципы роевого интеллекта с нейронным управлением. NOA2 сочетает механику поведения стаи нейробоидов с адаптивной нейронной системой, позволяющей агентам самостоятельно корректировать свое поведение в процессе поиска оптимума. Алгоритм находится на стадии активной разработки и демонстрирует потенциал для решения сложных задач оптимизации.
Продолжаем работу над имплементацией подходов фреймворка CATCH, который объединяет преобразование Фурье и механизм частотного патчинга, обеспечивая точное выявление рыночных аномалий. В этой работе мы завершаем реализацию собственного видения предложенных подходов и проведем тестирование новых моделей на реальных исторических данных.
В данной статье предложен оригинальный подход к разработке трендовых стратегий. Вы узнаете, как можно делать разметку обучающих примеров и обучать на них классификаторы. На выходе получатся готовые торговые системы, работающие под управлением терминала MetaTrader 5.
Хотите узнать, как извлекать выгоду из разницы в процентных ставках? В статье мы посмотрим, как использовать своп-арбитраж на Форексе, чтобы каждую ночь получать стабильный доход, создавая портфель, устойчивый к рыночным колебаниям.