Популяционный алгоритм оптимизации, вдохновленный спорным и малоизученным феноменом — механизмом человеческих сновидений. Группы агентов с разной "памятью", косинусоидальная модуляция движения и необычное распределение фаз 99/1 — узнайте, как эти особенности влияют на эффективность оптимизации ваших торговых стратегий.
В данной статье мы изучим последний простой случай использования шаблонов, а также поговорим о пользе и необходимости использования typename в коде. Хотя поначалу данная статья может показаться несколько сложной, необходимо правильно ее понять, чтобы в дальнейшем использовать шаблоны и typename.
Революционный подход к машинному обучению в трейдинге через квантовые вычисления. Статья демонстрирует практическую реализацию адаптивной системы QRC с постоянным дообучением для прогнозирования рыночных движений в реальном времени.
В этой статье мы очень внимательно рассмотрим, как решить проблему, поставленную в конце предыдущей статьи. Там была предпринята попытка создать шаблон такого типа, чтобы иметь возможность создавать шаблон для объединения данных.
В этой статье мы рассмотрим, как улучшить и более эффективно применять концепции, изложенные в предыдущей статье, используя мощные библиотеки графических элементов управления MQL5. Я шаг за шагом проведу вас через процесс создания полностью функционального графического интерфейса, объясняя стоящий за ним план проектирования, а также назначение и принцип работы каждого используемого метода. Кроме того, в конце статьи мы протестируем созданную нами панель, чтобы убедиться в ее корректной работе и соответствии заявленным целям.
Представляем вашему вниманию завершающий этап реализации и тестирования фреймворка TQNet, в котором теория встречается с реальной торговой практикой. Мы пройдём путь от исторического обучения до стресс-теста на свежих рыночных данных, оценивая устойчивость и точность модели. Итоговые результаты — это не только сухие цифры, но и наглядная демонстрация прикладной ценности предложенного подхода.
В данной статье мы изучим создание и применение программ форматирования для библиотек логов. Мы рассмотрим все этапы, от базовой структуры программы форматирования до примеров реализации таких программ на практике. К концу статьи вы получите все необходимые знания для форматирования логов в рамках библиотеки и поймете, как все работает за кулисами.
В этой статье мы рассмотрим первую часть темы, которая не так проста для понимания новичками. Чтобы не запутаться еще больше и правильно объяснить данную тему, мы разделим объяснение на этапы. Эту статью мы посвятим первому этапу. Однако, хотя в конце статьи может показаться, что мы зашли в тупик, на самом деле мы сделаем шаг к другой ситуации, которая будет лучше понятна в следующей статье.
Что если бы ваши торговые стратегии могли учиться друг у друга, как настоящие бойцы? Duelist Algorithm — новый метод оптимизации, где параметры торговых систем буквально сражаются в дуэлях за право называться лучшими.
Исправление ошибок — неотъемлемая часть цикла программирования. В этой статье рассмотрены типовые приемы исправления ошибок (отладки) любого приложения, работающего в среде MetaTrader 5.
Фреймворк TQNet открывает новые возможности в моделировании и прогнозировании финансовых временных рядов, сочетая модульность, гибкость и высокую производительность. В статье раскрывается возможность реализации сложных механизмом работы с глобальными корреляциями, включая продвинутые методы инициализации параметров.
В данной статье мы начнем создание класса C_Orders, чтобы иметь возможность отправлять ордера на торговый сервер. Мы будем делать это понемногу, поскольку наша цель состоит в том, чтобы подробно объяснить, как это будет происходить с помощью системы обмена сообщениями.
В постоянно меняющемся мире трейдинга адаптация к изменениям на рынке — это просто необходимость. Каждый день появляются новые закономерности и тенденции, из-за чего даже самым продвинутым моделям машинного обучения становится сложно оставаться эффективными в меняющихся условиях. В этой статье мы поговорим о том, как поддерживать актуальность моделей и их способность реагировать на новые рыночные данные с помощью автоматического дообучения.
Статья исследует революционную архитектуру нейронной сети Mamba/SSM для прогнозирования финансовых временных рядов. Представлена полная реализация на MQL5 современной альтернативы Transformer с линейной сложностью O(N) вместо квадратичной O(N²). Детально рассмотрены селективные State Space Models, hardware-aware оптимизации, patching техники и продвинутые методы обучения AdamW. Включены практические результаты тестирования, показавшие увеличение точности с 62% до 71% при снижении времени обучения с 45 до 8 минут. Представлен готовый торговый советник с автообучением и адаптивным риск-менеджментом для MetaTrader 5.
В этой статье мы расскажем, как справиться с одной из самых сложных ситуаций в программировании, с которой можно столкнуться: использование разных типов в одной и той же функции или шаблоне процедуры. Хотя большую часть времени мы уделяли только функциям, всё, что мы здесь рассмотрели, полезно и может быть применено к процедурам.
Предлагаем познакомиться с алгоритмом разложения временного ряда на смысловые слои и построения из них экономной модели. Мы последовательно показываем архитектуру, практическую реализацию на MQL5/OpenCL и реальные тесты на исторических рыночных данных.
Часто нам приходится делать шаг назад, а затем двигаться вперед. В этой статье мы покажем все изменения, необходимые для того, чтобы не нарушить работу индикаторов Mouse и Chart Trade. В качестве бонуса расскажем о других изменениях, произошедших в других заголовочных файлах, которые будут широко использоваться в будущем.
В данной статье мы представляем реализацию нескольких ансамблевых классификаторов на языке MQL5 и рассматриваем их эффективность в различных ситуациях.
Трейдинг характеризуется высокими требованиями к дисциплине риск-менеджмента. Настоящая работа представляет анализ основных причин неудач трейдеров и предлагает техническое решение в виде класса CEnhancedRiskManager для платформы MQL5. Включает практическое тестирование на агрессивном сеточном советнике.
Языковые модели (LLM) являются важной частью быстро развивающегося искусственного интеллекта, поэтому нам следует подумать о том, как интегрировать мощные LLM в нашу алгоритмическую торговлю. Большинству людей сложно настроить эти модели в соответствии со своими потребностями, развернуть их локально, а затем применить к алгоритмической торговле. В этой серии статей будет рассмотрен пошаговый подход к достижению этой цели.
В этой статье мы начнем рассматривать одну из концепций, которую многие новички избегают. Это связано с тем, что шаблоны - непростая тема, поскольку многие не понимают основного принципа, лежащего в основе шаблона: перегрузка функций и процедур.
В этой статье продолжаем практическое знакомство с SSCNN — архитектурным решением нового поколения, способным работать с фрагментированными временными рядами. Вместо слепого масштабирования — разумная модульность, внимание к деталям и точечная нормализация. Мы шаг за шагом создаём вычислительные блоки в среде MQL5 и закладываем основу для надёжного прогнозного анализа.
В отличие от того, что было в предыдущей статье, здесь мы осуществим проверку опции выбора на советнике. Хотя это еще не окончательное решение, но пока этого будет достаточно. С помощью данной статьи, вы сможете понять, как реализовать одно из возможных решений.
В статье рассматриваются основные методы обработки файлов MQL5, ведение журналов торговли, обработка CSV-файлов и интеграция внешних данных. Статья содержит как теорию, так и практическое руководство по реализации. Читатели научатся шаг за шагом создавать собственный класс импортера CSV, получив практические навыки для реальных приложений.
В этой статье рассматривается применение Grey-моделей для прогнозирования финансовых временных рядов. Мы рассмотрим принципы работы Grey-моделей и особенности их применения к финансовым рядам. Обсудим преимущества и ограничения использования этих моделей в трейдинге.
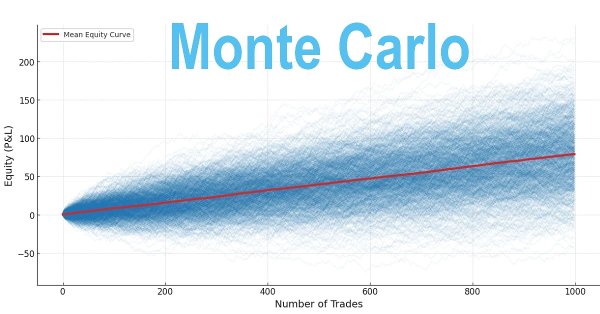
Многие трейдеры оценивают стратегии, основываясь на краткосрочных результатах, часто слишком рано отказываясь от прибыльных систем. Однако долгосрочная прибыльность зависит от положительного ожидания посредством оптимизированного Win Rate и соотношения доходности к риску (Risk-Reward), а также дисциплины при выборе размера позиции. Эти принципы можно проверить с помощью метода Монте-Карло в Python с использованием проверенных на исторических данных показателей, чтобы оценить, является ли стратегия надежной или со временем может потерпеть неудачу.
Сегодня мы начнем второй этап, на котором рассмотрим вопрос о системе репликации/моделирования рынка. Для начала мы покажем возможное решение для кросс-ордеров. Я покажу решение, но оно еще не окончательное, это будет вариант решения проблемы, решить которую предстоит в ближайшем будущем.
В этой статье мы создаем советник, который автоматизирует стратегию прорыв Кумо (Kumo Breakout) с использованием индикатора Ichimoku Kinko Hyo и Awesome Oscillator. Мы рассмотрим инициализацию хэндлов индикаторов, обнаружение условий прорыва и автоматизацию входов и выходов из сделок. Кроме того, мы внедрим трейлинг-стопы и логику управления позициями для повышения производительности советника и его адаптивности к рыночным условиям.
В этой части мы рассмотрим реализацию ключевых интерфейсов библиотеки Гауссовских процессов на MQL5 — IKernel, ILikelihood и IInference. Также мы продемонстрируем её работу на синтетических данных и и напишем индикаторы для классификации и регрессии, демонстрирующие её работу в онлайн-режиме — с переобучением модели на каждом новом баре.
В данной статье мы начинаем знакомство с фреймворком SSCNN — современным архитектурным решением для анализа временных рядов, сочетающим в себе точность, структурированность и высокую вычислительную эффективность. Мы последовательно рассмотрим его теоретические аспекты, обратим внимание на ключевые отличия от предшественников и начнем практическую реализацию базовых компонентов в среде MQL5.
В статье рассматриваются передовые методы интеграции MQL5 с мощными инструментами обработки данных, а также уделяется внимание эффективной обработке больших данных для улучшения торгового анализа и принятия решений.
Я поставил перед собой задачу построить торговую стратегию вокруг пары USDJPY. Мы будем использовать свечные модели, которые формируются на дневном таймфрейме, поскольку они потенциально имеют большую силу. Наша первоначальная стратегия оказалась прибыльной, что побудило нас продолжить ее совершенствование и добавить дополнительные уровни безопасности для защиты полученного капитала.
Иногда не все можно запрограммировать на языке MQL5. И даже если возможно конвертировать существующие современные библиотеки в MQL5, на это уйдет много времени. В данной статье мы попытаемся обойти зависимость от Windows с помощью MQL5-сервисов — будем передавать тиковые данные (bid, ask и time) в приложение Python с помощью сокетов.
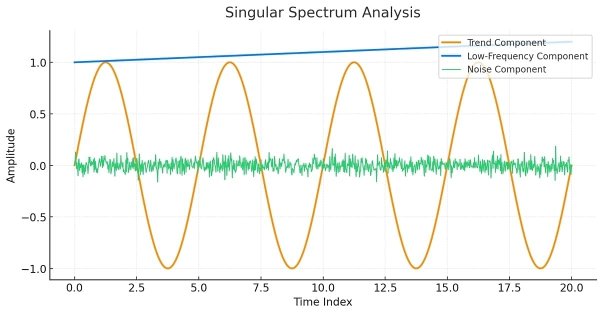
Данная статья предназначена в качестве руководства для тех, кто не знаком с концепцией сингулярного спектрального анализа и хочет получить достаточно знаний, чтобы иметь возможность применять встроенные инструменты, доступные на MQL5.
Добро пожаловать в третью часть серии статьей о трендах! Сегодня мы углубимся в использование дивергенции как стратегии определения оптимальных точек входа в рамках преобладающего дневного тренда. Мы также представим специальный механизм фиксации прибыли, аналогичный скользящему стоп-лоссу, но с уникальными усовершенствованиями. Кроме того, мы обновим советник Trend Constraint до более продвинутой версии, включив в него новое условие исполнения сделки в дополнение к существующим. Также мы продолжим изучать практическое применение MQL5 в разработке алгоритмов.
Реализация алгоритма A3 на MQL5 — метаэвристического метода оптимизации, вдохновленного химическими процессами. Всего 2 настраиваемых параметра, компактность и небольшая популяция обеспечивают высокую скорость работы при достаточном качестве решений.
Определить направление рынка может быть просто, но вот понять, когда входить на рынок, - гораздо более сложная задача. В этой статье серии "Разработка инструментария для анализа движения цен" я представлю еще один инструмент, который определяет точки входа и уровни стоп-лосса/тейк-профита. Для достижения этой цели использовался язык программирования MQL5.
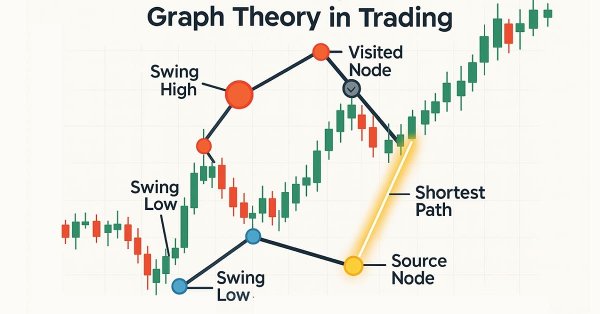
Алгоритм Дейкстры — классическое решение по поиску кратчайшего пути в теории графов, которое позволяет оптимизировать торговые стратегии путем моделирования рыночных сетей. Трейдеры могут использовать его для поиска наиболее эффективных маршрутов в данных свечного графика.
В этой статье мы рассмотрим основы управления рисками в трейдинге и узнаем, как создать свои первые функции для расчета подходящего лота для сделки, а также стоп-лосса. Кроме того, мы подробно рассмотрим, как работают эти функции, объясняя каждый шаг. Наша цель — дать четкое понимание того, как применять эти концепции в автоматической торговле. В конце мы применим все на практике, создав простой скрипт с разработанным нами включаемым файлом.