Продолжаем знакомство с инновационным фреймворком Chimera — двухмерной моделью пространства состояний, использующей нейросетевые технологии для анализа многомерных временных рядов. Этот метод обеспечивает высокую точность прогнозирования при низких вычислительных затратах.
В этой серии статей мы анализируем классические торговые стратегии с использованием современных алгоритмов, чтобы определить, можно ли улучшить стратегию с помощью искусственного интеллекта (ИИ). В сегодняшней статье мы рассмотрим классический подход к торговле индексом SP500, используя его взаимосвязь с казначейскими облигациями США (US Treasury Notes).
Откройте для себя инновационный фреймворк Chimera — двухмерную модель пространства состояний, использующую нейросети для анализа многомерных временных рядов. Этот метод предлагает высокую точность с низкими вычислительными затратами, превосходя традиционные подходы и архитектуры Transformer.
В этой статье наш советник новостной торговли начнет открывать сделки на основе экономического календаря, хранящегося в нашей базе данных. Кроме того, мы улучшим графику советника, чтобы отображать более актуальную информацию о предстоящих событиях экономического календаря.
В статье представлен продвинутый советник для торговли на рынке Форекс, сочетающий машинное обучение с техническим анализом. Он предназначен для торговли акциями Apple с использованием адаптивной оптимизации, управления рисками и множества стратегий. Тестирование на исторических данных показывает многообещающие результаты, но также и значительные просадки, что указывает на потенциал для дальнейшего совершенствования.
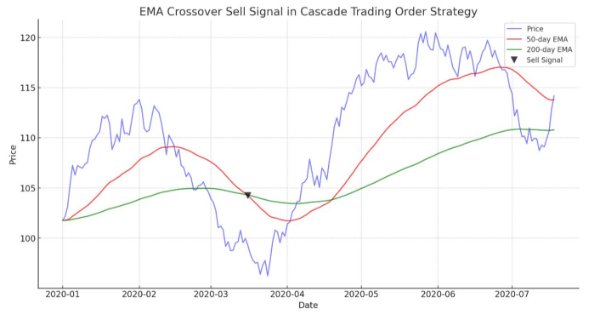
В статье представлен автоматизированный алгоритм на основе пересечений EMA для MetaTrader 5. Подробная информация обо всех аспектах демонстрации советника на языке MQL5 и его тестирования в MetaTrader 5, от анализа характеристик ценового диапазона до управления рисками.
В этой статье мы создадим MQL5-советник, интегрированный с Telegram, который отправляет в мессенджер сигналы пересечения скользящих средних. Мы подробно опишем процесс генерации торговых сигналов на основе пересечений скользящих средних, реализуем необходимый код на языке MQL5 и обеспечим бесперебойную работу интеграции. В результате мы получим систему, которая отправляет торговые оповещения в реальном времени непосредственно в групповой чат Telegram.
Продолжаем изучение фреймворка мультизадачного обучения на основе ResNeXt, который отличается модульностью, высокой вычислительной эффективностью и способностью выявлять устойчивые паттерны в данных. Использование единого энкодера и специализированных "голов" снижает риск переобучения модели и повышает качество прогнозов.
В этой статье мы создадим советник на языке MQL5, отправляющий сообщения в Telegram с помощью бота. Мы настроим необходимые параметры, включая API-токен бота и идентификатор чата, а затем выполним HTTP-запрос POST для доставки сообщений. Затем мы обработаем ответ, чтобы обеспечить успешную доставку, и устраним возможные ошибки.
Расширение панели графического интерфейса на MQL5 с помощью динамических функций может существенно улучшить торговый опыт пользователей. Благодаря включению интерактивных элементов, эффектов наведения и обновлению данных в реальном времени эта панель становится мощным инструментом современного трейдера.
Фреймворк многозадачного обучения на основе ResNeXt оптимизирует анализ финансовых данных, учитывая их высокую размерность, нелинейность и временные зависимости. Использование групповой свертки и специализированных голов позволяет модели эффективно извлекать ключевые признаки исходных данных.
Мы продолжаем построение модели иерархического двухбашенного трансформера Hidformer, который предназначен для анализа и прогнозирования сложных многомерных временных рядов. В данной статье мы доведем начатую ранее работу до логического завершения с тестированием модели на реальных исторических данных.
Предлагаем познакомиться с фреймворком иерархического двухбашенного трансформера (Hidformer), который был разработан для прогнозирования временных рядов и анализа данных. Авторы фреймворка предложили несколько улучшений к архитектуре Transformer, что позволило повысить точность прогнозов и снизить потребление вычислительных ресурсов.
Продолжаем тему анализа совершённых сделок в тестере стратегий для улучшения качества торговли. Проверим, как использование различных трейлингов поможет изменить уже полученные результаты торговли.
Концепция Smart Money (Break of Structure) в сочетании с индикатором RSI для принятия обоснованных решений в автоматической торговле на основе структуры рынка.
В статье мы эмпирически проанализируем классические торговые стратегии, чтобы увидеть, можно ли улучшить их с помощью искусственного интеллекта (ИИ). Мы попытаемся предсказать более высокие максимумы и более низкие минимумы, используя модель линейного дискриминантного анализа (Linear Discriminant Analysis).
В статье рассмотрена разработка динамической мультисимвольной мультипериодной панели индикатора RSI в MQL5. Панель призвана предоставлять трейдерам значения RSI в реальном времени по различным символам и таймфреймам. Панель будет оснащена интерактивными кнопками, обновлениями в реальном времени и цветовыми индикаторами, помогающими трейдерам принимать обоснованные решения.
Мы завершаем реализацию фреймворка MacroHFT для высокочастотной торговли криптовалютами, который использует контекстно-зависимое обучение с подкреплением и памятью для адаптации к динамичным рыночным условиям. И в завершении данной статьи будет проведено тестирование реализованных подходов, на реальных исторических данных, для оценки их эффективности.
В тестере стратегий можно не только оптимизировать параметры торгового робота. Мы покажем, как оценить постфактум проторгованную историю своего счёта и внести корректировки в торговлю в тестере, изменяя размеры стоп-приказов открываемых позиций.
Предлагаю познакомиться с фреймворком MacroHFT, который применяет контекстно зависимое обучение с подкреплением и память, для улучшения решений в высокочастотной торговле криптовалютами, используя макроэкономические данные и адаптивные агенты.
В этой статье рассматриваются частые вопросы, которые начинающие программисты задают на форуме MQL5. Также демонстрируются практические решения. Мы научимся совершать основные действия: покупку и продажу, получение цен свечей, а также управление торговыми аспектами, включая торговые лимиты, периоды и пороговые значения прибыли/убытка. В статье представлены пошаговые инструкции, которые помогут вам лучше понять и реализовать обсуждаемые концепции на MQL5.
В статье подробно рассматриваются возможности реализации советника на основе торгового алгоритма. Это поможет автоматизировать систему на MQL5 и взять под контроль дневную просадку.
Продолжаем реализацию подходов, предложенных авторами фреймворка FinCon. FinCon является многоагентной системой, основанной на больших языковых моделях (LLM). Сегодня мы реализуем необходимые модули и проведем комплексное тестирование модели на реальных исторических данных.
Представьте, что вы можете использовать данные, которых нет в MetaTrader. Обычно вы получаете информацию только от индикаторов, основанных на анализе цен и техническом анализе. Теперь представьте, что у вас есть доступ к данным, которые выведут ваши торговые возможности на новый уровень. Вы можете значительно увеличить мощность платформы MetaTrader, если объедините её возможности с результатами работы других программ, методов макроанализа и ультрасовременных инструментов через API. В этой статье мы расскажем, как использовать API, и представим полезные и ценные API-сервисы.
Предлагаем познакомиться с фреймворком FinCon, который представляет собой многоагентную систему на основе больших языковых моделей (LLM). Фреймворк использует концептуальное вербальное подкрепление для улучшения принятия решений и управления рисками, что позволяет эффективно выполнять разнообразные финансовые задачи.
В статье описываются шаги по созданию торгового советника, который извлекает выгоду из ценовых прорывов после периодов консолидации. Определяя диапазоны консолидации и устанавливая уровни прорыва, трейдеры могут автоматизировать свои торговые решения на основе этой стратегии. Советник призван обеспечить четкие точки входа и выхода, избегая ложных пробоев.
Продолжаем работу по реализации алгоритмов мультимодального агента для финансовой торговли FinAgent, предназначенного для анализа мультимодальных данных рыночной динамики и исторических торговых паттернов.
Эта статья посвящена ортогональным многочленам. Их применение может стать основой для более точного и эффективного анализа рыночной информации, благодаря чему, трейдер сможет принимать более обоснованные решения.
Предлагаем познакомиться с фреймворком мультимодального агента для финансовой торговли FinAgent, который предназначен для анализа данных разных типов, отражающих рыночную динамику и исторические торговые паттерны.
Продолжаем начатую работу по созданию фреймворка FinMem, который использует подходы многоуровневой памяти, имитирующие когнитивные процессы человека. Это позволяет модели не только эффективно обрабатывать сложные финансовые данные, но и адаптироваться к новым сигналам, значительно повышая точность и результативность инвестиционных решений в условиях динамично изменяющихся рынков.
В этой статье познакомим вас с анализом сентимента и моделями ONNX на языке Python для использования в советнике. Один скрипт запускает обученную модель ONNX из TensorFlow для прогнозов на основе глубокого обучения, а другой извлекает заголовки новостей и дает количественную оценку настроений при помощи ИИ.
Подходы многоуровневой памяти, имитирующие когнитивные процессы человека, позволяют обрабатывать сложные финансовые данные и адаптироваться к новым сигналам, что способствует повышению эффективности инвестиционных решений в условиях динамичных рынков.
В предыдущей статье мы рассмотрели теоретические основы и приступили к реализации подходов фреймворка Multitask-Stockformer, объединяющего вейвлет-преобразование и многозадачную модель Self-Attention. Продолжаем реализацию алгоритмов указанного фреймворка и оценим их эффективность на реальных исторических данных.
В статье рассматриваются основные этапы создания и реализации панели графического пользовательского интерфейса (Graphical User Interface, GUI) с помощью языка MetaQuotes Language 5 (MQL5). Пользовательские панели утилит повышают качество взаимодействия с системой при торговле, упрощая типовые задачи и визуализируя важную торговую информацию. Создавая пользовательские панели, трейдеры могут оптимизировать рабочий процесс и сэкономить время при торговых операциях.
Предлагаем познакомиться с фреймворком объединяющим вейвлет-преобразование и многозадачную модель Self-Attention, направленную на повышение отзывчивости и точности прогнозирования в условиях нестабильности рынка. Вейвлет-преобразование позволяет разложить доходность активов на высокие и низкие частоты, тщательно фиксируя долгосрочные рыночные тенденции и краткосрочные колебания.
Продолжаем рассмотрение гибридной торговой системы StockFormer, которая объединяет предиктивное кодирование и алгоритмы обучения с подкреплением для анализа финансовых временных рядов. Основой системы служат три ветви Transformer с механизмом Diversified Multi-Head Attention (DMH-Attn), позволяющим выявлять сложные паттерны и взаимосвязи между активами. Ранее мы познакомились с теоретическими аспектами фреймворка и реализовали механизмы DMH-Attn, а сегодня поговорим об архитектуре моделей и их обучении.
Как осуществляется портфельная торговля на Форекс? Как могут быть синтезированы портфельная теория Марковица для оптимизации пропорций портфеля и VaR модель для оптимизации риска портфеля? Создаем код по портфельной теории, где, с одной стороны, получим низкий риск, а с другой — приемлемую долгосрочную доходность.
Предлагаем познакомиться с гибридной торговой системой StockFormer, которая объединят предиктивное кодирование и алгоритмы обучения с подкреплением (RL). Во фреймворке используются 3 ветви Transformer с интегрированным механизмом Diversified Multi-Head Attention (DMH-Attn), который улучшает ванильный модуль внимания за счет многоголового блока Feed-Forward, что позволяет захватывать разнообразные паттерны временных рядов в разных подпространствах.
В предыдущей статье мы познакомились с мультиагентным адаптивным фреймворком MASAAT, который использует ансамбль агентов для перекрестного анализа мультимодального временного ряда в разных масштабах представления данных. И сегодня мы доведем до логического завершения начатую ранее работу по реализации подходов данного фреймворка средствами MQL5.