Подбор группы экземпляров торговых стратегий с целью улучшения результатов при их совместной работы мы прежде оценивали только на том же временном периоде, на котором проводилась оптимизация отдельных экземпляров. Давайте посмотрим, что получится на форвард-периоде.
Статья призвана продемонстрировать факт появления ложной регрессии при попытках применить регрессионный анализ к нестационарным процессам с помощью моделирования по методу Монте-Карло.
В статье исследуется алгоритм BSA, основанный на поведении птиц, который вдохновлен коллективным стайным взаимодействием птиц в природе. Различные стратегии поиска индивидов в BSA, включая переключение между поведением в полете, бдительностью и поиском пищи, делают этот алгоритм многоаспектным. Он использует принципы стайного поведения, коммуникации, адаптивности, лидерства и следования птиц для эффективного поиска оптимальных решений.
Разработка торгового робота на основе машинного обучения: подробное руководство. В первой статье цикла осуществлен сбор и подготовка данных и признаков. Для реализации проекта используется язык программирования Python и библиотеки, а также платформа MetaTrader 5.
Алгоритмы кластеризации в машинном обучении — это важные алгоритмы обучения без учителя, которые позволяют разделять исходные данные на группы с похожими наблюдениями. Используя эти группы, можно проводить анализ рынка для конкретного кластера, искать наиболее устойчивые кластеры на новых данных, а также делать причинно-следственный вывод. В статье предложен авторский метод кластеризации временных рядов на языке Python.
Перцептроны, сети с одним скрытым слоем, могут стать хорошим подспорьем для тех, кто знаком с основами автоматической торговли и хочет окунуться в нейронные сети. Мы шаг за шагом рассмотрим, как их можно реализовать в сборке классов сигналов, которая является частью классов Мастера MQL5 для советников.
В этой статье мы рассмотрим генератор случайных чисел Mersenne Twister и сравним со стандартным в MQL5. Узнаем влияние качества случайных чисел генераторов на результаты алгоритмов оптимизации.
В статье показана реализация комбинаторно-симметричной перекрестной проверки на чистом MQL5 для измерения степени подгонки после оптимизации стратегии с использованием медленного полного алгоритма тестера стратегий.
В этой статье мы разберем, какую роль метод опорных векторов (Support Vector Machines, SVM) играет в формировании будущего трейдинга. Статью можно рассматривать как подробное руководством, которое рассказывает, как с помощью SVM улучшить торговые стратегии, оптимизировать процесс принятия решений и открыть новые возможности на финансовых рынках. Вы погрузитесь в мир SVM через реальные приложения, пошаговые инструкции и экспертные оценки. Возможно, этот незаменимый инструмент поможет разобраться в сложностях современной торговли. В любом случае SVM станет очень полезным инструментом в арсенале каждого трейдера.
В статье мы погрузимся в мир гибридизации алгоритмов оптимизации, рассмотрев три ключевых типа: смешивание стратегий, последовательную и параллельную гибридизации. Мы проведем серию экспериментов, сочетая и тестируя соответствующие алгоритмы оптимизации.
Продолжение эксперимента, цель которого - исследовать поведение популяционных алгоритмов оптимизации в контексте их способности эффективно покидать локальные минимумы при низком разнообразии в популяции и достигать глобальных максимумов. Результаты исследования.
Из всего, что было разработано до настоящего момента, данная система, как вы наверняка заметите и со временем согласитесь, - является самым сложным. Сейчас нам нужно сделать нечто очень простое: заставить нашу систему имитировать работу торгового сервера на практике. Эта необходимость точно реализовывать способ моделирования действий торгового сервера кажется простым делом. По крайней мере, на словах. Но нам нужно сделать это так, чтобы для пользователя системы репликации/моделирования всё происходило как можно более незаметно или прозрачно.
Разрабатывать способ установки таймера необходимо таким образом, чтобы во время репликации/моделирования он мог сообщить нам, сколько времени осталось, что может показаться на первый взгляд простым и быстрым решением. Многие просто пытаются приспособиться и использовать ту же систему, что и в случае с торговым сервером. Но есть один момент, который многие не учитывают, когда думают о таком решении: при репликации, и это не говоря уже о моделировании, часы работают по-другому. Всё это усложняет создание подобной системы.
Сегодня мы изучим технику, которая может очень сильно помочь нам на разных этапах нашей профессиональной жизни в качестве программиста. Вопреки мнению многих, ограничена не сама платформа, а знания человека, который говорит об ограничениях. В данной статье будет рассказано о том, что с помощью здравого смысла и творческого подхода можно сделать платформу MetaTrader 5 гораздо более интересной и универсальной, не прибегая к созданию безумных программ или чего-то подобного, и создать простой, но безопасный и надежный код. Мы будем использовать свою изобретательность, чтобы изменить уже существующий код, не удаляя и не добавляя ни одной строки в исходный код.
Эта статья представляет уникальный эксперимент, цель которого - исследовать поведение популяционных алгоритмов оптимизации в контексте их способности эффективно покидать локальные минимумы при низком разнообразии в популяции и достигать глобальных максимумов. Работа в этом направлении позволит глубже понять, какие конкретные алгоритмы могут успешно продолжать поиск из координат, установленных пользователем в качестве отправной точки, и какие факторы влияют на их успешность в этом процессе.
Классификация данных для анализа и прогнозирования — очень разнообразная область машинного обучения с большим количеством подходов и методов. В этой статье рассматривается один из таких подходов, а именно агломеративная иерархическая классификация (Agglomerative Hierarchical Classification).
После улучшения класса C_Mouse, мы можем сосредоточиться на создании класса, призванного создать совершенно новую основу для обучения. Как уже упоминалось в начале статьи, мы не будем использовать наследование или полиморфизм для создания этого нового класса. Вместо этого мы изменим, а точнее, добавим новые объекты в ценовую линию. Именно этим мы и займемся в данный момент, а в следующей статье мы рассмотрим, как изменить исследования. Но мы сделаем всё это, не меняя код класса C_Mouse. Признаюсь, на практике было бы легче достичь этого с помощью наследования или полиморфизма. однако существуют и другие методы достижения такого же результата.
Уникальная исследовательская попытка объединения разнообразных популяционных алгоритмов в единый класс с целью упрощения применения методов оптимизации. Этот подход не только открывает возможности для разработки новых алгоритмов, включая гибридные варианты, но и создает универсальный базовый стенд для тестирования. Этот стенд становится ключевым инструментом для выбора оптимального алгоритма в зависимости от конкретной задачи.
В этой статье мы представляем алгоритм перестановки ценовых баров и подробно рассказываем, как тесты на перестановку (permutation tests) можно использовать для выявления случаев, когда эффективность стратегии была сфабрикована с целью обмануть потенциальных покупателей советников.
Погрузитесь в мир ONNX - мощного открытого формата для обмена моделями машинного обучения. Узнайте, как использование ONNX может произвести революцию в алгоритмической торговле на MQL5, позволяя трейдерам беспрепятственно интегрировать передовые модели искусственного интеллекта и поднять свои стратегии на новый уровень. Раскройте секреты кросс-платформенной совместимости и узнайте, как раскрыть весь потенциал ONNX в своей торговле на MQL5. Улучшите свою торговлю с помощью этого подробного руководства по ONNX.
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!
Когда начали создаваться первые системы, способные что-то считать, всё потребовало вмешательства инженеров, обладающих обширными знаниями о том, что проектируется. Мы говорим о рассвете компьютерной техники, о времени, когда не было даже терминалов, позволяющих что-либо программировать. По мере развития и роста интереса к тому, чтобы большее число людей могли создавать что-либо, появлялись новые идеи и методы программирования этих машин, которые раньше сводились к изменению положения соединителей. Именно тогда появились первые терминалы.
В этой статье мы продолжаем рассматривать популярные торговые индикаторы под новым углом. Мы собираемся обрабатывать горизонтальную композицию естественных преобразований. Лучшим индикатором для этого является двойная экспоненциальная скользящая средняя (Double Exponential Moving Average, DEMA).
В этой статье мы воплотим в жизнь класс C_Mouse. Он обеспечивает возможности программирования на самом высоком уровне. Однако разговоры о высокоуровневых или низкоуровневых языках программирования не связаны с включением в код нецензурных слов или жаргона. Всё наоборот. Когда мы говорим о высокоуровневом или низкоуровневом программировании, мы имеем в виду, насколько легко или сложно понять код другим программистам.
Мы уже можем начать создавать советника для использования в репликации/моделировании. Однако нам нужно нечто усовершенствованное, а не какое-то случайное решение. Несмотря на это, нас не должна пугать первоначальная сложность. Очень важно начать с чего-то, иначе в конечном итоге мы придем к тому, что размышляем о сложности задачи, даже не пытаясь ее преодолеть. Суть программирования именно в этом: преодолеть препятствия посредством изучения, тестирования и обширных исследований.
В этой статье мы представим реализацию нескольких показателей доходности и риска, рассматриваемых как альтернативы коэффициенту Шарпа, и исследуем гипотетические кривые капитала для анализа их характеристик.
В этой статье мы завершаем первый этап разработки системы репликации и моделирования. Дорогой читатель, этим достижением я подтверждаю, что система достигла продвинутого уровня, открывая путь для внедрения новой функциональности. Цель состоит в том, чтобы обогатить систему еще больше, превратив ее в мощный инструмент для исследований и развития анализа рынка.
Сегодня мы снимем ограничение, которое препятствовало выполнению моделирований, основанных на построении LAST, и введем новую точку входа специально для этого типа моделирования. Обратите внимание на то, что весь механизм работы будет основан на принципах валютного рынка. Основное различие в данной процедуре заключается в разделении моделирований BID и LAST. Однако важно отметить, что методология, используемая при рандомизации времени и его корректировке для совместимости с классом C_Replay, остается идентичной в обоих видах моделирования. Это хорошо, поскольку изменения в одном режиме приводят к автоматическим улучшениям в другом, особенно если это касается обработки времени между тиками.
В статье рассмотрим принцип построения многопопуляционных алгоритмов и в качестве примера такого вида алгоритмов разберём Эволюцию социальных групп (ESG), новый авторский алгоритм. Мы проанализируем основные концепции, механизмы взаимодействия популяций и преимущества этого алгоритма, а также рассмотрим его производительность в задачах оптимизации.
Эта статья, 21-я в нашей серии, продолжает рассмотрение естественных преобразований и того, как их можно реализовать с помощью линейного дискриминантного анализа. Как и в предыдущей статье, реализация представлена в формате класса сигнала.
В этой статье мы рассмотрим теорию причинно-следственного вывода с применением машинного обучения, а также реализацию авторского подхода на языке Python. Причинно-следственный вывод и причинно-следственное мышление берут свои корни в философии и психологии, это важная часть нашего способа мыслить эту реальность.
В этой статье мы рассмотрим бинарный генетический алгоритм (BGA), который моделирует естественные процессы, происходящие в генетическом материале у живых существ в природе.
В этой статье мы проведем исследование различных методов, применяемых в бинарных генетических алгоритмах и других популяционных алгоритмах. Мы рассмотрим основные компоненты алгоритма, такие как селекция, кроссовер и мутация, а также их влияние на процесс оптимизации. Кроме того, мы изучим способы представления информации и их влияние на результаты оптимизации.
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!
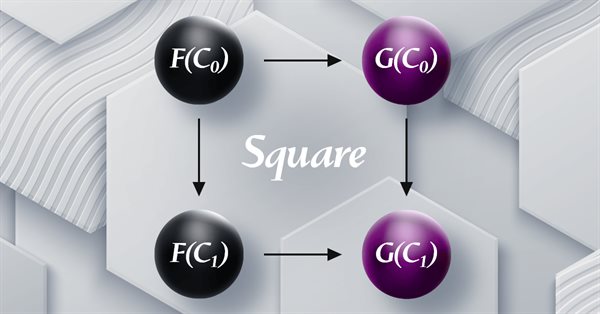
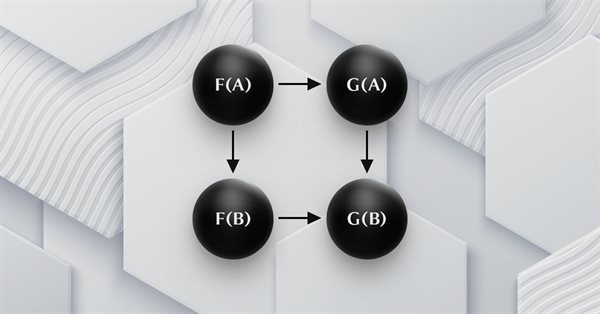
Мы продолжаем рассмотрение естественных преобразований, рассматривая квадратичную индукцию естественности. Небольшие ограничения на реализацию мультивалютности для экспертов, собранных с помощью мастера MQL5, означают, что мы демонстрируем свои возможности по классификации данных с помощью скрипта. В качестве основных областей применения рассматриваются классификация изменений цен и, соответственно, их прогнозирование.
Статья рассказывает о методе оптимизации, основанном на принципах функционирования иммунной системы организма — Micro Artificial Immune System (Micro-AIS) — модификацию AIS. Micro-AIS использует более простую модель иммунной системы и простые операции обработки иммунной информации. Статья также обсуждает преимущества и недостатки Micro-AIS по сравнению с обычным AIS.
В этой серии статей представлены несколько методов маркировки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая маркировка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!
В статье представлен новый подход к решению оптимизационных задач, путём объединения идей алгоритмов оптимизации бактериального поиска пищи (BFO) и приёмов, используемых в генетическом алгоритме (GA), в гибридный алгоритм BFO-GA. Он использует роение бактерий для глобального поиска оптимального решения и генетические операторы для уточнения локальных оптимумов. В отличие от оригинального BFO бактерии теперь могут мутировать и наследовать гены.
Статья продолжает серию о теории категорий, представляя естественные преобразования, которые являются ключевым элементом теории. Мы рассмотрим сложное на первый взгляд определение, затем углубимся в примеры и способы применения преобразований в прогнозировании волатильности.