Neste artigo iremos finalizar a fase, onde estamos desenvolvendo o simulador para o nosso sistema. O principal proposito aqui será ajustar o algoritmo visto no artigo anterior. Tal algoritmo tem como finalidade criar o movimento de RANDOM WALK. Por conta disto, o entendimento do conteúdo dos artigos anteriores, é primordial para acompanhar o que será explicado aqui. Se você não acompanhou o desenvolvimento do simulador, aconselho você a ver esta sequência desde o inicio. Caso contrário, poderá ficar perdido no que será explicado aqui.
Neste artigo, estaremos analisando o algoritmo do macaco (Monkey Algorithm, MA). A habilidade destes animais ágeis para superar obstáculos complexos e atingir as partes mais inacessíveis das árvores foi a inspiração para a concepção do MA.
Nesse artigo vamos explicar como desenvolver um fator de qualidade para ser retornado pelo seu EA no testador de estratégia. Iremos mostrar duas formas de cálculo conhecidas (Van Tharp e Sunny Harris).
Este é um novo artigo de uma série na qual aprendemos a desenvolver sistemas de negociação baseados em indicadores técnicos conhecidos. Neste novo artigo, analisamos o Índice de Facilitação do Mercado (Market Facilitation Index, MFI), criado por Bill Williams.
A Teoria das Categorias representa um segmento diversificado e em constante expansão da matemática, que até agora está relativamente pouco explorado na comunidade MQL5. Esta sequência de artigos visa elucidar algumas das suas concepções com o intuito de constituir uma biblioteca aberta e potencializar ainda mais o uso deste notável setor na elaboração de estratégias de negociação.
Neste artigo continuaremos a fase de desenvolvimento do simulador. Mas agora, vamos ver como criar de fato um movimento do tipo RANDOM WALK. Este tipo de movimentação é muito interessante, pois tudo envolvido no mercado de capitais tem como base este tipo de movimentação. Além do mais você vai começar a entender alguns conceitos importantes para quem faz estáticas de mercado.
Aqui iremos dar uma leve otimizada nas coisas. Isto para facilitar o que iremos fazer no próximo artigo. Mas também irei explicar como você pode visualizar o que o simulador está gerando em termos de aleatoriedade.
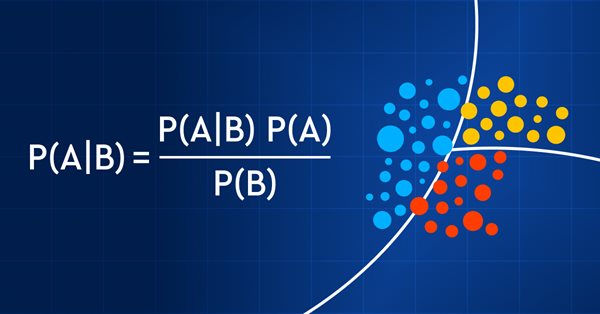
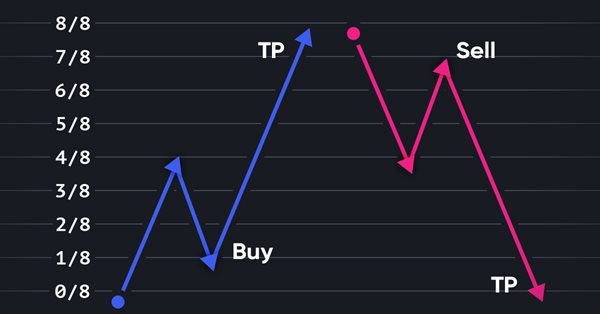
A negociação com base em probabilidades pode ser comparada a caminhar sobre uma corda bamba - ela requer precisão, equilíbrio e uma compreensão clara do risco envolvido. No mundo do trading, a probabilidade é fundamental. É ela que determina o resultado: sucesso ou fracasso, lucro ou prejuízo. Ao aproveitar as possibilidades da probabilidade, os traders podem tomar decisões mais fundamentadas, gerenciar os riscos de maneira mais eficiente e alcançar seus objetivos financeiros. Não importa se você é um investidor experiente ou um trader iniciante, entender a probabilidade pode ser a chave para desbloquear seu potencial de negociação. Neste artigo, exploraremos o fascinante mundo do trading baseado em probabilidades e mostraremos como levar seu modo de negociar a um nível superior.
Hoje, estudaremos e testaremos o algoritmo de otimização mais avançado, a busca harmônica (HS), que é inspirada no processo de procura da harmonia sonora perfeita. Então, qual algoritmo é agora o líder em nossa classificação?
Este artigo trata da teoria e prática do uso do algoritmo de retropropagação de erros no MQL5 através de matrizes. Oferecemos classes prontas e exemplos de scripts, indicadores e EAs.
O GSA é um algoritmo populacional inspirado na natureza inanimada. Sua capacidade de modelar com alta precisão a interação entre corpos físicos, através da lei da gravidade de Newton incorporada no algoritmo, permite contemplar um espetáculo fascinante de dança entre sistemas planetários e aglomerados galácticos, representado de forma impressionante em animações. Hoje vamos discutir um dos algoritmos de otimização mais interessantes e originais. Um simulador de movimento de objetos espaciais está incluído.
Alan Andrews é um dos mais renomados "educadores" do mundo do trading atual, no campo da análise de mercado. Suas "forquilhas" estão presentes em praticamente todos os programas modernos de análise de cotações. No entanto, a maioria dos traders utiliza apenas uma pequena fração das possibilidades oferecidas por essa ferramenta. O curso original de Andrews abrange não apenas a descrição das forquilhas (embora sejam o aspecto principal), mas também outras diretrizes úteis. Este artigo apresenta uma visão dessas incríveis técnicas de análise de gráficos que Andrews ensinou em seu curso original. Atenção: muitas imagens serão utilizadas.
O aprendizado de máquina se tornou uma técnica popular de desenvolvimento de estratégias. Na negociação, tradicionalmente, mais atenção é dada à maximização da lucratividade e à precisão das previsões. Enquanto isso, o processamento de dados usado para construir modelos preditivos permanece na periferia. Neste artigo, discutimos o uso do conceito de entropia para avaliar a adequação de indicadores na construção de modelos preditivos, conforme descrito no livro Testing and Tuning Market Trading Systems escrito por Timothy Masters.
Minha estratégia se baseia em fundamentos clássicos de negociação e no aprimoramento de indicadores amplamente usados em todos os tipos de mercados. Na verdade, trata-se de uma ferramenta pronta para trabalhar integralmente com a nova estratégia de negociação lucrativa que proponho.
Neste artigo, iremos responder à pergunta de como escolher o Expert Advisor correto. Quais são os mais adequados para o nosso portfólio e como podemos filtrar a maioria dos robôs de negociação disponíveis no mercado? Este artigo apresenta vinte caraterísticas evidentes de um EA de baixa qualidade. Ele ajudará você a tomar decisões mais informadas e criar uma coleção de EAs lucrativos.
Desenvolver um simulador pode ser muito mais interessante do que parece. Então vamos dar mais alguns passos nesta direção, pois a coisa está começando a ficar empolgante.
Para poder usar dados que formam barras, precisamos abandonar o replay e começar a desenvolver um simulador. Não sabemos como ela foi criada. Estaremos utilizando as barras de 1 minuto, justamente pelo motivo, de elas nos darem, um nível de complexidade mínimo.
Este artigo explora como trabalhar com bancos de dados baseados no mecanismo SQLite. Com o objetivo de oferecer conveniência e utilizar eficientemente os princípios da OOP, foi criada a classe CDatabase. Essa classe é responsável pela criação e gerenciamento de um banco de dados de eventos macroeconômicos. Além disso, são apresentados exemplos de como utilizar diferentes métodos da classe CDatabase.
Aqui vamos ver como você pode utilizar dados mais fieis ( tickets negociados ) no sistema de replay, sem necessariamente ter que se preocupar se eles estão ou não ajustados.
Este artigo descreve o processo de desenvolvimento para a plataforma MetaTrader 5 exclusivamente em Linux. O produto final funciona tanto no Windows quanto no Linux sem nenhum problema. Veremos o Wine e o Mingw, ferramentas importantes para o desenvolvimento entre plataformas. O Mingw apresenta threads (POSIX e Win32), que você deve levar em conta ao escolher uma ferramenta adequada. Criaremos também uma DLL para testar o conceito e usá-la no código MQL5, comparando o desempenho das duas implementações de threading. O artigo tem como objetivo ser um ponto de partida para a realização de seus próprios experimentos. Depois de ler este artigo, você será capaz de criar ferramentas para o MetaTrader no Linux.
Os sistemas gráficos de análise de preços são amplamente reconhecidos e apreciados pelos traders. Neste artigo, irei abordar o sistema Murray em sua totalidade, que engloba não apenas os renomados níveis, mas também outras técnicas úteis para avaliar a posição atual do preço e tomar decisões de negociação.
A surpreendente capacidade das plantas daninhas de sobreviver em uma ampla variedade de condições foi a inspiração para o desenvolvimento de um poderoso algoritmo de otimização. O IWO (Invasive Weed Optimization) é considerado um dos melhores entre os analisados até o momento.
A base da estratégia de forrageamento de E. coli (E. coli) inspirou cientistas a desenvolverem o algoritmo de otimização BFO. Esse algoritmo apresenta ideias originais e abordagens promissoras para otimização e merece um estudo mais aprofundado.
As redes neurais são tudo para nós. E vamos verificar na prática se é assim, indagando se MetaTrader 5 é uma ferramenta autossuficiente para implementar redes neurais na negociação. A explicação vai ser simples.
As cadeias de Markov são uma poderosa ferramenta matemática que pode ser usada para modelar e prever dados de séries temporais em vários campos, incluindo finanças. Na modelagem e previsão de séries temporais financeiras, as cadeias de Markov são frequentemente usadas para modelar a evolução de ativos financeiros ao longo do tempo, ativo esses como preços de ações ou pares de moedas. Uma das principais vantagens dos modelos das cadeias de Markov é sua simplicidade e facilidade de uso.
No artigo anterior fizemos a correção de alguns pontos, e adicionamos alguns testes no nosso sistema de replay, estes tentam garantir a maior estabilidade quanto for possível obter, ao mesmo tempo iniciamos a criação e o uso de um arquivo de configuração para o sistema de replay.
Vamos considerar o método de otimização de vaga-lumes (Firefly Algorithm, FA). Esse algoritmo evoluiu de um método desconhecido por meio de modificações para se tornar um líder real na tabela de classificação.
Continuamos a estudar os algoritmos de aprendizado Q distribuído. Em artigos anteriores, já discutimos os algoritmos de aprendizado Q distribuído e de quantil. No primeiro, aprendemos as probabilidades de determinados intervalos de valores. No segundo, aprendemos intervalos com uma probabilidade específica. Em ambos os algoritmos, utilizamos o conhecimento prévio de uma distribuição e ensinamos a outra. Neste artigo, vamos examinar um algoritmo que permite que o modelo aprenda ambas as distribuições.
Neste artigo vamos começar a estabilizar todo o sistema. Pois sem que o sistema esteja de fato estabilizado, podemos correr risco de não conseguir cumprir os próximos passos.
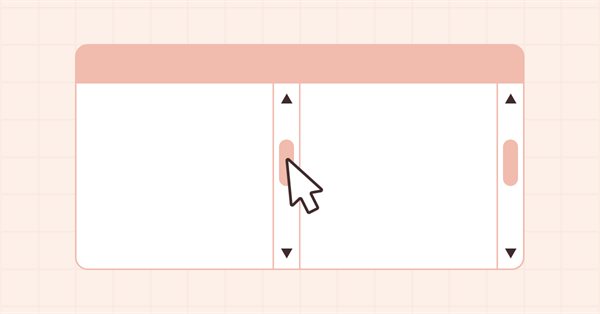
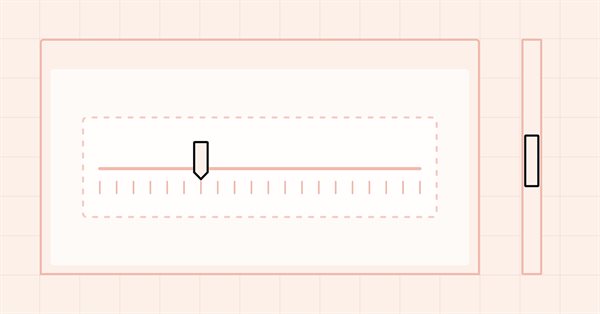
Neste artigo continuaremos a desenvolver o controle ScrollBar e começaremos a fazer a funcionalidade de interação com o mouse. Além disso, vamos expandir as listas de bandeiras de status e eventos com o mouse.
Neste artigo, iniciaremos o desenvolvimento do elemento de controle auxiliar ScrollBar e seus objetos derivados, incluindo as barras de rolagem vertical e horizontal. A ScrollBar (barra de rolagem) é utilizada para rolar o conteúdo da forma caso ele ultrapasse o contêiner. As barras de rolagem geralmente são posicionadas na parte inferior e à direita da forma. A barra de rolagem horizontal, localizada na parte inferior, permite rolar o conteúdo para a esquerda e direita, enquanto a barra de rolagem vertical possibilita rolar o conteúdo para cima e para baixo.
Continuamos a explorar algoritmos de aprendizado por reforço. Todos os algoritmos que analisamos até agora exigiam a criação de uma política de recompensa de tal forma que o agente pudesse avaliar cada uma de suas ações em cada transição de um estado do sistema para outro. No entanto, essa abordagem é bastante artificial. Na prática, existe um intervalo de tempo entre a ação e a recompensa. Neste artigo, proponho que você se familiarize com um algoritmo de aprendizado de modelo capaz de lidar com diferentes atrasos temporais entre a ação e a recompensa.
O FSS (Fish School Search) é um algoritmo avançado de otimização inspirado no comportamento dos peixes que nadam em cardumes. Aproximadamente 80% desses peixes nadam em comunidades organizadas de parentes, o que tem sido comprovado como uma estratégia importante para melhorar a eficiência de procura por alimento e proteção contra predadores.