构建自动运行的 EA(第 15 部分):自动化(VII)

构建自动运行的 EA(第 14 部分):自动化(VI)

构建自动运行的 EA(第 13 部分):自动化(V)

交易中的道义期望

创建综合性猫头鹰交易策略

构建自动运行的 EA(第 12 部分):自动化(IV)
重温默里(Murrey)系统

构建自动运行的 EA(第 11 部分):自动化(III)
学习如何基于鳄嘴(Gator)振荡器设计交易系统

构建自动运行的 EA(第 09 部分):自动化(II)

构建自动运行的 EA(第 09 部分):自动化(I)

构建自动运行的 EA(第 08 部分):OnTradeTransaction

构建自动运行的 EA(第 07 部分):账户类型(II)

构建自动运行的 EA(第 06 部分):账户类型(I)

构建自动运行的 EA(第 05 部分):手工触发器(II)

构建自动运行的 EA(第 04 部分):手工触发器(I)

构建自动运行的 EA(第 03 部分):新函数

构建自动运行的 EA(第 02 部分):开始编码
如何利用 MQL5 处理指示线
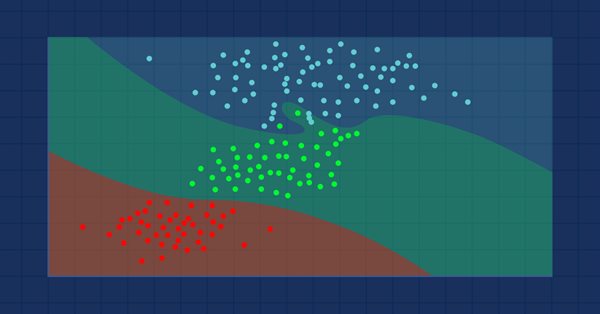
数据科学与机器学习(第 09 部分):K-最近邻算法(KNN)
创建一个行情卷播面板:基本版

帧分析器(Frames Analyzer)工具带来的时间片交易魔法
学习如何基于分形(Fractals)设计交易系统
学习如何基于鳄鱼(Alligator)设计交易系统
利用智能系统进行风险和资本管理
学习如何基于加速(Accelerator)振荡器设计交易系统
学习如何基于奥森姆(Awesome)振荡器设计交易系统
学习如何基于相对活力(Vigor)指数设计交易系统

从头开始开发智能交易系统(第 31 部分):面向未来((IV)

从头开始开发智能交易系统(第 29 部分):谈话平台
学习如何基于 DeMarker 设计交易系统
学习如何基于 VIDYA 设计交易系统

神经网络变得轻松(第二十六部分):强化学习

从头开始开发智能交易系统(第 28 部分):面向未来((III)

学习如何基于牛市力量设计交易系统

学习如何基于熊市力量设计交易系统

从头开始开发智能交易系统(第 27 部分):面向未来((II)

从头开始开发智能交易系统(第 26 部分):面向未来(I)