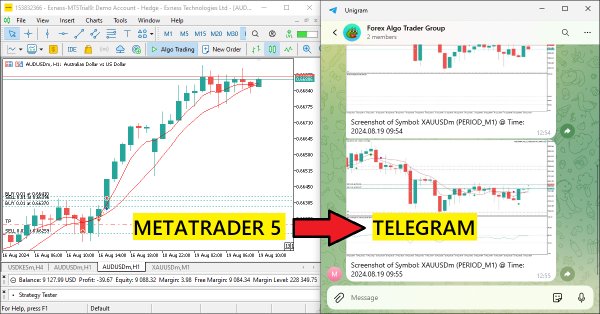
Dieses Projekt erforscht die Verschmelzung von Deep Learning und technischer Analyse, um Handelsstrategien im Forex-Bereich zu testen. Für schnelle Experimente wird ein Python-Skript verwendet, das ein ONNX-Modell neben traditionellen Indikatoren wie PSAR, SMA und RSI einsetzt, um die Entwicklung des EUR/USD vorherzusagen. Ein MetaTrader 5-Skript bringt diese Strategie dann in eine Live-Umgebung und nutzt historische Daten und technische Analysen, um fundierte Handelsentscheidungen zu treffen. Die Backtesting-Ergebnisse deuten auf einen vorsichtigen, aber konsequenten Ansatz hin, bei dem der Schwerpunkt eher auf Risikomanagement und stetigem Wachstum als auf aggressivem Gewinnstreben liegt.
Bollinger Bänder sind ein sehr gebräuchlicher Hüllkurven-Indikator, der von vielen Händlern verwendet wird, um Trades manuell zu platzieren und zu schließen. Wir untersuchen diesen Indikator, indem wir möglichst viele der verschiedenen möglichen Signale betrachten, die er erzeugt, und sehen, wie sie in einem von einem Assistenten zusammengestellten Expert Advisor verwendet werden können.
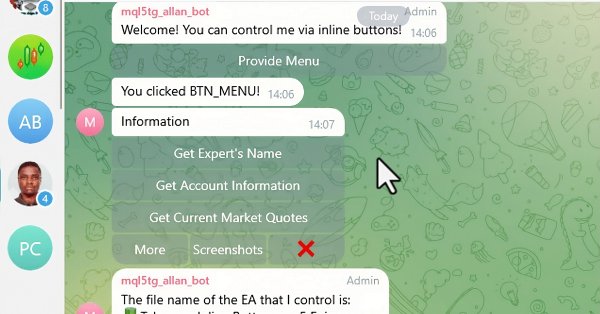
In diesem Artikel integrieren wir interaktive Inline-Buttons in einen MQL5 Expert Advisor, die eine Echtzeitsteuerung über Telegram ermöglichen. Jeder Tastendruck löst bestimmte Aktionen aus und sendet Antworten an den Nutzer zurück. Außerdem modularisieren wir Funktionen zur effizienten Handhabung von Telegram-Nachrichten und Callback-Abfragen.
Wir werden Deep Learning zu den drei Beispielen hinzufügen, die in früheren Artikeln veröffentlicht wurden, und die Ergebnisse mit den vorherigen vergleichen. Das Ziel ist es, zu lernen, wie man DL zu anderen EAs hinzufügt.
In dieser Artikelserie untersuchen wir beliebte Handelsstrategien und versuchen, sie mithilfe von KI zu verbessern. Im heutigen Artikel greifen wir die klassische Handelsstrategie wieder auf, die auf der Beziehung zwischen dem Aktien- und dem Anleihemarkt basiert.
In dieser Artikelserie erörtern wir, wie wir Expert Advisors entwickeln können, die sich selbständig an dynamische Marktbedingungen anpassen. Im heutigen Artikel werden wir versuchen, ein tiefes neuronales Netz auf die synthetischen Märkte von Derivativen abzustimmen.
Dieser Artikel ist der Beginn einer Reihe von Entwicklungen für eine Bibliothek namens „Connexus“, die HTTP-Anfragen mit MQL5 erleichtern soll. Das Ziel dieses Projekts ist es, dem Endnutzer diese Möglichkeit zu bieten und zu zeigen, wie man diese Hilfsbibliothek verwendet. Ich wollte sie so einfach wie möglich gestalten, um das Studium zu erleichtern und die Möglichkeit für künftige Entwicklungen zu schaffen.
In diesem Artikel erstellen wir mehrere Klassen, um die Echtzeitkommunikation zwischen MQL5 und Telegram zu erleichtern. Wir konzentrieren uns darauf, Befehle von Telegram abzurufen, sie zu entschlüsseln und zu interpretieren und entsprechende Antworten zurückzusenden. Am Ende stellen wir sicher, dass diese Interaktionen effektiv getestet werden und in der Handelsumgebung funktionieren.
Lernen Sie, wie Sie Chart-Objekte in MQL5 mit aktuellen und historischen Daten erstellen und anpassen. Dieser projektbasierte Leitfaden hilft Ihnen bei der Visualisierung von Handelsgeschäften und der praktischen Anwendung von MQL5-Konzepten, was die Erstellung von Tools, die auf Ihre Handelsanforderungen zugeschnitten sind, erleichtert.
In diesem Artikel werden wir die Reaktionsfähigkeit des Admin Panels verbessern, das wir zuvor erstellt haben. Darüber hinaus werden wir die Bedeutung der schnellen Nachrichtenübermittlung im Zusammenhang mit Handelssignalen untersuchen.
In diesem Artikel werden wir uns auf die visuelle Gestaltung der grafischen Nutzeroberfläche (GUI) unseres Trading Administrator Panels mit MQL5 konzentrieren. Wir werden verschiedene in MQL5 verfügbare Techniken und Funktionen erkunden, die eine Anpassung und Optimierung der Schnittstelle ermöglichen, um sicherzustellen, dass sie den Bedürfnissen der Händler entspricht und gleichzeitig eine attraktive Ästhetik beibehält.
Dieser Expert Advisor mit dem Namen SMOC (steht für Stochastic Model Optimal Control) ist ein einfaches Beispiel für ein fortschrittliches algorithmisches Handelssystem für MetaTrader 5. Es verwendet eine Kombination aus technischen Indikatoren, modellprädiktiver Steuerung und dynamischem Risikomanagement, um Handelsentscheidungen zu treffen. Der EA verfügt über adaptive Parameter, volatilitätsbasierte Positionsgrößen und Trendanalysen, um seine Leistung unter verschiedenen Marktbedingungen zu optimieren.
Die künstliche, kooperative Suche (Artificial Cooperative Search, ACS) ist eine innovative Methode, bei der eine binäre Matrix und mehrere dynamische Populationen auf der Grundlage von wechselseitigen Beziehungen und Kooperation verwendet werden, um schnell und genau optimale Lösungen zu finden. Der einzigartige Ansatz von ACS in Bezug auf Räuber und Beute ermöglicht es, hervorragende Ergebnisse bei numerischen Optimierungsproblemen zu erzielen.
Durch die Untersuchung der FEDformer-Methode haben wir die Tür zum Frequenzbereich der Zeitreihendarstellung geöffnet. In diesem neuen Artikel werden wir das begonnene Thema fortsetzen. Wir werden uns mit einer Methode befassen, mit der wir nicht nur eine Analyse durchführen, sondern auch spätere Zustände in einem bestimmten Bereich vorhersagen können.
In diesem Artikel werden wir von Grund auf ein Skript zur einfachen Visualisierung von Handelsgeschäften (deals) für die nachträgliche Analyse von Handelsentscheidungen schreiben. Alle notwendigen Informationen über ein einzelnes Geschäft sollen bequem auf dem Chart angezeigt werden, wobei verschiedene Zeitrahmen gezeichnet werden können.
In diesem Artikel wird die Vererbung in unseren bisherigen und neuen Code eingeführt. Um die Effizienz zu erhöhen, wird ein neues Datenbankdesign eingeführt. Darüber hinaus wird eine Risikomanagementklasse eingerichtet, die sich mit der Berechnung des Volumens befasst.
In diesem Artikel werden wir einen kurzen Blick auf einige Methoden werfen, um eine Funktion zu erhalten, die unsere Daten in der Datenbank darstellen kann. Ich werde nicht im Detail darauf eingehen, wie man Statistiken und Wahrscheinlichkeitsstudien zur Interpretation der Ergebnisse verwendet. Überlassen wir das denjenigen, die sich wirklich mit der mathematischen Seite der Angelegenheit befassen wollen. Die Erforschung dieser Fragen wird entscheidend sein für das Verständnis dessen, was bei der Untersuchung neuronaler Netze eine Rolle spielt. Hier werden wir dieses Thema in aller Ruhe besprechen.
In dem EA, der hier entwickelt wird, haben wir bereits einen bestimmten Mechanismus zur Kontrolle des Drawdowns. Sie ist jedoch probabilistischer Natur, da sie auf den Ergebnissen von Tests mit historischen Preisdaten beruht. Daher kann der Drawdown manchmal die maximal erwarteten Werte übersteigen (wenn auch mit einer geringen Wahrscheinlichkeit). Versuchen wir, einen Mechanismus hinzuzufügen, der die garantierte Einhaltung der festgelegten Drawdown-Höhe gewährleistet.
Alle Modelle, die wir bisher betrachtet haben, analysieren den Zustand der Umwelt als Zeitfolge. Die Zeitreihen können aber auch in Form von Häufigkeitsmerkmalen dargestellt werden. In diesem Artikel stelle ich Ihnen einen Algorithmus vor, der Frequenzkomponenten einer Zeitsequenz zur Vorhersage zukünftiger Zustände verwendet.
Wir werden das Problem der Chart-ID lösen und gleichzeitig dem Nutzer die Möglichkeit geben, eine persönliche Vorlage für die Analyse und Simulation des gewünschten Assets zu verwenden. Das hier vorgestellte Material dient ausschließlich didaktischen Zwecken und sollte in keiner Weise als Anwendung für einen anderen Zweck als das Studium und die Beherrschung der vorgestellten Konzepte betrachtet werden.
In diesem Artikel werden wir uns einige Ideen ansehen, u. a. dass mathematische Formeln im Aussehen komplexer sind als bei der Implementierung in Code. Außerdem werden wir uns damit beschäftigen, wie man einen Chart-Quadranten einrichtet, sowie mit einem interessanten Problem, das in Ihrem MQL5-Code auftreten kann. Obwohl ich, um ehrlich zu sein, immer noch nicht ganz verstehe, wie ich es erklären soll. Wie auch immer, ich zeige Ihnen, wie Sie das im Code beheben können.
Sie haben vielleicht nicht bemerkt, dass die Matrixmodellierung etwas seltsam war, da nur Spalten und nicht Zeilen und Spalten angegeben wurden. Das sieht sehr seltsam aus, wenn man den Code liest, der die Matrixfaktorisierung durchführt. Wenn Sie erwartet haben, die Zeilen und Spalten aufgelistet zu sehen, könnten Sie beim Versuch, zu faktorisieren, verwirrt werden. Außerdem ist diese Matrixmodellierungsmethode nicht die beste. Denn wenn wir Matrizen auf diese Weise modellieren, stoßen wir auf einige Einschränkungen, die uns zwingen, andere Methoden oder Funktionen zu verwenden, die nicht notwendig wären, wenn die Modellierung auf eine angemessenere Weise erfolgen würde.
Schließlich beginnt unser Indikator Chart Trade mit dem EA zu interagieren, sodass die Informationen interaktiv übertragen werden können. Daher werden wir in diesem Artikel den Indikator verbessern, sodass er funktional genug ist, um zusammen mit jedem EA verwendet zu werden. Dadurch können wir auf den Indikator Chart Trade zugreifen und mit ihm arbeiten, als ob er tatsächlich mit einem EA verbunden wäre. Aber wir werden es auf eine viel interessantere Weise tun als bisher.
In diesem Artikel werden wir die Dinge ein wenig komplizierter machen. Anhand der in den vorangegangenen Artikeln gezeigten Vorgehensweise werden wir die Vorlagendatei öffnen, damit der Nutzer seine eigene Vorlage verwenden kann. Ich werde jedoch nach und nach Änderungen vornehmen, da ich auch den Indikator verfeinern werde, um die Belastung des MetaTrader 5 zu verringern.
Wir setzen die Serie von Artikeln über die Entwicklung eines Handelsroboters in Python und MQL5 fort. Heute werden wir das Problem der Auswahl und des Trainings eines Modells, das Testen desselben, die Implementierung der Kreuzvalidierung, die Rastersuche sowie das Problem des Modell-Ensembles lösen.
Reinforcement Learning ist neben dem überwachten und dem unüberwachten Lernen eine der drei Hauptrichtungen des maschinellen Lernens. Es geht also um die optimale Steuerung oder das Erlernen der besten langfristigen Strategie, die der Zielfunktion am besten entspricht. Vor diesem Hintergrund untersuchen wir die mögliche Rolle, die ein MLP für den Lernprozess eines von einem Assistenten zusammengestellten Expertenberaters spielt.
In dieser Artikelserie nehmen wir bekannte Handelsstrategien unter die Lupe, um zu sehen, ob wir sie mithilfe von KI verbessern können. Testen Sie mit uns in der heutigen Diskussion, ob es eine zuverlässige Beziehung zwischen Edelmetallen und Währungen gibt.
In diesem Artikel wird der bestehende Code für das Senden von Nachrichten und Screenshots (screenshot des Terminals) von MQL5 zu Telegram refaktorisiert, indem er in wiederverwendbare, modulare Funktionen aufgeteilt wird. Dadurch wird der Prozess rationalisiert, was eine effizientere Ausführung und eine einfachere Codeverwaltung über mehrere Instanzen hinweg ermöglicht.
Im heutigen Artikel werden wir die Beziehung zwischen zukünftigen Wechselkursen und Staatsanleihen analysieren. Anleihen gehören zu den beliebtesten Formen von festverzinslichen Wertpapieren und stehen im Mittelpunkt unserer Diskussion, bei der wir untersuchen, ob wir eine klassische Strategie mithilfe von KI verbessern können.
In diesem Artikel erstellen wir einen MQL5 Expert Advisor, der Chart-Screenshots als Bilddaten kodiert und sie über HTTP-Anfragen an einen Telegram-Chat sendet. Durch die Integration von Fotocodierung und -übertragung erweitern wir das bestehende MQL5-Telegram-System um visuelle Handelseinblicke direkt in Telegram.
Dieser Artikel enthält eine umfassende Anleitung zur Implementierung eines ausgeklügelten Handelssystems unter Verwendung der Kausalitätsnetzwerkanalyse (Causality Network Analysis, CNA) und der Vektorautoregression (VAR) in MQL5. Es deckt den theoretischen Hintergrund dieser Methoden ab, bietet detaillierte Erklärungen der Schlüsselfunktionen im Handelsalgorithmus und enthält Beispielcode für die Implementierung.
Dieser Artikel befasst sich mit der Anwendung der Spieltheorie von John Nash, insbesondere des Gleichgewichts nach Nash, im Handel. Es wird erörtert, wie Händler Python-Skripte und MetaTrader 5 nutzen können, um Marktineffizienzen mit Hilfe der Nash-Prinzipien zu identifizieren und auszunutzen. Der Artikel enthält eine Schritt-für-Schritt-Anleitung zur Umsetzung dieser Strategien, einschließlich der Verwendung von Hidden-Markov-Modellen (HMM) und statistischer Analysen, um die Handelsleistung zu verbessern.
In diesem Artikel werden wir die Handelsstrategien mit der Parabolic SAR Strategie in MQL5 automatisieren: Erstellung eines effektiven Expertenberaters. Der EA wird auf der Grundlage der vom Parabolic SAR-Indikator identifizierten Trends Trades durchführen.
Restricted Boltzmann Machines sind eine Form von neuronalen Netzen, die Mitte der 1980er Jahre entwickelt wurde, als Rechenressourcen noch unerschwinglich waren. Zu Beginn stützte es sich auf Gibbs Sampling und kontrastive Divergenz, um die Dimensionalität zu reduzieren oder die verborgenen Wahrscheinlichkeiten/Eigenschaften über die eingegebenen Trainingsdatensätze zu erfassen. Wir untersuchen, wie Backpropagation eine ähnliche Leistung erbringen kann, wenn das RBM Preise für ein prognostizierendes Multi-Layer-Perceptron „embeds“ (einbettet).
Denken wir über einen unabhängigen Expert Advisor nach. Zuvor haben wir einen indikatorbasierten Expert Advisor besprochen, der auch mit einem unabhängigen Skript zum Zeichnen der Risiko- und Ertragsgeometrie zusammenarbeitet. Heute werden wir die Architektur eines MQL5 Expert Advisors besprechen, der alle Funktionen in einem Programm integriert.
Der dynamische Multi-Pair Expert Advisor nutzt sowohl Korrelations- als auch inverse Korrelationsstrategien zur Optimierung der Handelsperformance. Durch die Analyse von Echtzeit-Marktdaten werden die Beziehungen zwischen Währungspaaren identifiziert und genutzt.
Die Regularisierung ist eine Form der Bestrafung der Verlustfunktion im Verhältnis zur diskreten Gewichtung, die in den verschiedenen Schichten eines neuronalen Netzes angewendet wird. Wir sehen uns an, welche Bedeutung dies für einige der verschiedenen Regularisierungsformen in Testläufen mit einem vom Assistenten zusammengestellten Expert Advisor haben kann.
In dieser Artikelserie nehmen wir klassische Strategien unter die Lupe, um zu sehen, ob wir sie mithilfe von KI verbessern können. Im heutigen Artikel werden wir die beliebte Strategie der Analyse mehrerer Zeitrahmen untersuchen, um zu beurteilen, ob die Strategie durch KI verbessert werden kann.
Gaußsche Prozesskerne sind die Kovarianzfunktion der Normalverteilung, die bei der Vorhersage eine Rolle spielen können. Wir untersuchen diesen einzigartigen Algorithmus in einer nutzerdefinierten Signalklasse von MQL5, um zu sehen, ob er als erstklassiges Einstiegs- und Ausstiegssignal verwendet werden kann.