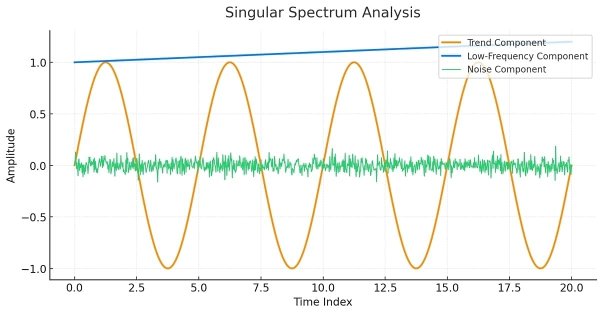
Данная статья предназначена в качестве руководства для тех, кто не знаком с концепцией сингулярного спектрального анализа и хочет получить достаточно знаний, чтобы иметь возможность применять встроенные инструменты, доступные на MQL5.
Добро пожаловать в третью часть серии статьей о трендах! Сегодня мы углубимся в использование дивергенции как стратегии определения оптимальных точек входа в рамках преобладающего дневного тренда. Мы также представим специальный механизм фиксации прибыли, аналогичный скользящему стоп-лоссу, но с уникальными усовершенствованиями. Кроме того, мы обновим советник Trend Constraint до более продвинутой версии, включив в него новое условие исполнения сделки в дополнение к существующим. Также мы продолжим изучать практическое применение MQL5 в разработке алгоритмов.
Определить направление рынка может быть просто, но вот понять, когда входить на рынок, - гораздо более сложная задача. В этой статье серии "Разработка инструментария для анализа движения цен" я представлю еще один инструмент, который определяет точки входа и уровни стоп-лосса/тейк-профита. Для достижения этой цели использовался язык программирования MQL5.
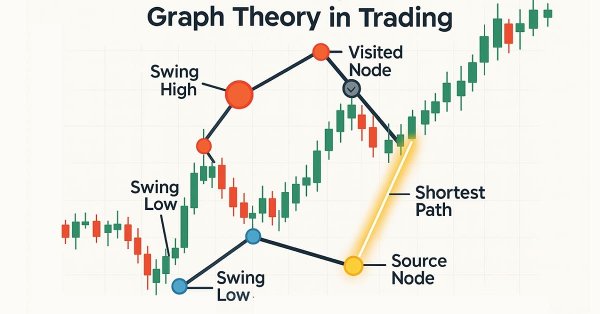
Алгоритм Дейкстры — классическое решение по поиску кратчайшего пути в теории графов, которое позволяет оптимизировать торговые стратегии путем моделирования рыночных сетей. Трейдеры могут использовать его для поиска наиболее эффективных маршрутов в данных свечного графика.
В статье подробно раскрывается SCNN-архитектура и один из вариантов её реализация средствами MQL5. Мы покажем, как декомпозиция временных рядов сочетается с нейросетевыми методами и вниманием.
Год близится к завершению, и в это время долгосрочные трейдеры часто подводят его итоги, анализируя историю рынка, его поведение и тренды с тем, чтобы оценить потенциал для будущих движений. В этой статье мы рассмотрим разработку советника для мониторинга долгосрочных сделок с помощью языка MQL5. Цель в том, чтобы справиться с такими проблемами, как упущение торговых возможностей по причине торговли вручную и отсутствия автоматизированных систем мониторинга. В качестве примера мы будем использовать одну из наиболее ярких торговых пар, чтобы эффективно определить стратегию для нашего решения и разработать его.
Предлагаем познакомиться с продолжением реализации фреймворка SCNN, который сочетает в себе гибкость и интерпретируемость, позволяя точно выделять структурные компоненты временного ряда. В статье подробно раскрываются механизмы адаптивной нормализации и внимания, что обеспечивает устойчивость модели к изменяющимся рыночным условиям.
Фреймворк MQL5, предоставляющий розничным трейдерам алгоритмы исполнения институционального уровня (TWAP, VWAP, Iceberg) с помощью унифицированного менеджера исполнения и анализатора эффективности для более плавного и точного разделения ордеров и аналитики.
В этой статье мы углубимся в добавление полезных торговых показателей в специализированное окно, интегрированное в панель администратора советника. Основное внимание уделено внедрению MQL5 для разработки аналитической панели. Подчеркивается ценность данных, которые она предоставляет администраторам. Панель в основном играет образовательную роль, позволяя извлекать из процесса разработки ценные уроки, приносящие пользу как начинающим, так и опытным разработчикам. В статье демонстрируются безграничные возможности, которые предлагает данная серия в плане предоставления передовых программных инструментов. Кроме того, мы рассмотрим реализацию классов PieChart и ChartCanvas в рамках продолжающегося расширения возможностей панели администратора.
Улучшите свой код MQL5, оптимизировав логику, улучшив вычисления и сократив время выполнения, чтобы повысить точность тестирования на истории. Проведите тонкую настройку параметров, оптимизацию циклов и устранение неэффективности для улучшения результата.
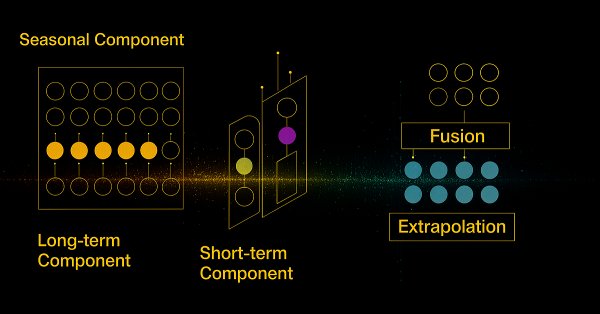
Предлагаем познакомиться с инновационным фреймворком SCNN, который выводит анализ временных рядов на новый уровень за счёт чёткого разделения данных на долгосрочные, сезонные, краткосрочные и остаточные компоненты. Такой подход значительно повышает точность прогнозирования, позволяя модели адаптироваться к сложной и меняющейся рыночной динамике.
В этой статье мы создадим кнопки для фильтров валютных пар, уровней важности, временных фильтров и функцию отмены для улучшения управления панелью. Кнопки будут запрограммированы на динамическую реакцию на действия пользователя, обеспечивая бесперебойное взаимодействие. Мы также автоматизируем их поведение, чтобы отражать изменения в реальном времени на панели. Это повысит общую функциональность, мобильность и оперативность панели.
В настоящей статье мы исследуем динамические графические интерфейсы MQL5, использующие бикубическую интерполяцию для высококачественного масштабирования изображений на торговых графиках. Мы подробно описываем гибкие варианты позиционирования, позволяющие выполнять динамическое центрирование или угловую привязку с настраиваемыми смещениями.
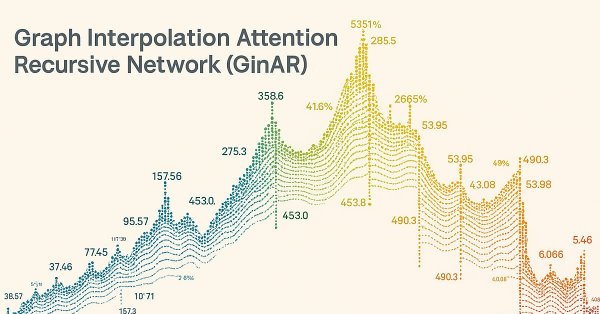
Представляем вашему вниманию заключительную часть цикла, посвящённого GinAR — нейросетевому фреймворку для прогнозирования временных рядов. В этой статье мы анализируем результаты тестирования модели на новых данных и оцениваем её устойчивость в условиях реального рынка.
Мы выходим за рамки простого просмотра проанализированных показателей на графиках и переходим к более широкой перспективе, которая включает интеграцию с Telegram. Это позволит отправлять важные результаты непосредственно на мобильное устройство через Telegram.
В данной статье подробно описывается разработка пользовательской динамически подключаемой библиотеки, предназначенной для упрощения асинхронных клиентских соединений по протоколу WebSocket для программ MetaTrader.
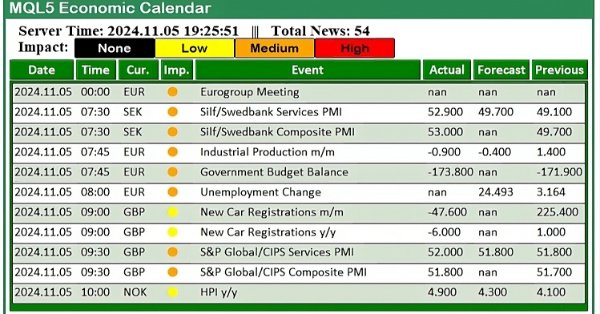
В этой статье мы расширим возможности нашей панели экономического календаря, внедрив обновления новостей в реальном времени для поддержания актуальности рыночной информации. Мы интегрируем методы извлечения данных в реальном времени в MQL5 для непрерывного обновления событий на панели управления и повышения отзывчивости интерфейса. Это обновление обеспечивает нам доступ к последним экономическим новостям непосредственно с панели управления, оптимизируя торговые решения на основе самых свежих данных.
Предлагаем познакомиться с новой реализацией ключевых компонентов Фреймворка GinAR — адаптивного алгоритма для работы с графовыми временными рядами. В статье шаг за шагом разобраны архитектура, алгоритмы прямого прохода и обратного распространения ошибки.
В этой статье мы реализуем фильтры на панели инструментов экономического календаря MQL5 для лучшего отображения новостей по валюте, важности и времени. Сначала мы установим критерии сортировки для каждой категории, а затем интегрируем их в панель управления, чтобы отображать только релевантные события. Наконец, мы обеспечим динамическое обновление каждого фильтра, чтобы предоставлять трейдерам необходимую экономическую информацию в реальном времени.
В настоящей статье мы автоматизируем обнаружение ордер-блоков на MQL5, используя чистый анализ движения цены. Мы определяем ордер-блоки , реализуем их обнаружение и интегрируем автоматическое исполнение сделок. Наконец, для оценки эффективности стратегии, мы проведём её бэк-тестирование.
Предлагаем познакомиться с инновационным подходом к прогнозированию временных рядов с пропущенными данными на базе фреймворка GinAR. В статье показана реализация ключевых компонентов на OpenCL, что обеспечивает высокую производительность. В следующей публикации мы подробно рассмотрим интеграцию этих решений в MQL5. Это позволит понять, как применять метод на практике в трейдинге.
Приглашаем вас познакомиться с фреймворком K²VAE и вариантом интеграции предложенных подходов в торговую систему. Вы узнаете, как гибридный подход Koopman–Kalman–VAE помогает строить адаптивные и интерпретируемые модели. А в завершении статьи представлены практические результаты использования реализованных решений.
Подсказки безопасности, например те, которые появляются каждый раз при обновлении графика, добавлении новой пары в чат с панелью администратора советника или перезапуске терминала, могут стать утомительными. В этом обсуждении мы рассмотрим и реализуем функцию, которая отслеживает количество попыток входа в систему для идентификации доверенного пользователя. После определенного количества неудачных попыток приложение перейдет к расширенной процедуре входа в систему, которая также облегчает восстановление пароля для пользователей, которые могли его забыть. Кроме того, мы рассмотрим, как можно эффективно интегрировать криптографию в панель администратора для повышения безопасности.
Статья представляет новый подход к созданию торговых систем на основе квантовых принципов и искусственного интеллекта. Автор описывает разработку уникальной нейронной сети, которая выходит за рамки классического машинного обучения, объединяя квантовую механику с современными архитектурами ИИ.
Предлагаем познакомиться с новым подходом, который объединяет классические методы и современные нейросети для анализа временных рядов. В статье подробно раскрыта архитектура и принципы работы модели K²VAE.
В настоящей статье мы обсудим реализацию MQL5 в партнерстве с Python для выполнения связанных с брокером операций. Представьте, что у вас есть постоянно работающий советник (EA), размещенный на VPS и совершающий сделки от вашего имени. В какой-то момент способность советника управлять средствами становится первостепенной. Она включает в себя такие операции, как пополнение вашего торгового счета и инициирование вывода средств. В данном обсуждении мы прольем свет на преимущества и практическую реализацию этих функций, обеспечивающих плавную интеграцию управления средствами в вашу торговую стратегию. Следите за обновлениями!
В этой статье мы улучшим панель управления торговлей нашей многофункциональной панели администратора. Мы представим мощную вспомогательную функцию, которая упрощает код, улучшая его читаемость, удобство обслуживания и эффективность. Мы также продемонстрируем, как легко интегрировать дополнительные кнопки и улучшить интерфейс для решения более широкого спектра торговых задач. Независимо от того, управляете ли вы позициями, корректируете ордера или упрощаете взаимодействие с пользователем, это руководство поможет вам разработать надежную и удобную панель управления торговлей.
В продолжение нашей работы по упрощению взаимодействия с поведением цены мы рады представить еще один инструмент, который может значительно улучшить ваш анализ рынка и помочь вам принимать обоснованные решения. Этот инструмент отображает ключевые технические индикаторы, такие как цены предыдущего дня, значимые уровни поддержки и сопротивления, а также торговый объем, автоматически генерируя визуальные подсказки на графике.
Предлагаем ознакомиться с оригинальной реализацией фреймворка K²VAE — гибкой модели, способной линейно аппроксимировать сложную динамику в латентном пространстве. В статье показано, как реализовать ключевые компоненты на языке MQL5, включая параметризованные матрицы и их управление вне стандартных нейросетевых слоёв. Материал будет полезен тем, кто ищет практический подход к созданию интерпретируемых моделей временных рядов.
Предлагаем погрузиться в захватывающий мир LightGTS — лёгкого, но мощного фреймворка для прогноза временных рядов, где адаптивная свёртка и RoPE‑кодирование сочетаются с инновационным методами внимания. В нашей статье вы найдёте детальное описание всех компонентов — от создания патчей до сложной смеси экспертов в декодере, готовых к интеграции в MQL5‑проекты. Откройте для себя, как LightGTS выводит автоматическую торговлю на новый уровень!
Предлагаем вам отправиться в захватывающее путешествие по миру адаптивного анализа финансовых временных рядов и узнать, как превратить сложный спектральный разбор и гибкую свёртку в реальные торговые сигналы. Вы увидите, как LightGTS слушает ритм рынка, подстраиваясь под его изменения шагом переменного окна, и как OpenCL-ускорение позволяет превратить вычисления в кратчайший путь к прибыльным решениям.
Предлагаем познакомиться с инновационной техникой адаптивного патчинга — способа гибко сегментировать временные ряды с учётом их внутренней периодичности. А также с техникой эффективного кодирования, позволяющего сохранять важные семантические характеристики при работе с данными разного масштаба. Эти методы открывают новые возможности для точной обработки сложных многомасштабных данных, характерных для финансовых рынков, и существенно повышают стабильность и обоснованность прогнозов.
В статье рассматривается разработка квантовой торговой системы - от прототипа на Python к реализации на MQL5 для реальной торговли. Система использует принципы квантовых вычислений, такие как суперпозиция и запутанность, для анализа состояний рынка, хотя она работает на классических компьютерах с использованием квантовых симуляторов. Ключевые особенности включают трехкубитную систему для одновременного анализа восьми состояний рынка, 24-часовые периоды ретроспективного анализа и семь технических индикаторов для анализа рынка. Хотя показатели точности могут показаться скромными, они обеспечивают существенное преимущество в сочетании с правильными стратегиями управления рисками.
В данной статье мы исследуем систему Profitunity авторства Билла Вильямса, подробно разобрав ее ключевые составляющие и уникальный подход к торговле в хаотичных условиях рынка. Мы продемонстрируем читателям реализацию системы на языке программирования MQL5, делая акцент на автоматизации ключевых индикаторов и сигналов для входа/выхода. Наконец, мы протестируем и оптимизируем стратегию, детально анализируя ее эффективность в различных рыночных сценариях.
Алгоритмическая торговая система, сочетающая анализ объема с методами машинного обучения, в частности с нейронными сетями LSTM. В отличие от традиционных торговых подходов, которые в первую очередь фокусируются на движении цен, эта система делает упор на паттернах объема и их производных для прогнозирования движений рынка. Методология включает в себя три основных компонента: анализ производных от объема (первые и вторые производные), прогнозы LSTM для паттернов объема и традиционные технические индикаторы.
В этой статье мы создадим практичную новостную панель с использованием экономического календаря MQL5 для улучшения нашей торговой стратегии. Начнем с проектирования макета, уделив особое внимание ключевым элементам, таким как названия событий, важность и время, а затем перейдем к настройке в MQL5. Наконец, мы внедрим систему сортировки для отображения только самых актуальных новостей, предоставляя трейдерам быстрый доступ к важным экономическим событиям.
Эта статья увлекательно покажет, как SwiGLU‑эмбеддинг раскрывает скрытые паттерны рынка, а разреженная смесь экспертов внутри Decoder‑Only Transformer делает прогнозы точнее при разумных вычислительных затратах. Мы подробно разбираем интеграцию Time‑MoE в MQL5 и OpenCL, шаг за шагом описываем настройку и обучение модели.
В этой статье мы детально рассмотрим класс управления сделками, включив в него ордера buy stop и sell stop для торговли новостными событиями, а также введем ограничение срока действия этих ордеров, чтобы предотвратить переносы торговли на следующий день. В советник будет встроена функция проскальзывания, которая попытается предотвратить или минимизировать возможное проскальзывание, которое может возникнуть при использовании стоп-ордеров в торговле, особенно во время выхода новостей.
Предлагаем познакомиться с практической реализацией блока разреженной смеси экспертов для временных рядов в вычислительной среде OpenCL. В статье шаг за шагом разбирается работа маскированной многооконной свёртки, а также организация градиентного обучения в условиях множественных информационных потоков.
Роль администратора выходит за рамки простого общения в Telegram; он также может заниматься различными видами контроля, включая управление ордерами, отслеживание позиций и настройку интерфейса. В этой статье мы поделимся практическими советами по расширению нашей программы для поддержки множества функций в MQL5. Это обновление направлено на преодоление ограничений текущей панели администратора, которая в первую очередь сосредоточена на общении.