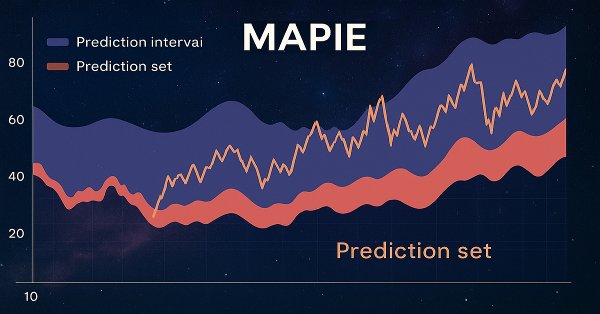
В этой статье вы познакомитесь с конформными предсказаниями и библиотекой MAPIE, которая их реализует. Данный подход является одним из самых современных в машинном обучении и позволяет сосредоточиться на контроле рисков для уже существующих разнообразных моделей машинного обучения. Конформные предсказания, сами по себе, не являются способом поиска закономерностей в данных. Они лишь определяют степень уверенности существующих моделей в предсказании конкретных примеров и позволяют фильтровать надежные предсказания.
Осциллятор ATR — очень популярный индикатор, используемый в качестве индикатора волатильности, особенно на валютных рынках, где данные об объемах скудны. Как и в случае с предыдущими индикаторами, мы рассмотрим паттерны и поделимся стратегиями и отчетами о тестировании.
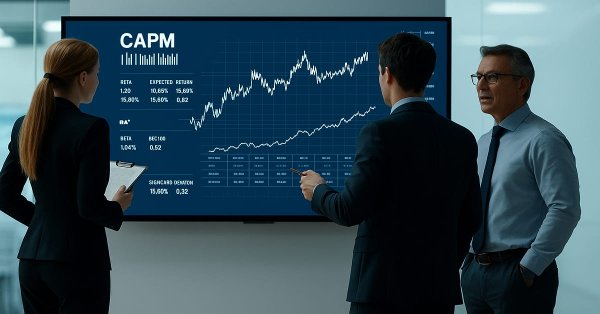
Адаптация классической модели CAPM для валютного рынка Forex в MQL5. Индикатор рассчитывает ожидаемую доходность и премию за риск на основе исторической волатильности. Показатели возрастают на пиках и впадинах, отражая фундаментальные принципы ценообразования. Практическое применение для контртрендовых и трендовых стратегий с учетом динамики соотношения риска и доходности в реальном времени. Включает математический аппарат и техническую реализацию.
В данной статье мы создаем индикатор прогнозирования ARIMA на MQL5. Рассматривается, как модель ARIMA формирует прогнозы, её применимость к рынку Форекс и фондовому рынку в целом. Также объясняется, что такое авторегрессия AR, каким образом авторегрессионные модели используются для прогнозирования, и как работает механизм авторегрессии.
Модели искусственного интеллекта CatBoost приобрели огромную популярность в сообществе машинного обучения благодаря их точности прогнозирования, эффективности и устойчивости к разрозненным и сложным наборам данных. В этой статье речь будет идти о том, как использовать эти модели применительно к рынку Форекс.
Алгоритм Deterministic Oscillatory Search (DOS) — инновационный метод глобальной оптимизации, сочетающий преимущества градиентных и роевых алгоритмов без использования случайных чисел. Механизм осцилляций и наклонов фитнеса позволяет DOS исследовать сложные пространства поиска детерминированным методом.
SARSA (State-Action-Reward-State-Action, состояние-действие-вознаграждение-состояние-действие) — еще один алгоритм, который можно использовать при реализации обучения с подкреплением. Рассмотрим, как можно реализовать этот алгоритм в качестве независимой модели (а не просто механизма обучения) в советниках, собранных в Мастере, аналогично тому, как мы это делали в случаях с Q-обучением и DQN.
В настоящей статье мы обсудим и продемонстрируем, как преобразовать номинальные предикторы в числовые форматы, подходящие для алгоритмов машинного обучения, используя как Python, так и MQL5.
В этой статье будут рассмотрены методы улучшения работы советника в тестере стратегий, будет написан код для разделения времени новостных событий на почасовые категории. Доступ к этим новостным событиям будет осуществляться в течение указанного для них часа. Это гарантирует, что советник может эффективно управлять сделками на основе событий как в условиях высокой, так и низкой волатильности.
Самообучающийся советник с нейросетью на матрице состояний. Совмещаем марковские цепи с многослойной нейросетью MLP, написанной на библиотеке ALGLIB MQL5. Как могут быть совмещены для прогнозирования Форекс марковские цепи и нейросети?
Фильтр Калмана представляет собой рекурсивный алгоритм, применяемый в алготрейдинге для оценки истинного состояния финансового временного ряда посредством фильтрации шума из движения цен. Он динамически обновляет прогнозы на основе новых рыночных данных, что делает его ценным для таких адаптивных стратегий, как возвратные. В этой статье впервые представлен фильтр Калмана, а также рассмотрены его расчет и реализация. Кроме того, в качестве примера мы применим этот фильтр к классической возвратной форекс-стратегии. Наконец, проведем различные виды статистического анализа, сравнивая фильтр со скользящей средней на различных валютных парах.
Создаем матричную модель прогнозирования на марковской цепи. Что такое марковские цепи, и как можно использовать марковскую цепь для трейдинга на Форекс.
В этой статье мы рассмотрим расширенную визуализацию данных, включая такие функции, как интерактивность, многослойные данные и динамические элементы, позволяющие трейдерам более эффективно изучать тренды, закономерности и корреляции.
Прогнозирование движений валютных пар является важным фактором успеха в трейдинге. Данная статья посвящена исследованию различных моделей движения цены, анализу их преимуществ и недостатков, а также практическому применению в торговых стратегиях. Мы рассмотрим подходы, позволяющие выявлять скрытые закономерности и повышать точность прогнозов.
Политика «решения проблем» может создать четкую программу для овладения сложными навыками, такими как программирование на MQL5. Такой подход позволяет сконцентрироваться на решении проблем, одновременно развивая свои навыки. Чем больше проблем вы решаете, тем более продвинутый опыт передается в ваш мозг. Лично я считаю, что отладка - это самый эффективный способ освоить программирование. Сегодня мы рассмотрим процесс очистки кода и обсудим лучшие методы преобразования запутанной программы в ясную и функциональную. Прочтите эту статью и откройте для себя ценную информацию.
Компьютерное зрение для трейдинга, как работает и как разрабатывается по шагам. Создаем алгоритм распознавания RGB-изображений графиков цен с механизмом внимания и двунаправленным LSTM-слоем. В результате получаем рабочую модель прогнозирования цены евро-доллара с точностью до 55% на валидационном участке.
Алгоритм верблюда, разработанный в 2016 году, моделирует поведение верблюдов в пустыне для решения оптимизационных задач, учитывая факторы температуры, запасов и выносливости. В данной работе представлена еще его модифицированная версия (CAm) с ключевыми улучшениями: применение гауссова распределения при генерации решений и оптимизация параметров эффекта оазиса.
В этой статье мы рассмотрим динамическую интеграцию сверточных нейронных сетей (CNN) и рекуррентных нейронных сетей (RNN) для задач прогнозирования фондового рынка. Для этого соединим способность CNN извлекать закономерности и эффективность RNN в обработке последовательных данных. Давайте посмотрим, как такая мощная комбинация может повысить точность и эффективность торговых алгоритмов.
В статье рассматривается непараметрический статистический тест HSIC (Hilbert-Schmidt Independence Criterion) предназначенный для выявления линейных и нелинейных зависимостей в данных. Предложены реализации двух алгоритмов вычисления HSIC на языке MQL5: точного перестановочного теста и гамма-аппроксимации. Эффективность метода демонстрируется на синтетических данных, моделирующих нелинейную связь признаков и целевой переменной.
Что такое количественный анализ трендов на рынке Форекс. Собираем статистику по трендам, их величине и распределению по валютной паре EURUSD. Как количественный анализ трендов поможет создать прибыльный торговый советник.
Мы применим простую цепь Маркова к индикатору RSI, чтобы наблюдать за поведением цены после того, как индикатор проходит через ключевые уровни. Мы пришли к выводу, что самые сильные сигналы на покупку и продажу по паре NZDJPY генерируются, когда RSI находится в диапазоне 11–20 и 71–80 соответственно. Мы покажем, как можно манипулировать данными, чтобы создавать оптимальные торговые стратегии, основанные непосредственно на имеющихся данных. Кроме того, мы продемонстрируем, как обучить глубокую нейронную сеть оптимальному использованию матрицы перехода.
Скрытые марковские модели (СММ) представляют собой мощный класс вероятностных моделей, предназначенных для анализа последовательных данных, где наблюдаемые события зависят от некоторой последовательности ненаблюдаемых (скрытых) состояний, которые формируют марковский процесс. Основные предположения СММ включают марковское свойство для скрытых состояний, означающее, что вероятность перехода в следующее состояние зависит только от текущего состояния, и независимость наблюдений при условии знания текущего скрытого состояния.
Новый метаэвристический метод, основанный на фрактальном подходе к разделению пространства поиска для решения задач оптимизации. Алгоритм последовательно идентифицирует и разделяет перспективные области, создавая самоподобную фрактальную структуру, которая концентрирует вычислительные ресурсы на наиболее перспективных участках. Уникальный механизм мутации, направленный в сторону лучших решений, обеспечивает оптимальный баланс между исследованием и использованием пространства поиска, значительно повышая эффективность алгоритма.
Статья содержит детальное описание алгоритма расчета кросс-курсов, визуализацию матрицы дисбалансов и рекомендации по оптимальной настройке параметров MinDiscrepancy и MaxRisk для эффективной торговли. Система автоматически рассчитывает "справедливую стоимость" каждой валютной пары через кросс-курсы, генерируя сигналы на покупку при отрицательных отклонениях, и на продажу — при положительных.
Система прогнозирования EURUSD с применением компьютерного зрения и глубокого обучения. Узнайте, как сверточные нейронные сети могут распознавать сложные ценовые паттерны на валютном рынке и предсказывать движение курса с точностью до 54%. Статья раскрывает методологию создания алгоритма, использующего технологии искусственного интеллекта для визуального анализа графиков вместо традиционных технических индикаторов. Автор демонстрирует процесс трансформации ценовых данных в «изображения», их обработку нейронной сетью и уникальную возможность заглянуть в «сознание» ИИ через карты активации и тепловые карты внимания. Практический код на Python с использованием библиотеки MetaTrader 5 позволяет читателям воспроизвести систему и применить ее в собственной торговле.
Продолжение исследования алгоритма хаотической оптимизации. Вторая часть статьи посвящена практическим аспектам реализации алгоритма, его тестированию и выводам.
Как использовать Ренко-бары вместе с ИИ? Рассмотрим Ренко-трейдинг на Форекс с точностью прогнозов до 59.27%. Исследуем преимущества Ренко-баров для фильтрации рыночного шума, узнаем, почему объемные показатели важнее ценовых паттернов, и как настроить оптимальный размер блока Ренко для EURUSD. Пошаговое руководство по интеграции CatBoost, Python и MetaTrader 5 для создания собственной системы прогнозирования Ренко Форекс. Идеально для трейдеров, стремящихся выйти за рамки традиционного технического анализа.
Усовершенствованный алгоритм хаотической оптимизации (COA), объединяющий воздействие хаоса с адаптивными механизмами поиска. Алгоритм использует множество хаотических отображений и инерционные компоненты для исследования пространства поиска. Статья раскрывает теоретические основы хаотических методов финансовой оптимизации.
Модели машинного обучения имеют различные настраиваемые параметры. В этой серии статей мы рассмотрим, как настроить ИИ-модели в соответствии с конкретным рынком с помощью библиотеки SciPy.
В этой статье разберем, что такое парный трейдинг и как происходит торговля на корреляциях. Также создадим советник для автоматизации парного трейдинга и добавим возможность автоматической оптимизации такого торгового алгоритма на исторических данных. Кроме того, в рамках проекта узнаем, как рассчитывать расхождения двух пар с помощью z-оценки.
Статья рассматривает теоретические и практические аспекты метода сингулярного спектрального анализа (SSA), который представляет собой эффективный метод анализа временных рядов, позволяющий представить сложную структуру ряда в виде разложения на простые компоненты, такие как тренд, сезонные (периодические) колебания и шум.
Что такое угловой анализ финансовых рынков? Как использовать углы движения цен и машинное обучение для точного прогнозирования с точностью 67? Как совместить регрессионную и классификационную модель с угловыми признаками и получить работающий алгоритм? Причем тут Ганн? Почему углы движения цен являются хорошим признаком для машинного обучения?
В данной статье представлен комплексный анализ алгоритма оптимизации коралловых рифов (CRO) — метаэвристического метода, вдохновленного биологическими процессами формирования и развития коралловых рифов. Алгоритм моделирует ключевые аспекты эволюции кораллов: внешнее и внутреннее размножение, оседание личинок, бесполое размножение и конкуренцию за ограниченное пространство в рифе. Особое внимание в работе уделяется усовершенствованной версии алгоритма.
В данной статье продемонстрирован подход к созданию торговых стратегий для золота с помощью машинного обучения. Рассматривая предложенный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов.
Определяем перекупленность и перепроданность рынка по теории хаоса: интеграция принципов теории хаоса, фрактальной геометрии и нейронных сетей для прогнозирования финансовых рынков. Исследование демонстрирует применение показателя Ляпунова, как меры рыночной хаотичности, и динамическую адаптацию торговых сигналов. Методология включает алгоритм генерации фрактального шума, гиперболическую тангенциальную активацию и оптимизацию с моментом.
Статья разбирает алгоритм Battle Royale Optimizer — метаэвристику, в которой решения конкурируют с ближайшими соседями, накапливают “повреждения”, заменяются при превышении порога и периодически сужают пространство поиска вокруг лучшего. Показаны псевдокод и реализация класса CAOBRO в MQL5, включая поиск соседей, движение к лучшему и адаптивный интервал delta. Результаты тестов на функциях Hilly, Forest и Megacity демонстрируют сильные и слабые стороны подхода. Читатель получает готовую основу для экспериментов и настройки popSize и maxDamage.
В настоящей статье рассматривается алгоритм отбора признаков, представленный в статье "Выбор локальных признаков для классификации данных» ('Local Feature Selection for Data Classification') Наргеса Арманфарда и соавторов (Narges Armanfard et al.). Алгоритм реализован на Python для построения моделей бинарных классификаторов, которые могут быть интегрированы с приложениями MetaTrader 5 для логического вывода.
В данной статье рассматривается подход к торговле только в выбранном направлении (на покупку или на продажу). Для этого используется техника причинно-следственного вывода и машинное обучение.
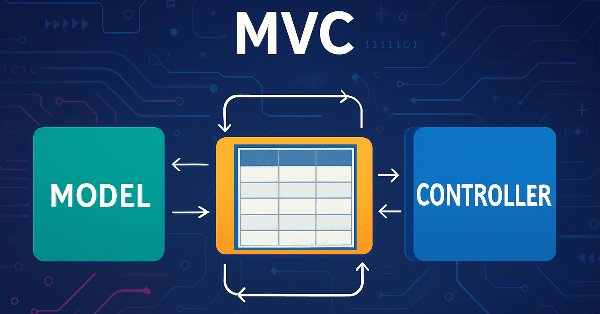
В статье рассмотрим процесс разработки модели таблицы на языке MQL5 с использованием архитектурной концепции MVC (Model-View-Controller) для разделения логики данных, представления и управления, что помогает создавать структурированный, гибкий и масштабируемый код. Рассмотрим реализацию классов для построения модели таблицы, включая использование связанных списков для хранения данных.
Новый авторский алгоритм оптимизации NOA2 (Neuroboids Optimization Algorithm 2), объединяет принципы роевого интеллекта с нейронным управлением. NOA2 сочетает механику поведения стаи нейробоидов с адаптивной нейронной системой, позволяющей агентам самостоятельно корректировать свое поведение в процессе поиска оптимума. Алгоритм находится на стадии активной разработки и демонстрирует потенциал для решения сложных задач оптимизации.