Dieser Artikel stellt einen hochentwickelten Expert Advisor für den Devisenhandel vor, der maschinelles Lernen mit technischer Analyse kombiniert. Es konzentriert sich auf den Handel mit Apple-Aktien und bietet adaptive Optimierung, Risikomanagement und mehrere Strategien. Das Backtesting zeigt vielversprechende Ergebnisse mit hoher Rentabilität, aber auch erheblichen Drawdowns, was auf Potenzial für eine weitere Verfeinerung hinweist.
Dieser innovative Trading-Bot integriert MetaTrader 5 mit Python, um die Stimmungsanalyse sozialer Medien in Echtzeit für automatisierte Handelsentscheidungen zu nutzen. Durch die Analyse der Twitter-Stimmung in Bezug auf bestimmte Finanzinstrumente übersetzt der Bot Trends in den sozialen Medien in umsetzbare Handelssignale. Es nutzt eine Client-Server-Architektur mit Socket-Kommunikation, die eine nahtlose Interaktion zwischen den Handelsfunktionen von MT5 und der Datenverarbeitungsleistung von Python ermöglicht.
In diesem Artikel entwickeln wir ein dynamisches RSI-Indikator-Dashboard in MQL5, das Händlern Echtzeit-RSI-Werte für verschiedene Symbole und Zeitrahmen anzeigt. Das Dashboard bietet interaktive Schaltflächen, Echtzeit-Updates und farbkodierte Indikatoren, die Händlern helfen, fundierte Entscheidungen zu treffen.
Dieser Artikel untersucht eine Handelsstrategie, die die lineare Diskriminanzanalyse (LDA) mit Bollinger-Bändern integriert und kategorische Zonenvorhersagen für strategische Markteinstiegssignale nutzt.
Wir untersuchen weiterhin Algorithmen für die Zeitreihenprognose. In diesem Artikel werden wir eine andere Methode besprechen: den U-förmigen Transformator.
In diesem Artikel möchte ich Ihnen eine neue komplexe Methode zur Zeitreihenprognose vorstellen, die die Vorteile von linearen Modellen und Transformer harmonisch vereint.
Wir wissen bereits, dass die Vorverarbeitung der Eingabedaten eine wichtige Rolle für die Stabilität der Modellbildung spielt. Für die Online-Verarbeitung von „rohen“ Eingabedaten verwenden wir häufig eine Batch-Normalisierungsschicht. Aber manchmal brauchen wir ein umgekehrtes Verfahren. In diesem Artikel wird einer der möglichen Ansätze zur Lösung dieses Problems erörtert.
In diesem Artikel wird der Conformer-Algorithmus vorgestellt, der ursprünglich für die Wettervorhersage entwickelt wurde, die in Bezug auf Variabilität und Launenhaftigkeit mit den Finanzmärkten verglichen werden kann. Conformer ist eine komplexe Methode. Es kombiniert die Vorteile von Aufmerksamkeitsmodellen und gewöhnlichen Differentialgleichungen.
Dieser Artikel beschreibt die Schritte zur Erstellung eines Expert Advisors (EA), der Kursausbrüche nach Konsolidierungsphasen ausnutzt. Durch die Identifizierung von Konsolidierungsbereichen und die Festlegung von Ausbruchsniveaus können Händler ihre Handelsentscheidungen auf der Grundlage dieser Strategie automatisieren. Der Expert Advisor zielt darauf ab, klare Einstiegs- und Ausstiegspunkte zu bieten und gleichzeitig falsche Ausbrüche zu vermeiden.
Dieser Artikel behandelt häufige Anfängerfragen aus MQL5-Foren und zeigt praktische Lösungen auf. Lernen Sie, grundlegende Aufgaben wie Kaufen und Verkaufen, die Kursabfrage der Kerzen und die Verwaltung automatisierter Handelsaspekte wie Handelslimits, Handelszeiträume und Gewinn-/Verlustschwellen durchzuführen. Erhalten Sie eine schrittweise Anleitung, um Ihr Verständnis und Ihre Implementierung dieser Konzepte in MQL5 zu verbessern.
In diesem Artikel wird erörtert, wie sich Trendfolge- und Fundamentalprinzipien nahtlos in einen Expert Advisor integrieren lassen, um eine robustere Strategie zu entwickeln. In diesem Artikel wird gezeigt, wie einfach es für jedermann ist, mit MQL5 maßgeschneiderte Handelsalgorithmen zu erstellen und anzuwenden.
Die Erweiterung des MQL5-GUI-Panels um dynamische Funktionen kann die Handelserfahrung für die Nutzer erheblich verbessern. Durch die Einbindung interaktiver Elemente, Hover-Effekte und Datenaktualisierungen in Echtzeit wird das Panel zu einem leistungsstarken Werkzeug für moderne Händler.
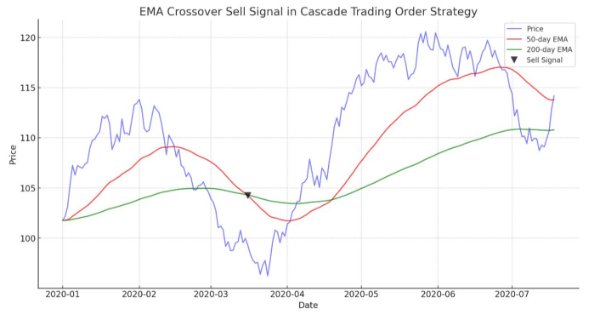
Der Artikel demonstriert einen automatisierten Algorithmus, der auf dem Kreuzen von EMAs für MetaTrader 5 basiert. Detaillierte Informationen zu allen Aspekten der Demonstration eines Expert Advisors in MQL5 und dem Testen in MetaTrader 5 - von der Analyse des Preisbereichsverhaltens bis zum Risikomanagement.
Smart Money Concept (Break Of Structure) in Verbindung mit dem RSI-Indikator, um fundierte automatisierte Handelsentscheidungen auf der Grundlage der Marktstruktur zu treffen.
In diesem Artikel werden wir die Sentiment-Analyse und ONNX-Modelle mit Python vorstellen, die in einem EA verwendet werden können. Ein Skript führt ein trainiertes ONNX-Modell aus TensorFlow für Deep Learning-Vorhersagen aus, während ein anderes Nachrichtenschlagzeilen abruft und die Stimmung mithilfe von KI quantifiziert.
Der Artikel beschreibt detailliert, wie die Erstellung eines Expert Advisors (EA) auf der Grundlage des Handelsalgorithmus umgesetzt werden kann. Dies hilft, das System im MQL5 zu automatisieren und die Kontrolle über den Daily Drawdown zu übernehmen.
Stellen Sie sich vor, dass Sie Daten verwenden können, die nicht im MetaTrader zu finden sind, sondern nur von Indikatoren der Preisanalyse und der technischen Analyse stammen. Stellen Sie sich nun vor, dass Sie auf Daten zugreifen können, die Ihre Handelskraft um ein Vielfaches erhöhen. Sie können die Leistung der MetaTrader-Software vervielfachen, wenn Sie den Output anderer Software, Makro-Analysemethoden und hochentwickelte Tools über die API-Daten. In diesem Artikel zeigen wir Ihnen, wie Sie APIs nutzen können und stellen Ihnen nützliche und wertvolle API-Datendienste vor.
In diesem Artikel werden die grundlegenden Schritte bei der Erstellung und Implementierung einer grafischen Nutzeroberfläche (GUI) mit MetaQuotes Language 5 (MQL5) erläutert. Nutzerdefinierte Utility-Panels verbessern die Nutzerinteraktion beim Handel, indem sie gängige Aufgaben vereinfachen und wichtige Handelsinformationen visualisieren. Durch die Erstellung nutzerdefinierter Panels können Händler ihre Arbeitsabläufe straffen und bei Handelsgeschäften Zeit sparen.
In früheren Arbeiten haben wir immer den aktuellen Zustand der Umwelt bewertet. Gleichzeitig blieb die Dynamik der Veränderungen bei den Indikatoren immer „hinter den Kulissen“. In diesem Artikel möchte ich Ihnen einen Algorithmus vorstellen, mit dem Sie die direkte Veränderung der Daten zwischen 2 aufeinanderfolgenden Umweltzuständen bewerten können.
In diesem Artikel werde ich mich mit dem GTGAN-Algorithmus vertraut machen, der im Januar 2024 eingeführt wurde, um komplexe Probleme der Generierung von Architekturlayouts mit Graphenbeschränkungen zu lösen.
In diesem Artikel werden wir versuchen, unsere eigene Handelsstrategie zu entwickeln. Jede Handelsstrategie muss auf einer Art statistischem Vorteil beruhen. Außerdem sollte dieser Vorteil noch lange Zeit bestehen.
In diesem Artikel wird detailliert beschrieben, wie man eine Risikomanager-Klasse für den manuellen Handel von Grund auf schreibt. Diese Klasse kann auch als Basisklasse für die Vererbung durch algorithmische Händler verwendet werden, die automatisierte Programme einsetzen.
In den vorangegangenen Teilen konnte der in Entwicklung befindliche Expert Advisor (EA) nur eine feste Positionsgröße für den Handel verwenden. Dies ist für Testzwecke akzeptabel, aber für den Handel mit einem echten Konto nicht ratsam. Lassen Sie uns den Handel mit variablen Positionsgrößen ermöglichen.
Ein umfassender Leitfaden zur Entwicklung eines automatisierten Handelsalgorithmus auf der Grundlage einer Unterstützungs- und Widerstandsstrategie. Detaillierte Informationen zu allen Aspekten der Erstellung eines Expert Advisors in MQL5 und dem Testen in MetaTrader 5 - von der Analyse des Preisbereichsverhaltens bis zum Risikomanagement.
In diesem Artikel werden die Schritte, die für die Erstellung eines auf dem Zone Recovery-Handelsalgorithmus basierenden Expert Advisors erforderlich sind, ausführlich beschrieben. Dies hilft, das System zu automatisieren und spart den Algotradern Zeit.
Im vorigen Artikel haben wir eine der Methoden zur Erkennung von Objekten in einem Bild kennengelernt. Die Verarbeitung eines statischen Bildes ist jedoch etwas anderes als die Arbeit mit dynamischen Zeitreihen, wie z. B. die Dynamik der von uns analysierten Preise. In diesem Artikel werden wir uns mit der Methode der Objekterkennung in Videos befassen, die dem Problem, das wir lösen wollen, etwas näher kommt.
In diesem Artikel schlage ich vor, das Thema der Entwicklung einer Handelsstrategie aus einem anderen Blickwinkel zu betrachten. Wir werden keine zukünftigen Kursbewegungen vorhersagen, sondern versuchen, ein Handelssystem auf der Grundlage der Analyse historischer Daten aufzubauen.
In Fortführung des Themas des vorangegangenen Artikels habe ich mich entschlossen, eine flexiblere und funktionellere Vorlage zu erstellen, die über größere Möglichkeiten verfügt und sowohl in der Freiberuflichkeit als auch als Basis für die Entwicklung von Mehrwährungs- und Mehrperioden-EAs mit der Fähigkeit zur Integration mit externen Lösungen effektiv genutzt werden kann.
Nachdem wir mit der Entwicklung eines Mehrwährungs-EAs begonnen haben, konnten wir bereits einige Ergebnisse erzielen und mehrere Iterationen zur Verbesserung des Codes durchführen. Unser EA war jedoch nicht in der Lage, mit schwebenden Aufträgen zu arbeiten und den Betrieb nach dem Neustart des Terminals wieder aufzunehmen. Fügen wir diese Funktionen hinzu.
In unseren Modellen verwenden wir häufig verschiedene Aufmerksamkeitsalgorithmen. Und am häufigsten verwenden wir wahrscheinlich Transformers. Ihr größter Nachteil ist der Ressourcenbedarf. In diesem Artikel wird ein neuer Algorithmus vorgestellt, der dazu beitragen kann, die Rechenkosten ohne Qualitätseinbußen zu senken.
Dieser Artikel setzt das Thema der Vorhersage der kommenden Kursentwicklung fort. Ich lade Sie ein, sich mit der Architektur eines Multi-Future Transformers vertraut zu machen. Die Hauptidee besteht darin, die multimodale Verteilung der Zukunft in mehrere unimodale Verteilungen zu zerlegen, was es ermöglicht, verschiedene Modelle der Interaktion zwischen Agenten auf der Szene effektiv zu simulieren.
In diesem Artikel wird eine recht effektive Methode zur Vorhersage der Trajektorie von Multi-Agenten vorgestellt, die sich an verschiedene Umweltbedingungen anpassen kann.
Wir fahren fort mit der Erörterung von Algorithmen für das Training von Trajektorievorhersagemodellen. In diesem Artikel werden wir uns mit einer Methode namens „AutoBots“ vertraut machen.
Die Qualität der Vorhersage zukünftiger Zustände spielt eine wichtige Rolle bei der Methode des Goal-Conditioned Predictive Coding, die wir im vorherigen Artikel besprochen haben. In diesem Artikel möchte ich Ihnen einen Algorithmus vorstellen, der die Vorhersagequalität in stochastischen Umgebungen, wie z. B. den Finanzmärkten, erheblich verbessern kann.
Ein umfassender Leitfaden für die Entwicklung eines automatisierten Handelsalgorithmus auf der Grundlage der Break of Structure (BoS)-Strategie. Detaillierte Informationen zu allen Aspekten der Erstellung eines Advisors in MQL5 und dessen Test in MetaTrader 5 - von der Analyse von Preisunterstützung und -widerstand bis hin zum Risikomanagement
In diesem Artikel werden wir einen Blick auf eine der berühmten Strategien von Bill Williams werfen, sie diskutieren und versuchen, die Strategie mit anderen Indikatoren und mit Vorhersagen zu verbessern.
In diesem Artikel werden wir die Möglichkeiten der leistungsstarken MQL5-Sprache beim Zeichnen verschiedener Indikatorstile in Meta Trader 5 untersuchen. Wir werden uns auch mit Skripten beschäftigen und wie sie in unserem Modell verwendet werden können.
Dieser Artikel vereinfacht die Dreiecksarbitrage und zeigt Ihnen, wie Sie mit Hilfe von Prognosen und spezieller Software intelligenter mit Währungen handeln können, selbst wenn Sie neu auf dem Markt sind. Sind Sie bereit, mit Expertise zu handeln?