En el aprendizaje offline, utilizamos un conjunto de datos fijo, lo que limita la cobertura de la diversidad del entorno. Durante el proceso de aprendizaje, nuestro Agente puede generar acciones fuera de dicho conjunto. Si no hay retroalimentación del entorno, la corrección de las evaluaciones de tales acciones será cuestionable. Mantener la política del Agente dentro de la muestra de entrenamiento se convierte así en un aspecto importante para garantizar la solidez del entrenamiento. De eso hablaremos en este artículo.
En este trabajo, proponemos introducir un algoritmo que use operadores de mejora de políticas de forma cerrada para optimizar las acciones offline del Agente.
En trabajos anteriores, hemos introducido el método del Decision Transformer y varios algoritmos derivados de él. Asimismo, hemos experimentado con distintos métodos de fijación de objetivos. Durante los experimentos, hemos trabajado con distintas formas de fijar objetivos, pero el aprendizaje de la trayectoria ya recorrida por parte del modelo siempre quedaba fuera de nuestra atención. En este artículo, queremos presentar un método que llenará este vacío.
En este artículo, le propongo abordar la creación de una estrategia comercial desde una perspectiva diferente. Hoy no pronosticaremos los movimientos futuros de los precios, sino que trataremos de construir un sistema comercial basado en el análisis de datos históricos.
Este artículo trata el tema del emparejamiento en la inferencia causal. El emparejamiento se usa para emparejar observaciones similares en un conjunto de datos. Esto es necesario para identificar correctamente los efectos causales, eliminando el sesgo. Hoy explicaremos cómo esto ayuda a crear sistemas comerciales basados en el aprendizaje automático que se vuelven más robustos con nuevos datos en los que no se ha entrenado. El papel principal lo asignaremos a la puntuación de propensión, ampliamente utilizada en la inferencia causal.
En las partes anteriores, el Asesor Experto (EA) en desarrollo sólo podía utilizar un tamaño de posición fijo para operar. Esto es aceptable para las pruebas, pero no es aconsejable cuando se opera en una cuenta real. Hagamos posible el comercio utilizando tamaños de posición variables.
¿Podemos beneficiarnos de la estacionalidad al crear modelos para Deep Learning con Python? ¿Ayuda el filtrado de datos para los modelos ONNX a obtener mejores resultados? ¿Qué periodo de tiempo debemos utilizar? Trataremos todo esto a lo largo de este artículo.
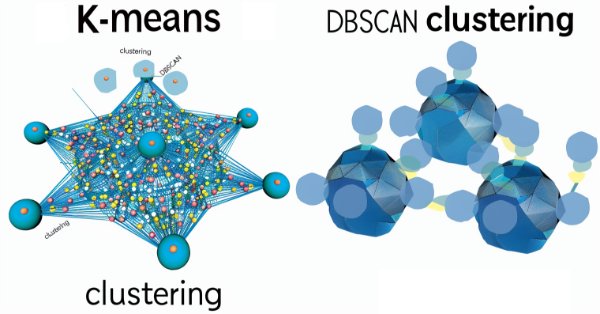
El agrupamiento basado en densidad para aplicaciones con ruido (DBSCAN) es una forma no supervisada de agrupar datos que apenas requiere parámetros de entrada, salvo solo 2, lo cual, en comparación con otros enfoques como k-means, es una ventaja. Profundizamos en cómo esto podría ser constructivo para probar y eventualmente operar con Asesores Expertos montados por Wizard MQL5.
Ya hemos avanzado bastante en el desarrollo del asesor multidivisa con varias estrategias funcionando en paralelo. Basándonos en nuestra experiencia, revisaremos la arquitectura de nuestra solución y trataremos de mejorarla antes de avanzar demasiado.
Hoy continuaremos con el desarrollo de un asesor multidivisa con varias estrategias funcionando en paralelo. Intentaremos transferir todo el trabajo relacionado con la apertura de posiciones de mercado desde el nivel de las estrategias al nivel de un experto que gestiona estas. Las propias estrategias solo negociarán virtualmente, sin abrir posiciones de mercado.
Existen bastantes estrategias comerciales distintas. Para diversificar los riesgos y aumentar la estabilidad de los resultados comerciales, puede resultar útil utilizar varias estrategias que funcionen en paralelo. Pero si cada estrategia se implementa como un asesor independiente, se hace mucho más difícil gestionar su trabajo conjunto en una cuenta comercial. Para resolver este problema, es deseable implementar el funcionamiento de diferentes estrategias de negociación en un asesor.
Tras empezar a desarrollar un EA multidivisa, ya hemos obtenido algunos resultados y hemos conseguido realizar varias iteraciones de mejora del código. Sin embargo, nuestro EA fue incapaz de trabajar con órdenes pendientes y reanudar la operación después del reinicio del terminal. Añadamos estas características.
Como se explicó en la parte teórica, necesitamos usar regresiones lineales y derivadas cuando trabajamos con redes neuronales. ¿Pero por qué? La razón es que la regresión lineal es una de las fórmulas más simples que existen. Básicamente, una regresión lineal es solo una función afín. Sin embargo, cuando hablamos de redes neuronales, no nos interesan los efectos de la recta de regresión lineal. Lo que nos interesa es la ecuación que genera dicha recta. La recta generada poco importa. ¿Pero sabes cuál es la ecuación principal que hay que comprender? Si no, lee este artículo para empezar a comprenderlo.
Los formatos de datos usados para representar modelos de aprendizaje automático desempeñan un papel clave en su eficacia. En los últimos años, se han desarrollado varios tipos de datos nuevos específicamente para trabajar con modelos de aprendizaje profundo. En este artículo nos centraremos en dos nuevos formatos de datos que se han generalizado en los modelos modernos.
Este artículo está dirigido a principiantes y desarrolladores avanzados de MQL5. Proporciona un fragmento de código para definir y limitar los indicadores generadores de señales a tendencias en plazos superiores. De este modo, los operadores pueden mejorar sus estrategias incorporando una perspectiva de mercado más amplia, lo que da lugar a señales de negociación potencialmente más sólidas y fiables.
El presente artículo presenta un experimento único cuyo objetivo es investigar el comportamiento de los algoritmos de optimización basados en poblaciones en el contexto de su capacidad para abandonar eficientemente los mínimos locales cuando la diversidad en la población es baja y alcanzar los máximos globales. Los trabajos en este campo nos permitirán comprender mejor qué algoritmos específicos pueden continuar con éxito la búsqueda a partir de las coordenadas fijadas por el usuario como punto de partida, y qué factores influyen en su éxito en este proceso.
ONNX es una gran herramienta para la integración de código complejo de IA entre diferentes plataformas, es una gran herramienta que viene con algunos desafíos que uno debe abordar para obtener el máximo provecho de ella, En este artículo se discuten los problemas comunes que podría enfrentar y cómo mitigarlos.
El presente material supone un intento único de investigación para combinar una variedad de algoritmos de población en una sola clase y simplificar la aplicación de técnicas de optimización. Este enfoque no solo descubre oportunidades para el desarrollo de nuevos algoritmos, incluidas variantes híbridas, sino que también crea un banco de pruebas básico y versátil. Este banco se convertirá así en una herramienta clave para seleccionar el algoritmo óptimo según un problema específico.
Embárquese en la siguiente fase de nuestro viaje MQL5. En este artículo para principiantes analizaremos el resto de funciones de la matriz y desmitificaremos conceptos complejos para que pueda elaborar estrategias de negociación eficaces. Hablaremos de ArrayPrint, ArrayInsert, ArraySize, ArrayRange, ArrarRemove, ArraySwap, ArrayReverse y ArraySort. Aumente su experiencia en negociación algorítmica con estas funciones de matriz esenciales. ¡Únase a nosotros en el camino hacia el dominio de MQL5!
En este artículo presentaremos una forma de implementar problemas de optimización con múltiples objetivos y restricciones al seleccionar «Custom Max» en la pestaña Setting del terminal MetaTrader 5. Como ejemplo, el problema de optimización podría ser: Maximizar el Factor de Beneficio, el Beneficio Neto y el Factor de Recuperación, de forma que la reducción sea inferior al 10%, el número de pérdidas consecutivas sea inferior a 5 y el número de operaciones por semana sea superior a 5.
Las máquinas de vectores de soporte clasifican los datos en función de clases predefinidas explorando los efectos de aumentar su dimensionalidad. Se trata de un método de aprendizaje supervisado bastante complejo dado su potencial para tratar datos multidimensionales. Para este artículo consideramos cómo su implementación muy básica de datos bidimensionales puede hacerse más eficientemente con el polinomio de Newton al clasificar precio-acción.
Este artículo es la última parte de una serie que describe nuestros pasos de desarrollo de un cliente MQL5 nativo para el protocolo MQTT 5.0. Aunque la biblioteca aún no está lista para la producción, en esta parte utilizaremos nuestro cliente para actualizar un símbolo personalizado con ticks (o precios) procedentes de otro broker. Por favor, consulte la parte inferior de este artículo para obtener más información sobre el estado actual de la biblioteca, lo que falta para que sea totalmente compatible con el protocolo MQTT 5.0, una posible hoja de ruta, y cómo seguir y contribuir a su desarrollo.
Desarrollando el tema del artículo anterior sobre el multibot, hemos decidido crear una plantilla más flexible y funcional, que tenga grandes posibilidades, y que se pueda utilizar eficazmente en freelance, además de como base para desarrollar asesores de divisa y periodo múltiple con posibilidad de integración con soluciones externas.
Operar con noticias puede ser complicado y abrumador, en este artículo repasaremos los pasos para obtener datos de noticias. Además, conoceremos el calendario económico de MQL5 y lo que ofrece.
En este artículo analizaremos los métodos de reducción de la dimensionalidad y su aplicación en el entorno comercial MQL5. En concreto, exploraremos los matices del análisis discriminante lineal (LDA) y el análisis de componentes principales (PCA) y analizaremos su impacto en el desarrollo de estrategias y el análisis de mercados.
El polinomio de Newton, que crea ecuaciones cuadráticas a partir de un conjunto de unos pocos puntos, es un enfoque arcaico pero interesante para observar una serie temporal. En este artículo tratamos de explorar qué aspectos podrían ser de utilidad para los operadores desde este enfoque, así como abordar sus limitaciones.
En nuestros modelos, a menudo utilizamos varios algoritmos de atención. Y, probablemente, lo más frecuente es utilizar transformadores. Su principal desventaja es la necesidad de recursos. En este artículo, estudiaremos un nuevo algoritmo que puede ayudar a reducir los costes informáticos sin perder calidad.
Este artículo continúa con el tema de la predicción del próximo movimiento de los precios. Le invito a conocer la arquitectura del Transformador Multifuturo. Su idea principal es descomponer la distribución multimodal del futuro en varias distribuciones unimodales, lo que permite simular eficazmente varios modelos de interacción entre agentes en la escena.
En este artículo, continuaremos desarrollando los elementos gráficos de la librería DoEasy, y añadiremos el desplazamiento vertical de los controles del objeto formulario y algunas funciones y métodos útiles que serán necesarios más adelante.
En este artículo examinaremos los sistemas comerciales que utilizan un concepto muy importante de los mercados financieros: la volatilidad. Asimismo, estudiaremos un sistema comercial basado en el Canal de Keltner, incluyendo su implementación en código y sus pruebas con varios activos.
En este artículo, discutiremos cómo utilizar el coeficiente generalizado de Hurst y la prueba del coeficiente de varianza para analizar el comportamiento de las series de precios en MQL5.
Los modelos que creamos son cada vez más grandes y complejos. Esto aumenta los costes no sólo de su formación, sino también de su funcionamiento. Sin embargo, el tiempo necesario para tomar una decisión suele ser crítico. A este respecto, consideremos los métodos para optimizar el rendimiento del modelo sin pérdida de calidad.
Continuación del artículo anterior como desarrollo de la idea de grupos sociales. El nuevo artículo investiga la evolución de los grupos sociales mediante algoritmos de reubicación y memoria. Los resultados ayudarán a comprender la evolución de los sistemas sociales y a aplicarlos a la optimización y la búsqueda de soluciones.
Como el objetivo aquí es ser didáctico. Mantendré las cosas en su forma más sencilla. Es decir, implementaremos solo lo necesario: la multiplicación de matrices. Verás que esto será suficiente para simular la multiplicación de una matriz por un escalar. La gran dificultad que muchas personas tienen a la hora de implementar un código utilizando la factorización de matrices es que, a diferencia de una factorización escalar, donde en casi todos los casos el orden de los factores no altera el resultado, cuando se usan matrices, la cosa no es así.
En este artículo, examinaremos la teoría de la inferencia causal utilizando el aprendizaje automático, así como la implementación del enfoque personalizado en Python. La inferencia causal y el pensamiento causal tienen sus raíces en la filosofía y la psicología y desempeñan un papel importante en nuestra comprensión de la realidad.
En esta serie, seguiremos desvelando los secretos de la programación. En nuestro nuevo artículo, aprenderemos los fundamentos de las estructuras, las clases y las funciones de tiempo y adquiriremos nuevas habilidades para lograr una programación eficiente. Esta guía será probablemente útil no solo para los principiantes, sino también para los desarrolladores experimentados, ya que simplifica conceptos complejos, ofreciendo información valiosa para dominar MQL5. Así que hoy podrá seguir aprendiendo cosas nuevas, mejorando sus conocimientos de programación y dominando el mundo del trading algorítmico.
Este artículo presenta un método bastante eficaz de previsión de trayectorias de múltiples agentes, capaz de adaptarse a diversas condiciones ambientales.