Индикатор ZigZag дополняется количественной оценкой длин волн: для восходящих и нисходящих движений считаются текущая длина, максимум, минимум, среднее и медиана, обновляемые на каждом новом баре. Разбираются ключевые элементы реализации: поиск экстремумов в скользящем окне, конечный автомат пивотов, инкрементальный пересчёт и отключение визуального слоя в тестере. Практическая польза — объективные численные ориентиры вместо визуальной оценки на глаз.
Рассматриваем альтернативу нейросетевым фильтрам сигналов: ассоциативные правила и базовую теорию вероятностей в MQL5, без Python и внешних библиотек. Показано, как дискретизировать рыночные условия (RSI, EMA, ATR, импульс, сессия), собрать статистику по support, confidence, lift и edge с сглаживанием Лапласа и применять результат как прозрачный входной фильтр перед сделкой.
Статья описывает переход к многосценарному прогнозу на базе ORION: создаётся кодовая книга рыночных прототипов с EMA-памятью и слой, объединяющий генератор, роутер и оценку неопределённости. Такой модуль формирует траектории, их априорные вероятности и допустимый разброс, что позволяет учитывать альтернативные продолжения рынка при проектировании торговых решений.
В статье начинается адаптация фреймворка ORION к анализу финансовых рынков. Вместо единственной прогнозной траектории модель формирует несколько сценариев будущего движения, оценивает их вероятность и неопределённость. Практическая часть посвящена OpenCL-кернелам для генерации сценариев, расчёта ответственности и подготовки обучающих сигналов для роутера, генератора и блока неопределённости.
Лучше всего здесь работает сочетание вариантов 2 и 4: оно сохраняет техническую точность, не обещает доходность и сразу показывает практический смысл архитектуры. В статье завершается адаптация фреймворка CogDriver к анализу финансовых рынков. Представление рыночной сцены, временная память, прогнозный план и оценка ожидаемой ошибки объединяются в единый торговый контур, при этом прогнозирование отделено от принятия решений. Рассматриваются построение моделей, организация обучения и проверка архитектуры в тестере стратегий MetaTrader 5 с акцентом на снижение избыточной реактивности и дрожания торговых решений.
Статья посвящена бактериальному эволюционному алгоритму Нава — Фурухаси (BEA) и его двум ключевым операторам: посегментной бактериальной мутации для локальной оптимизации и горизонтальному переносу генов для обмена удачными фрагментами решений. Мы реализуем BEA в каркасе C_AO как конечный автомат под фиксированный бюджет оценок, тестируем на Hilly, Forest и Megacity и поясняем терминологическую развилку с моделью Нумаоки.
В статье рассматриваются теоретические основы и практическая реализация модели смеси нормальных распределений (Gaussian Mixture Model) на языке MQL5. Представлен класс CGMM и примеры его использования, а также методология выбора оптимального количества компонентов модели с помощью информационных критериев AIC/BIC. Значительное внимание уделяется принципу работы EM-алгоритма — признанного стандарта при обучении вероятностных моделей со скрытыми(латентными) переменными. Реализована поддержка режима обучения MAP и инициализация параметров с помощью K-Means++. Готовый инструмент для кластеризации, оценки многомерной плотности и генерации данных теперь доступен и в MetaTrader 5.
В статье продолжается адаптация фреймворка CogDriver к анализу финансовых рынков. После построения рыночной сцены и временно согласованной памяти переходим к созданию Forecast Head — модуля прогнозирования. Рассматривается механизм рекуррентного уточнения прогноза, сочетание Cross- и Self-Attention, проблема позиционного кодирования и диагностические признаки, помогающие оценивать устойчивость будущей торговой гипотезы.
Статья показывает, как перенести MLP-фильтр советника GridSurvivor из офлайн-обучения в Python в полностью встроенное обучение в MQL5. Сеть тренируется на истории текущего символа и таймфрейма, периодически переобучается и используется как последний фильтр сигналов. Подход исключает внешние файлы и рассинхрон нормализации, делая советник самодостаточным и воспроизводимым.
Третья статья серии вводит обучаемый граф признаков в архитектуре Cellular10K: веса связей feature → feature онлайн усиливаются после верных прогнозов и ослабляются после ошибок. Разбираются мягкая инициализация, шаг message passing, локальное правило обучения в стиле Хебба, ограничение весов, нормировка и decay. Показана интеграция с клеточным автоматом и бинарным предиктором, а также метрики диагностики и практические пороги запуска для контроля переобучения.
В статье продолжается адаптация фреймворка CogDriver к финансовым временным рядам. Основное внимание уделено модулю временной согласованности TCM, который связывает текущее рыночное состояние с памятью ранее сохранённых запросов (Query). Разбираются ранжируемая память, расчёт оценки (Score) через Flash-Attention, обновление слотов памяти средствами OpenCL и построение слоя CNeuronCogDriverRankTCM в MQL5, что даёт готовый контур временной согласованности для последующих торговых моделей.
Алгоритм оптимизации шимпанзе (ChOA) подражает групповой охоте приматов с разделением ролей, а его бинарная ветвь BChimp переносит эту механику в задачи отбора признаков. Реализуем непрерывное ядро в C_AO, по пути находим и исправляем унаследованный дефект коэффициента — незаметный за бинаризацией, но разрушающий поиск в непрерывной области. Аннотация даёт готовую реализацию и практические выводы о качестве и устойчивости поиска.
Во второй части клеточный автомат переводится с решётки на граф. Признаки становятся вершинами графа с локальными и дальними small‑world связями, а клетки — агентами, которые взаимодействуют не только с геометрическими, но и со смысловыми соседями. Рассматриваются графовая фильтрация признаков, построение графа соседей, обновлённое голосование по согласованности и метрики Graph Coherence и Graph Health. Это снижает влияние одиночных выбросов и ускоряет распространение рыночных режимов при полной совместимости с MQL5.
Классический SuperTrend теряет точность при смене рыночного режима из‑за фиксированных ATR и множителя. В статье разобрана архитектура ML SuperTrend Pro v2.00 на чистом MQL5: фоновый тест‑матрикс с адаптивным обновлением параметров, режимная сетка как детектор контекста, слой точности из пяти фильтров и Parabolic‑стиль с продуманными буферами. Показаны принципы L1‑регуляризации, результаты сравнения с классическим SuperTrend и практические рекомендации по запуску и интеграции через iCustom.
В статье показана адаптация фреймворка CogDriver из автономного вождения к анализу финансовых рынков с упором на когнитивную инерцию и временную согласованность решений. Разбирается удержание рыночной гипотезы и её проверка на новых данных для снижения дрожания сигналов. Практический раздел вводит класс CNeuronCogDriverData, который нормализует признаки, накапливает стек состояний и формирует MarketStateDensity-представления как фундамент дальнейшего планирования.
Продолжается адаптация MomAD к алгоритмическому трейдингу: собран класс CNeuronMomAD, объединяющий UncAD с модулями согласования и уточнения сценариев (TTM, MPI). Разобраны этапы последовательного обучения модели и тестирование на EURUSD H1 за январь–апрель 2026 года. Статья фокусируется на интеграции в общий вычислительный контур и практических выводах по управлению риском при положительном результате.
Представляем MQL5-реализацию Coyote Optimization Algorithm: стаи с локальными альфами, медианная тенденция и встроенный кроссовер обеспечивают параллельное исследование областей пространства и контроль преждевременной сходимости. Алгоритм встроен в C_AO и проверен на стандартном стенде и композитном античит-тесте. В статье — код, псевдокод и разбор операторов, позволяющие применить COA для оптимизации параметров торговой системы.
MetaTrader 5 подходит для ИИ-торговли, потому что объединяет рыночные данные, MQL5-разработку, Python-исследования, ONNX-модели, Strategy Tester, VPS и экосистему MQL5.community в одном рабочем процессе. Статья показывает практический путь от AI-подсказки на графике к структурированному сигналу, работе с кодом через AI Assistant в MetaEditor, модели качества, созданию советнику, тестированию и контролируемому запуску торговой системы.
В статье представлена практическая реализация ключевых модулей архитектуры MomAD, адаптированных для финансовых временных рядов: TTM и MPI. Рассмотрены механизмы сопоставления сценариев-кандидатов с историей решений, выбора согласованного торгового плана и его уточнения через рыночный контекст. Работа показывает, как модель может снижать реакцию на шум, сохранять преемственность решений и формировать более устойчивую торговую гипотезу.
Описываем и реализуем CVO: заражение как генерация кандидатов, покоординатное нормальное возмущение, динамическая популяция. Алгоритм интегрирован в C_AO и проверен на стандартном бенчмарке. Разбор выявляет масштабную причину стагнации и даёт прикладное решение — переход к относительному шагу по ширине диапазона; код готов к использованию.
В статье представлен конвейер вложенной кросс-валидации V-in-V для финансовых данных, который устраняет утечку информации в трех точках принятия решений: подбор гиперпараметров, калибровка и итоговая оценка. Временное разделение на три зоны изолирует внутренний walk-forward поиск с правилом 1-SE от внешней walk-forward или CPCV-оценки, а изотоническая OOF (out-of-fold) калибровка обучается независимо. Итоговый UnifiedValidationCalibrator дает несмещенные оценки на вневыборочных данных и хорошо откалиброванные вероятности для продакшена.
В продолжение нашей предыдущей статьи о паре индикаторов Awesome Oscillator и каналов конвертов (Envelope Channels), мы рассмотрим, как эту пару можно улучшить с помощью обучения с учителем. Awesome Oscillator и канал конвертов — это взаимодополняющее сочетание инструментов, позволяющих выявлять тренды и создавать уровни поддержки/сопротивления. Наш подход к обучению с учителем представляет собой сверточную нейронную сеть (CNN), которая использует ядро скалярного произведения (Dot Product Kernel) с механизмом внимания во времени (Cross-Time-Attention) для определения размеров своих ядер и каналов. Как обычно, это делается в пользовательском файле класса сигналов (signal class), который взаимодействует с Мастером MQL5 для сборки советника.
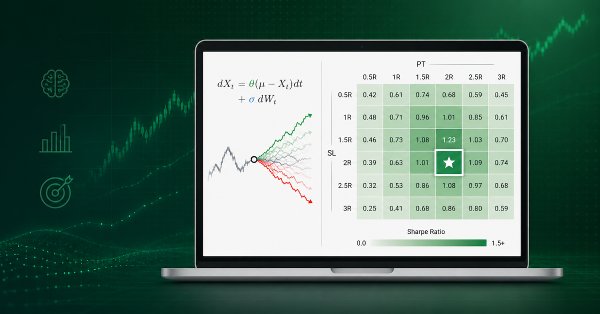
В статье применяется оптимальное торговое правило из главы 13 AFML для задания уровней тейк-профита и стоп-лосса без внутривыборочной калибровки. Мы моделируем P&L после входа дискретным процессом Орнштейна–Уленбека, выполняем поиск по 100 000 траекториям и используем Python, multiprocessing и параллельное ядро Numba с декоратором @njit (в 242 раза быстрее). Результат — оптимальная пара (PT, SL) для трех спецификаций прогноза с учетом дневного лимита убытков, установленного проп-фирмой.
В статье рассматривается адаптация идей MomAD к задачам нейросетевого трейдинга. Основное внимание уделено проблеме нестабильности торговых решений, когда модель слишком часто меняет сценарий и разрушает прибыльный план. Описаны теоретические основы Momentum-Aware Planning, расстояния Хаусдорфа и их перенос в латентное пространство рыночных состояний. В практической части реализован базовый OpenCL-механизм оценки расхождения между сценариями.
В этой статье представлена готовая к промышленному применению реализация дробного дифференцирования с фиксированной шириной окна на MQL5 для потоков котировок MetaTrader 5 в реальном времени. Мы вводим header-only класс CFFDEngine, целиком реализованный в заголовочном файле, который заранее вычисляет веса без фиксированного ограничения, выполняет обновления за O(width) на бар и избегает выделения памяти на каждом тике. Индикатор FFD.mq5 поддерживает все типы ENUM_APPLIED_PRICE и оптимизацию prev_calculated. Скрипты валидации подтверждают численную эквивалентность стандартному Python-пайплайну frac_diff_ffd.
В MQL5 отсутствует встроенная асимметричная криптография, из-за чего безопасный обмен данными по незащищённым каналам вроде HTTP становится затруднительным. В этой статье представлена чистая реализация RSA на MQL5 с использованием схемы дополнения PKCS#1 v1.5, позволяющая безопасно передавать сеансовые ключи для AES и небольшие блоки данных без внешних библиотек. Такой подход обеспечивает уровень безопасности, похожий на HTTPS, поверх обычного HTTP и, более того, закрывает важный пробел в защищённой коммуникации для приложений MQL5.
Статья описывает TradeMux как мост между Python-пайплайном и терминалом MetaTrader 5 для чистой передачи торговых решений без дублирования логики. Разобрана production-архитектура из четырёх слоёв и полный Python execution service: подключение, чтение счёта и позиций, генерация сигналов (включая CatBoost), предторговый риск-контроль, kill_switch и supervisor. Практическая польза — кросс-брокерная нормализация (RoboForex, IC Markets, Alpari, OANDA) и масштабирование от одного счёта к мультисчётному broadcast без изменения торговой логики.
В статье мы доводим адаптацию фреймворка UncAD до цельной торговой архитектуры. Ранее реализованные блоки плотности рыночных состояний, оценки неопределённости, прогнозирования и планирования объединяются в модуль CNeuronUncAD. Затем система обучается на исторических данных EURUSD H1 и проходит проверку в MetaTrader 5. Итоги показывают практический потенциал подхода, но честно указывают на главный вызов — контроль просадки и усиление риск-менеджмента.
В этой статье демонстрируется, как стохастический осциллятор (классический технический индикатор) можно использовать не только как инструмент торговли на возврате к среднему. Рассматривая индикатор с другой аналитической точки зрения, мы показываем, как знакомые стратегии могут раскрыть новую практическую ценность и лечь в основу альтернативных торговых правил, включая интерпретации следования за трендом. В конечном счете, в статье рассказывается о том, как каждый технический индикатор в терминале MetaTrader 5 содержит скрытый потенциал и как вдумчивый подход методом проб и ошибок позволяет выявить содержательные интерпретации, которые не лежат на поверхности.
Кандидат в нашу рейтинговую таблицу — Beluga Whale Optimization, метаэвристика, построенная на трёх моделях поведения кита-белухи: парном плавании, охоте с полётом Леви и обновлении популяции через падение кита. По ходу реализации обнаружилось, что алгоритм не столько оптимизирует, сколько считывает геометрию тестового стенда, разбираем механизм этого и собираем честную перспективную модификацию BWOm.
Статья продолжает адаптацию фреймворка UncAD к алгоритмическому трейдингу и фокусируется на модулях прогнозирования и планирования. Унитарные рыночные ряды заменяют участников сцены, а состояние счёта играет роль ego-агента. Реализованы CNeuronUncADUGP и CNeuronUncADUGPL, которые связывают прогноз, карту рыночных состояний и неопределённость с торговым контекстом, чтобы формировать согласованные сценарии и подготавливать решения по входу, удержанию и снижению риска.
Эта статья помогает новым участникам сообщества искать и находить собственные свечные паттерны. Описание этих паттернов может оказаться сложной задачей, поскольку требует ручного поиска и творческого подхода к выявлению усовершенствований. В этой статье мы представляем свечной паттерн поглощения и показываем, как его можно усовершенствовать для создания более прибыльных торговых стратегий.
В этом обсуждении мы сосредоточимся на том, как можно преодолеть "стеклянный потолок", создаваемый классическими методами машинного обучения в сфере финансов. Похоже, что самое главное ограничение ценности, которую можно извлечь из статистических моделей, заключается не в самих моделях — ни в данных, ни в сложности алгоритмов, — а скорее в методологии, которую мы используем для их применения. Другими словами, истинным узким местом может быть то, как мы используем модель, а не ее собственный потенциал.
В статье подробно рассматриваются теоретические основы и практическая реализация скрытой марковской модели с категориальными эмиссиями (Categorical HMM) на языке MQL5. На конкретных примерах демонстрируются процессы инференса, итерационного обучения параметров, онлайн-фильтрации, а также методология выбора оптимальной архитектуры модели по информационным критериям AIC/BIC.
Разбирается практическое применение L1 Trend Filter для очистки шума и формирования структурных признаков, совместимых с live-торговлей. Показан полный цикл: H1-данные 29 инструментов из MetaTrader 5, каузальная фильтрация, CatBoost на горизонте трёх L1-баров, честный walk-forward и распределение лотов по VaR. Читатель получает воспроизводимый кодовый конвейер и методику портфельной оценки.
Индикатор показателя Хёрста для MQL5 реализован на основе R/S-анализа с OLS-регрессией в log-log пространстве. Теоретическая опора — результаты Gatheral–Jaisson–Rosenbaum (2014), согласно которым волатильность — дробное броуновское движение с H ≈ 0.10. Индикатор оценивает H в скользящем окне, выделяет антиперсистентный (H < 0.3), нейтральный и трендовый (H > 0.5) режимы, окрашивает линию и подаёт алерт при смене режима, помогая выбирать тип стратегии и управлять риском.
Прогнозирование временных рядов в трейдинге прошло путь от традиционных статистических моделей, таких как ARIMA, к подходам глубокого обучения, но оба варианта требуют сложной настройки и обучения. Вдохновленная достижениями NLP, модель Google TimesFM предлагает фундаментальную предобученную модель для временных рядов, способную давать сильные прогнозы даже без обучения под конкретную задачу. Для трейдеров это особенно ценно: модель можно эффективно дообучать на собственных данных с помощью легких методов вроде LoRA, снижая переобучение и одновременно адаптируясь к меняющимся рыночным условиям.
В статье продолжена адаптация фреймворка UncAD для задач алгоритмического трейдинга. Реализованы объект распределения рыночных состояний и энкодер неопределённости, формирующий совместное представление состояния рынка и степени доверия к нему. Предложенная архитектура позволяет модели учитывать не только структуру рыночного режима, но и устойчивость собственной интерпретации, что особенно важно в условиях нестационарности финансовых рынков.
Мы создаем набор инструментов промышленного уровня для расчета размера позиции в MQL5: утилиты, фрагменты кода и пользовательские функции, которые повторяют исходные реализации на Python. Методы охватывают преобразование вероятности в размер позиции с коррекцией перекрытия, динамический расчет размера позиции по прогнозной цене (калиброванные сигмоидальная и степенная функции с лимитной ценой), бюджетирование на основе текущей занятости портфеля и резервный метод расчета размера позиции на основе модели смеси (EF3M). Результат — размер позиции со знаком в диапазоне [−1, ..., 1] плюс диагностика, которую можно напрямую подключить к логике ордеров.
Целочисленное дифференцирование заставляет выбирать между стационарностью и памятью: доходности (d = 1) стационарны, но отбрасывают всю информацию об уровне цены; исходные цены (d = 0) сохраняют память, но нарушают предпосылку стационарности, важную для моделей машинного обучения. В статье реализован метод дробного дифференцирования с окном фиксированной ширины (FFD) из главы 5 AFML: get_weights_ffd — итеративная рекурсия с отсечением по порогу, frac_diff_ffd — ограниченное скалярное произведение для каждого бара, fracdiff_optimal — бинарный поиск минимального стационарного d*.