В данной статье мы исследуем систему Profitunity авторства Билла Вильямса, подробно разобрав ее ключевые составляющие и уникальный подход к торговле в хаотичных условиях рынка. Мы продемонстрируем читателям реализацию системы на языке программирования MQL5, делая акцент на автоматизации ключевых индикаторов и сигналов для входа/выхода. Наконец, мы протестируем и оптимизируем стратегию, детально анализируя ее эффективность в различных рыночных сценариях.
Алгоритмическая торговая система, сочетающая анализ объема с методами машинного обучения, в частности с нейронными сетями LSTM. В отличие от традиционных торговых подходов, которые в первую очередь фокусируются на движении цен, эта система делает упор на паттернах объема и их производных для прогнозирования движений рынка. Методология включает в себя три основных компонента: анализ производных от объема (первые и вторые производные), прогнозы LSTM для паттернов объема и традиционные технические индикаторы.
В настоящей статье мы представляем реализацию поэтапного отбора признаков на MQL5, основанную на взаимной информации между оптимальным набором предикторов и целевой переменной.
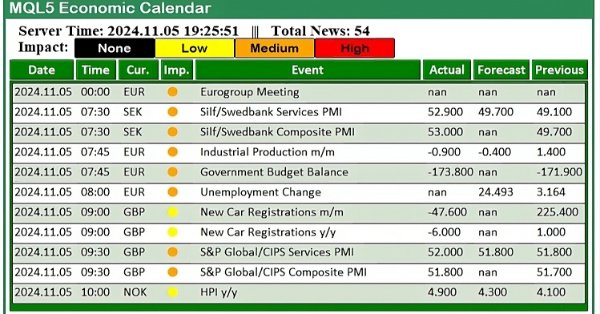
В этой статье мы создадим практичную новостную панель с использованием экономического календаря MQL5 для улучшения нашей торговой стратегии. Начнем с проектирования макета, уделив особое внимание ключевым элементам, таким как названия событий, важность и время, а затем перейдем к настройке в MQL5. Наконец, мы внедрим систему сортировки для отображения только самых актуальных новостей, предоставляя трейдерам быстрый доступ к важным экономическим событиям.
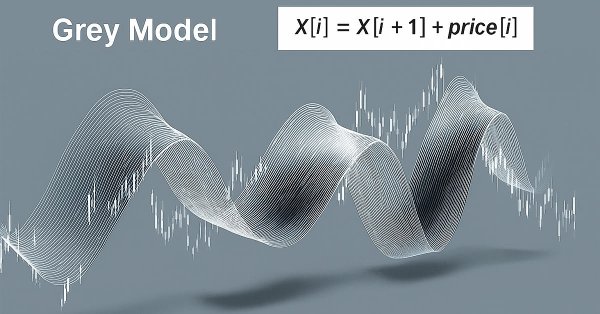
Данная статья посвящена изучению grey-модели — перспективного инструмента, способного расширить возможности трейдера. Мы рассмотрим некоторые варианты применения этой модели для технического анализа и построения торговых стратегий.
Создание системы анализа валютных курсов на основе паритета покупательной способности (ППС) на Python. Автор разработал алгоритм с 5 методами расчета справедливых курсов, используя данные МВФ. Практическое руководство по фундаментальному анализу валют, обработке экономических данных и интеграции с торговыми системами. Полный код в open source.
В данной статье предпринята попытка рассмотрения финансовых временных рядов с точки зрения самоподобных фрактальных структур. Поскольку мы имеем слишком много аналогий, которые подтверждают возможность рассматривать рыночные котировки в качестве самоподобных фракталов, то имеем возможность составить представления о горизонтах прогнозирования таких структур.
На форуме MQL5 есть множество сообщений с просьбами помочь рассчитать угол наклона изменения цены. В этой статье мы рассмотрим один из способов расчета наклона изменения цены. Этот способ применим на любом рынке. Кроме того, мы определим, стоит ли разработка этой новой функции дополнительных усилий и времени. Выясним, может ли угол наклона цены улучшить точность нашей AI-модели при прогнозировании пары USDZAR на минутном таймфрейме.
Eagle Strategy — алгоритм, имитирующий двухфазную охотничью стратегию орла: глобальный поиск через полеты Леви методом Мантенья, чередуется с интенсивной локальной эксплуатацией светлячкового алгоритма, математически обоснованный подход к балансу между исследованием и эксплуатацией, а также биоинспирированная концепция, объединяющая два природных феномена в единый вычислительный метод.
В этой заключительной части нашей серии библиотеки Connexus мы рассмотрели реализацию паттерна Наблюдатель, а также основные рефакторинги в путях к файлам и именах методов. В этой серии представлена вся разработка Connexus, предназначенная для упрощения HTTP-взаимодействия в сложных приложениях.
Эта статья увлекательно покажет, как SwiGLU‑эмбеддинг раскрывает скрытые паттерны рынка, а разреженная смесь экспертов внутри Decoder‑Only Transformer делает прогнозы точнее при разумных вычислительных затратах. Мы подробно разбираем интеграцию Time‑MoE в MQL5 и OpenCL, шаг за шагом описываем настройку и обучение модели.
Ichimuko Kinko Hyo — известный японский индикатор, представляющий собой систему определения тренда. Как и в предыдущих статьях, мы рассмотрим этот индикатор с использованием паттернов и поделимся стратегиями и отчетами о тестировании, применив классы библиотеки Мастера MQL5.
Загрузка данных Международного валютного фонда на Python: добываем данные IMF для применения в макроэкономических валютных стратегиях. Как макроэкономика может помочь трейдеру и алготрейдеру?
В этой статье мы продолжим знакомство с директивой #define, но на этот раз мы сосредоточимся на второй форме ее использования, то есть на создании макросов. Поскольку данная тема может быть немного сложной, мы решили использовать приложение, которое мы изучаем уже некоторое время. Надеюсь, вам понравится сегодняшняя статья.
В этой статье мы расскажем о некоторых деталях и мерах предосторожности, которые следует учитывать при создании протокола связи. Это довольно простые и понятные вещи, так что мы не будем слишком углубляться в эту статью. Но чтобы понять, что произойдет у получателя, нужно разобраться в содержании статьи.
В этой статье мы детально рассмотрим класс управления сделками, включив в него ордера buy stop и sell stop для торговли новостными событиями, а также введем ограничение срока действия этих ордеров, чтобы предотвратить переносы торговли на следующий день. В советник будет встроена функция проскальзывания, которая попытается предотвратить или минимизировать возможное проскальзывание, которое может возникнуть при использовании стоп-ордеров в торговле, особенно во время выхода новостей.
В настоящей статье мы продолжаем разработку библиотеки Connexus. В настоящей главе мы создаем класс CHttpClient, отвечающий за отправку запроса и получение ордера. Мы также рассматриваем концепцию моков (mocks), отделяя библиотеку от функции WebRequest, что обеспечивает большую гибкость для пользователей.
Предлагаем познакомиться с практической реализацией блока разреженной смеси экспертов для временных рядов в вычислительной среде OpenCL. В статье шаг за шагом разбирается работа маскированной многооконной свёртки, а также организация градиентного обучения в условиях множественных информационных потоков.
Настоящая статья знакомит трейдеров с Генеративно-состязательными сетями (GAN) для генерации Синтетических финансовых данных, устраняя ограничения данных в процессе обучения модели. В ней рассматриваются основы GAN, реализация кода на python и MQL5, а также практическое применение в финансовой сфере, позволяющее трейдерам повысить точность и надежность моделей с помощью синтетических данных.
В этой статье мы представляем модифицированную версию поэтапного отбора признаков, реализованную в MQL5. Настоящий подход основан на методах, описанных Тимоти Мастерсом (Timothy Masters) в работе "Современных алгоритмах интеллектуального анализа данных на C++" и "CUDA C".
В этой статье мы узнаем, как создать индикатор, который обнаруживает, рисует и предупреждает о смягчении ордер-блоков (ОВ). Также мы подробно рассмотрим, как идентифицировать эти блоки на графике, устанавливать точные предупреждения и визуализировать их положение с помощью прямоугольников, чтобы лучше понять поведение цены. Данный индикатор станет ключевым инструментом для тех, кто следует концепциям Smart Money Concepts и методологии Inner Circle Trader.
Управление рисками торгового счета является сложной задачей для всех трейдеров. Можем ли мы разработать торговые приложения, которые динамически изучают режимы высокого, среднего и низкого риска для различных символов в MetaTrader 5? Используя PCA, мы получаем лучший контроль над дисперсией портфеля. Я продемонстрирую, как создавать приложения, которые изучают эти три режима риска на основе рыночных данных, полученных из MetaTrader 5.
Роль администратора выходит за рамки простого общения в Telegram; он также может заниматься различными видами контроля, включая управление ордерами, отслеживание позиций и настройку интерфейса. В этой статье мы поделимся практическими советами по расширению нашей программы для поддержки множества функций в MQL5. Это обновление направлено на преодоление ограничений текущей панели администратора, которая в первую очередь сосредоточена на общении.
Оптимизация на основе биогеографии (BBO) — элегантный метод глобальной оптимизации, вдохновленный природными процессами миграции видов между островами архипелагов. В основе алгоритма лежит простая, но мощная идея: решения с высоким качеством активно делятся своими характеристиками, решения низкого качества активно заимствуют новые черты, создавая естественный поток информации от лучших решений к худшим. Уникальный адаптивный оператор мутации, обеспечивает превосходный баланс между исследованием и эксплуатацией, BBO демонстрирует высокую эффективность на различных задачах.
В настоящей статье мы рассмотрим основы гауссовских процессов (ГП) как вероятностную модель машинного обучения и продемонстрируем ее применение в регрессионных задачах на примере синтетических данных.
Предлагаем познакомиться с современным фреймворком Time-MoE, адаптированным под задачи прогнозирования временных рядов. В статье мы пошагово реализуем ключевые компоненты архитектуры, сопровождая их объяснениями и практическими примерами. Такой подход позволит вам не только понять принципы работы модели, но и применить их в реальных торговых задачах.
Традиционное машинное обучение учит специалистов быть бдительными и не допускать переобучения своих моделей. Однако эта идеология подвергается сомнению в связи с новыми открытиями, опубликованными исследователями из Гарварда, которые обнаружили, что то, что кажется переобучением, в некоторых обстоятельствах может быть результатом преждевременного прекращения процедур обучения. Мы покажем, как можно использовать идеи этой научной публикации для улучшения использования ИИ при прогнозировании доходности рынка.
В этой статье мы рассмотрим, как работает недостающий код из предыдущей статьи, DispatchMessage. Здесь мы введем тему следующей статьи. По этой причине важно понять, как работает данная процедура, прежде чем переходить к следующей теме. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте это приложение как окончательное, цели которого будут иные, кроме изучения представленных концепций.
Эта статья является кратким введением к понятию числа с плавающей точкой. Поскольку этот текст очень сложный, советую вам прочитать его спокойно и внимательно. Не рассчитывайте быстро освоить систему с плавающей точкой, она становится понятной только со временем, по мере появления опыта использования. Но эта статья поможет вам понять, почему ваше приложение иногда выдает результат, отличный от ожидаемого.
Скользящие средние являются, безусловно, самыми эффективными индикаторами для прогнозирования моделями ИИ. Однако точность результатов можно еще больше повысить, если перед этим соответственным образом преобразовать данные. В этой статье мы поговорим о создании AI-моделей, которые могут прогнозировать в более отдаленное будущее без существенного снижения уровня точности. В очередной раз мы с вами убедимся, насколько полезны скользящие средние.
В этой статье мы расскажем о классе C_ChartFloatingRAD. Это то, что позволяет Chart Trade работать. Однако на этом объяснение не закончится. Мы завершим его в следующей статье, так как содержание данной статьи довольно объемное и требует глубокого понимания. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
Python-пакет MetaTrader 5 предлагает простой способ создания торговых приложений для платформы MetaTrader 5 на языке Python. Будучи мощным и полезным инструментом данный модуль не так прост как язык программирования MQL5, когда дело касается разработки решений для алгоритмической торговли. В данной статье мы создадим классы для торговли, аналогичные предлагаемым в языке MQL5, чтобы создать схожий синтаксис и сделать разработку торговых роботов на Python такой же простой как и на MQL5.
Скользящие средние и стохастический осциллятор можно использовать для генерации торговых сигналов, следующих за трендом. Однако эти сигналы будут наблюдаться только после того, как произойдет ценовое движение. Мы можем эффективно преодолеть этот неизбежный лаг в технических индикаторах с помощью искусственного интеллекта. В настоящей статье мы расскажем, как создать полностью автономный советник на базе ИИ таким образом, чтобы улучшить любую из ваших существующих торговых стратегий. Даже самая старая торговая стратегия может быть улучшена.
Статья посвящена практическому построению модели TimeFound для прогнозирования временных рядов. Рассматриваются ключевые этапы реализации основных подходов фреймворка средствами MQL5.
Монте-Карло — четвертый алгоритм обучения с подкреплением, который мы рассматриваем в контексте его реализации в советниках, собранных с помощью Мастера. Хотя алгоритм основан на случайной выборке, он предоставляет обширные возможности моделирования.
В этой статье мы изменим последний код, показанный в данной серии о Chart Trade. Эти изменения необходимы, чтобы адаптировать код к текущей модели системы репликации/моделирования. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
В этой шестой статье из серии о библиотеке Connexus мы сосредоточимся на полном HTTP-запросе, рассмотрев каждый компонент, из которого состоит запрос. Мы создадим класс, представляющий запрос в целом, который поможет нам объединить ранее созданные классы.
Настоящий проект направлен на использование алгоритма MQL5 для разработки комплексного набора инструментов анализа для MetaTrader 5. Эти инструменты — от скриптов и индикаторов до моделей искусственного интеллекта и советников — позволят автоматизировать процесс анализа рынка. Иногда такая разработка позволяет создавать инструменты, способные выполнять углубленный анализ без участия человека и прогнозировать результаты на соответствующих платформах. Ни одна возможность не будет упущена. Присоединяйтесь ко мне в рамках исследования процесса создания надежного набора пользовательских инструментов для анализа рынка. Начнем с разработки простой программы на MQL5, которую я назвал Chart Projector (Проектор графиков).
В статье рассматривается реализация модифицированного алгоритма анализа компонентов прямого отбора, вдохновленного исследованиями, представленными в книге Луки Пуггини (Luca Puggini) и Шона Маклуна (Sean McLoone) “Анализ компонентов прямого отбора: алгоритмы и приложения”.
В этой статье мы шаг за шагом собираем ядро интеллектуальной модели TimeFound, адаптированной под реальные задачи прогнозирования временных рядов. Если вас интересует практическая реализация нейросетевых патчинг-алгоритмов в MQL5 — вы точно по адресу.