Статья представляет новый подход к созданию торговых систем на основе квантовых принципов и искусственного интеллекта. Автор описывает разработку уникальной нейронной сети, которая выходит за рамки классического машинного обучения, объединяя квантовую механику с современными архитектурами ИИ.
Проксимальная оптимизация политики (Proximal Policy Optimization) — еще один алгоритм обучения с подкреплением, который обновляет политику, часто в сетевой форме, очень маленькими шагами, чтобы обеспечить стабильность модели. Как обычно, мы рассмотрим, как этот алгоритм можно применить в советнике, собранном с помощью Мастера.
Инновационный подход к сбору информации с индикаторов на MQL5 обеспечивает более гибкий и оптимизированный анализ данных, позволяя разработчикам вводить пользовательские данные в индикаторы для осуществления немедленных расчетов. Этот подход особенно полезен для алгоритмической торговли, поскольку он обеспечивает повышенный контроль над информацией, обрабатываемой индикаторами, выходя за рамки традиционных ограничений.
В данной статье проведено исследование на тему возможности применения регрессионных моделей в алгоритмической торговле. Регрессионные модели, в отличие от бинарной классификации, дают возможность создавать более гибкие торговые стратегии за счет количественной оценки прогнозируемых ценовых изменений.
В настоящей статье мы обсудим реализацию MQL5 в партнерстве с Python для выполнения связанных с брокером операций. Представьте, что у вас есть постоянно работающий советник (EA), размещенный на VPS и совершающий сделки от вашего имени. В какой-то момент способность советника управлять средствами становится первостепенной. Она включает в себя такие операции, как пополнение вашего торгового счета и инициирование вывода средств. В данном обсуждении мы прольем свет на преимущества и практическую реализацию этих функций, обеспечивающих плавную интеграцию управления средствами в вашу торговую стратегию. Следите за обновлениями!
Статья посвящена подробному анализу алгоритма Exchange Market Algorithm (EMA), который вдохновлен поведением трейдеров на фондовом рынке. Алгоритм моделирует процесс торговли акциями, где участники рынка с разным уровнем успеха применяют различные стратегии для максимизации прибыли.
В продолжение нашей работы по упрощению взаимодействия с поведением цены мы рады представить еще один инструмент, который может значительно улучшить ваш анализ рынка и помочь вам принимать обоснованные решения. Этот инструмент отображает ключевые технические индикаторы, такие как цены предыдущего дня, значимые уровни поддержки и сопротивления, а также торговый объем, автоматически генерируя визуальные подсказки на графике.
CatBoost – это эффективная модель машинного обучения на основе деревьев, которая специализируется на принятии решений на основе статических признаков. Другие модели на основе деревьев, такие как XGBoost и Random Forest, обладают схожими характеристиками в плане надежности, интерпретируемости и способности работать со сложными паттернами. Эти модели имеют широкий спектр применения: от анализа признаков до управления рисками. В данной статье мы пройдемся по процедуре использования обученной модели CatBoost в качестве фильтра для классической трендовой стратегии на основе пересечения скользящих средних.
Подробное руководство по созданию индикатора тепловой карты для MetaTrader 5, который визуализирует временное распределение цены в виде тепловой карты. Статья раскрывает математическую основу анализа временной плотности, где каждый ценовой уровень окрашивается от красного (минимальное время пребывания) до синего (максимальное время пребывания).
Temporal Difference (TD, временные различия) — еще один алгоритм обучения с подкреплением, который обновляет Q-значения на основе разницы между прогнозируемыми и фактическими вознаграждениями во время обучения агента. Особое внимание уделяется обновлению Q-значений без учета их пар "состояние-действие" (state-action). Как обычно, мы рассмотрим, как этот алгоритм можно применить в советнике, собранном с помощью Мастера.
Статья объясняет, как разработать инструмент для анализа повторяющихся ценовых закономерностей на финансовых рынках — по дням месяца (1-31), дням недели (понедельник-воскресенье) или часам дня (0-23). Индикатор анализирует исторические данные, вычисляет среднюю доходность для каждого периода и отображает результаты в виде гистограммы с прогнозом. Включает настраиваемые параметры: тип сезонности, количество анализируемых баров, отображение в процентах или абсолютных значениях, цвета графиков.
Что если алгоритм оптимизации мог бы помнить свои прошлые путешествия и использовать эту память для поиска лучших решений? BSA делает именно это — балансируя между исследованием нового и возвращением к проверенному. В статье раскрываем секреты алгоритма. Простая идея, минимум параметров и стабильный результат.
На протяжении десятилетий трейдеры использовали формулу критерия Келли для определения оптимальной доли капитала, которую можно направить на инвестиции или ставки, чтобы максимизировать долгосрочный рост при минимизации риска разорения. Однако слепое следование критерию Келли, основанному на результатах единственного бэк-тестирования, часто опасно для отдельных трейдеров, поскольку при реальной торговле торговое преимущество со временем тает, а прошлые результаты не являются предиктором будущих результатов. В настоящей статье я представлю реалистичный подход к применению критерия Келли для распределения рисков одного или нескольких советников в MetaTrader 5, основанный на результатах моделирования методом Монте-Карло с помощью Python.
Анализ временных разрывов (таймгэпов) помогает трейдеру выявлять потенциальные точки разворота рынка. В статье рассматривается, что такое таймгэп, как его интерпретировать, а также каким образом с его помощью можно обнаружить вливание крупного объема в рынок.
В этой статье мы подробно рассмотрим алгоритм DEA — метаэвристический метод оптимизации, вдохновленный уникальной способностью дельфинов находить добычу с помощью эхолокации. От математических основ до практической реализации на MQL5, от анализа до сравнения с классическими алгоритмами — детально разберем, почему этот относительно молодой метод заслуживает места в арсенале тех, кто сталкивается с задачами оптимизации.
Исследуем один из самых интересных алгоритмов без градиентной оптимизации, который учится понимать геометрию целевой функции. Рассмотрим классическую реализацию CMA-ES с небольшой модификацией — заменой нормального распределения на степенное. Детальный разбор математики алгоритма, практическая реализация и честный анализ: где CMA-ES непобедим, а где его лучше не применять.
Алгоритмическая торговая система, сочетающая анализ объема с методами машинного обучения, в частности с нейронными сетями LSTM. В отличие от традиционных торговых подходов, которые в первую очередь фокусируются на движении цен, эта система делает упор на паттернах объема и их производных для прогнозирования движений рынка. Методология включает в себя три основных компонента: анализ производных от объема (первые и вторые производные), прогнозы LSTM для паттернов объема и традиционные технические индикаторы.
В настоящей статье мы представляем реализацию поэтапного отбора признаков на MQL5, основанную на взаимной информации между оптимальным набором предикторов и целевой переменной.
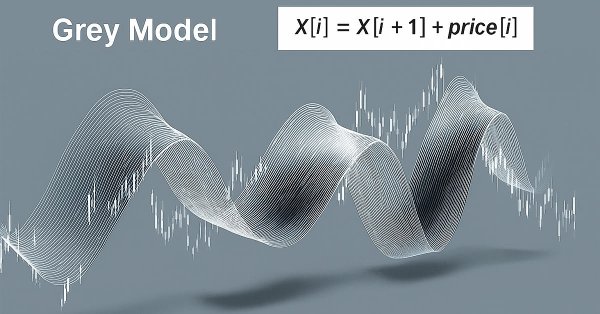
Данная статья посвящена изучению grey-модели — перспективного инструмента, способного расширить возможности трейдера. Мы рассмотрим некоторые варианты применения этой модели для технического анализа и построения торговых стратегий.
Создание системы анализа валютных курсов на основе паритета покупательной способности (ППС) на Python. Автор разработал алгоритм с 5 методами расчета справедливых курсов, используя данные МВФ. Практическое руководство по фундаментальному анализу валют, обработке экономических данных и интеграции с торговыми системами. Полный код в open source.
В данной статье предпринята попытка рассмотрения финансовых временных рядов с точки зрения самоподобных фрактальных структур. Поскольку мы имеем слишком много аналогий, которые подтверждают возможность рассматривать рыночные котировки в качестве самоподобных фракталов, то имеем возможность составить представления о горизонтах прогнозирования таких структур.
На форуме MQL5 есть множество сообщений с просьбами помочь рассчитать угол наклона изменения цены. В этой статье мы рассмотрим один из способов расчета наклона изменения цены. Этот способ применим на любом рынке. Кроме того, мы определим, стоит ли разработка этой новой функции дополнительных усилий и времени. Выясним, может ли угол наклона цены улучшить точность нашей AI-модели при прогнозировании пары USDZAR на минутном таймфрейме.
Eagle Strategy — алгоритм, имитирующий двухфазную охотничью стратегию орла: глобальный поиск через полеты Леви методом Мантенья, чередуется с интенсивной локальной эксплуатацией светлячкового алгоритма, математически обоснованный подход к балансу между исследованием и эксплуатацией, а также биоинспирированная концепция, объединяющая два природных феномена в единый вычислительный метод.
Ichimuko Kinko Hyo — известный японский индикатор, представляющий собой систему определения тренда. Как и в предыдущих статьях, мы рассмотрим этот индикатор с использованием паттернов и поделимся стратегиями и отчетами о тестировании, применив классы библиотеки Мастера MQL5.
Загрузка данных Международного валютного фонда на Python: добываем данные IMF для применения в макроэкономических валютных стратегиях. Как макроэкономика может помочь трейдеру и алготрейдеру?
В этой статье мы расскажем о некоторых деталях и мерах предосторожности, которые следует учитывать при создании протокола связи. Это довольно простые и понятные вещи, так что мы не будем слишком углубляться в эту статью. Но чтобы понять, что произойдет у получателя, нужно разобраться в содержании статьи.
В этой статье мы детально рассмотрим класс управления сделками, включив в него ордера buy stop и sell stop для торговли новостными событиями, а также введем ограничение срока действия этих ордеров, чтобы предотвратить переносы торговли на следующий день. В советник будет встроена функция проскальзывания, которая попытается предотвратить или минимизировать возможное проскальзывание, которое может возникнуть при использовании стоп-ордеров в торговле, особенно во время выхода новостей.
В этой статье мы представляем модифицированную версию поэтапного отбора признаков, реализованную в MQL5. Настоящий подход основан на методах, описанных Тимоти Мастерсом (Timothy Masters) в работе "Современных алгоритмах интеллектуального анализа данных на C++" и "CUDA C".
Управление рисками торгового счета является сложной задачей для всех трейдеров. Можем ли мы разработать торговые приложения, которые динамически изучают режимы высокого, среднего и низкого риска для различных символов в MetaTrader 5? Используя PCA, мы получаем лучший контроль над дисперсией портфеля. Я продемонстрирую, как создавать приложения, которые изучают эти три режима риска на основе рыночных данных, полученных из MetaTrader 5.
Оптимизация на основе биогеографии (BBO) — элегантный метод глобальной оптимизации, вдохновленный природными процессами миграции видов между островами архипелагов. В основе алгоритма лежит простая, но мощная идея: решения с высоким качеством активно делятся своими характеристиками, решения низкого качества активно заимствуют новые черты, создавая естественный поток информации от лучших решений к худшим. Уникальный адаптивный оператор мутации, обеспечивает превосходный баланс между исследованием и эксплуатацией, BBO демонстрирует высокую эффективность на различных задачах.
В настоящей статье мы рассмотрим основы гауссовских процессов (ГП) как вероятностную модель машинного обучения и продемонстрируем ее применение в регрессионных задачах на примере синтетических данных.
В этой статье мы рассмотрим, как работает недостающий код из предыдущей статьи, DispatchMessage. Здесь мы введем тему следующей статьи. По этой причине важно понять, как работает данная процедура, прежде чем переходить к следующей теме. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте это приложение как окончательное, цели которого будут иные, кроме изучения представленных концепций.
Скользящие средние являются, безусловно, самыми эффективными индикаторами для прогнозирования моделями ИИ. Однако точность результатов можно еще больше повысить, если перед этим соответственным образом преобразовать данные. В этой статье мы поговорим о создании AI-моделей, которые могут прогнозировать в более отдаленное будущее без существенного снижения уровня точности. В очередной раз мы с вами убедимся, насколько полезны скользящие средние.
В этой статье мы расскажем о классе C_ChartFloatingRAD. Это то, что позволяет Chart Trade работать. Однако на этом объяснение не закончится. Мы завершим его в следующей статье, так как содержание данной статьи довольно объемное и требует глубокого понимания. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
Python-пакет MetaTrader 5 предлагает простой способ создания торговых приложений для платформы MetaTrader 5 на языке Python. Будучи мощным и полезным инструментом данный модуль не так прост как язык программирования MQL5, когда дело касается разработки решений для алгоритмической торговли. В данной статье мы создадим классы для торговли, аналогичные предлагаемым в языке MQL5, чтобы создать схожий синтаксис и сделать разработку торговых роботов на Python такой же простой как и на MQL5.
В этой статье мы изменим последний код, показанный в данной серии о Chart Trade. Эти изменения необходимы, чтобы адаптировать код к текущей модели системы репликации/моделирования. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
Настоящий проект направлен на использование алгоритма MQL5 для разработки комплексного набора инструментов анализа для MetaTrader 5. Эти инструменты — от скриптов и индикаторов до моделей искусственного интеллекта и советников — позволят автоматизировать процесс анализа рынка. Иногда такая разработка позволяет создавать инструменты, способные выполнять углубленный анализ без участия человека и прогнозировать результаты на соответствующих платформах. Ни одна возможность не будет упущена. Присоединяйтесь ко мне в рамках исследования процесса создания надежного набора пользовательских инструментов для анализа рынка. Начнем с разработки простой программы на MQL5, которую я назвал Chart Projector (Проектор графиков).
В статье рассматривается реализация модифицированного алгоритма анализа компонентов прямого отбора, вдохновленного исследованиями, представленными в книге Луки Пуггини (Luca Puggini) и Шона Маклуна (Sean McLoone) “Анализ компонентов прямого отбора: алгоритмы и приложения”.
Попробуем смайнить даные CFTC, загрузить отчеты COT и TFF через Python, соединить это с котировками MetaTrader 5 и моделью ИИ и получить прогнозы. Что такое отчеты COT на рынке Форекс? Как использовать отчеты COT и TFF для прогнозирования?
Майнинг данных балансов центробанков позволяет получить картину мировой ликвидности рынка Форекс и ключевых валют. Мы объединяем данные ФРС, ЕЦБ, BOJ и PBoC в композитный индекс и применяем машинное обучение для выявления скрытых закономерностей. Такой подход превращает сырой поток данных в реальные торговые сигналы, соединяя фундаментальный и технический анализ.