
神经网络变得简单(第 67 部分):按照过去的经验解决新任务

神经网络变得简单(第 65 部分):距离加权监督学习(DWSL)
如何利用 MQL5 创建简单的多币种智能交易系统(第 4 部分):三角移动平均线 — 指标信号
神经网络变得简单(第 64 部分):保守加权行为克隆(CWBC)方法

神经网络变得简单(第 63 部分):决策转换器无监督预训练(PDT)
如何利用 MQL5 创建简单的多币种智能交易系统(第 3 部分):添加交易品种、前缀和/或后缀、以及交易时段

神经网络变得简单(第 62 部分):在层次化模型中运用决策转换器

神经网络变得简单(第 61 部分):离线强化学习中的乐观情绪问题
神经网络实验(第 7 部分):传递指标

神经网络变得简单(第 60 部分):在线决策转换器(ODT)

神经网络变得简单(第 59 部分):控制二分法(DoC)

神经网络变得简单(第 58 部分):决策转换器(DT)
如何利用 MQL5 创建简单的多币种智能交易系统(第 2 部分):指标信号:多时间帧抛物线 SAR 指标

神经网络变得简单(第 57 部分):随机边际扮演者-评论者(SMAC)
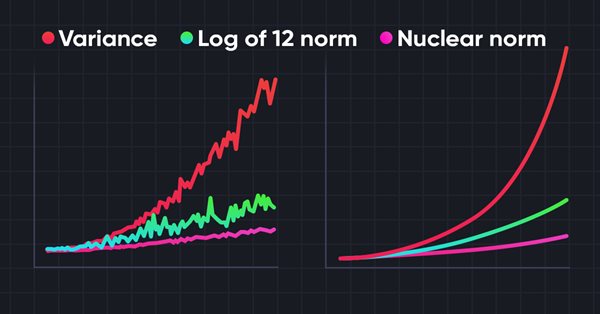
神经网络变得简单(第 56 部分):利用核范数推动研究
神经网络变得轻松(第五十五部分):对比内在控制(CIC)
将ML模型与策略测试器集成(结论):实现价格预测的回归模型

神经网络变得轻松(第五十四部分):利用随机编码器(RE3)进行高效研究
如何利用 MQL5 创建简单的多币种智能交易系统(第 1 部分):基于 ADX 指标的信号,并结合抛物线 SAR

神经网络变得轻松(第五十三部分):奖励分解

神经网络变得轻松(第五十二部分):研究乐观情绪和分布校正

神经网络变得轻松(第五十一部分):行为-指引的扮演者-评论者(BAC)
创建多交易品种、多周期指标

神经网络变得轻松(第五十部分):软性扮演者-评价者(模型优化)
MQL5中的替代风险回报标准
为EA交易提供指标的现成模板(第3部分):趋势指标
用置信区间估计未来效能

为EA交易提供指标的现成模板(第2部分):交易量和比尔威廉姆斯指标

神经网络变得轻松(第四十九部分):软性扮演者-评价者
模式搜索的暴力方法(第六部分):循环优化

了解使用MQL5下单

神经网络变得轻松(第四十八部分):降低 Q-函数高估的方法
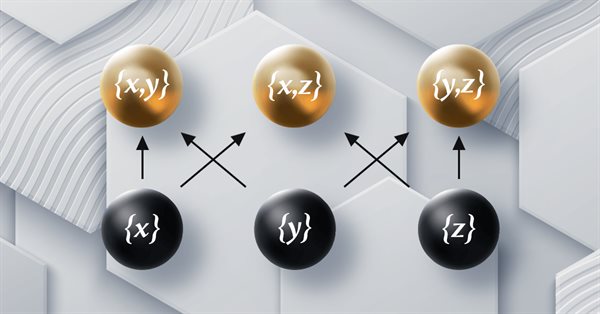
MQL5 中的范畴论 (第 12 部分):秩序(Orders)

MQL5 中的范畴论 (第 11 部分):图论

神经网络变得轻松(第四十七部分):连续动作空间
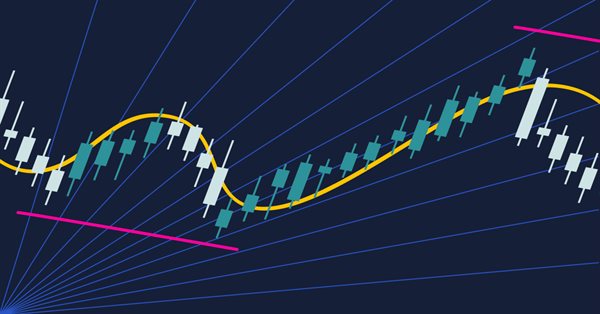
重新审视一种旧时的趋势交易策略:两个随机振荡指标,一个移动平均指标和斐波那契线

MQL5中的ALGLIB数值分析库
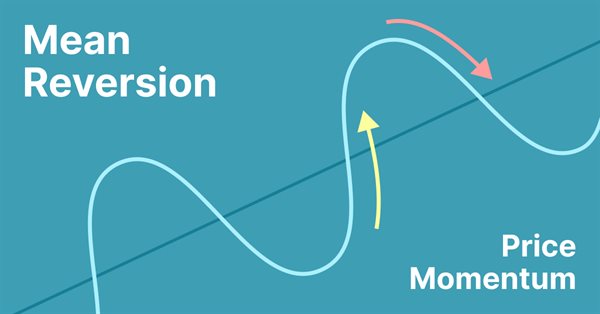
简单均值回归交易策略