이 글은 파이썬과 MetaTrader 5를 통합함으로써 어떻게 연구의 유연성과 거래의 실행을 단일 워크플로로 결합하는지 그 방법을 보여줍니다. 파이썬은 데이터 분석, 피처 선택 및 모델 훈련에 사용되고 MetaTrader 5는 테스트 및 거래의 자동화에 사용됩니다. 이러한 접근 방식은 솔루션을 실제로 적용하는 과정을 간단하게 하고 재현성을 높여주며 거래 시스템의 개발을 더욱 빠르고 체계적으로 만들어 줍니다.
이 글에서는 기술적 분석 원리를 LSTM 신경망 아키텍처와 통합하여 볼륨 분석을 기반으로 가격을 예측하는 것을 개선할 수 있는 가능성에 대해 알아봅니다. 특히 이상 볼륨의 탐지 및 해석, 클러스터링 활용, 볼륨 기반의 피처 생성 및 이들에 대해 머신 러닝 맥락에서의 정의에 중점을 둡니다.
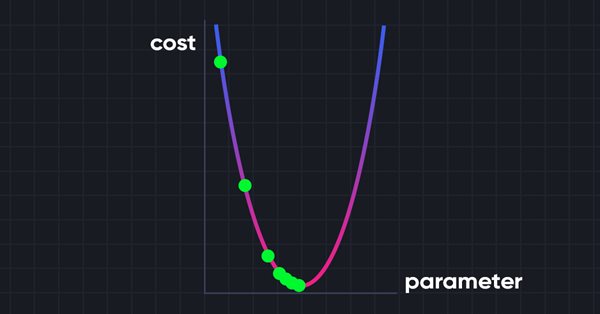
머신러닝은 전략 개발을 위한 인기 있는 방법이 되었습니다. 수익성과 예측 정확도를 극대화하는 데는 더 많은 관심이 집중되었지만 예측 모델을 구축하는 데 사용되는 데이터 처리의 중요성은 그다지 주목을 받지 못했습니다. 이 글에서는 티모시 마스터스의 책 '시장 트레이딩 시스템 테스트 및 조정'에 설명된 대로 엔트로피 개념을 사용해 예측 모델 구축에 사용할 지표의 적절성을 평가하는 방법을 살펴봅니다.
GSA는 무생물에서 영감을 얻은 모집단 최적화 알고리즘입니다. 알고리즘에 구현된 뉴턴의 중력 법칙과 그리고 물리적 객체의 상호 작용을 모델링하는 높은 신뢰성 덕분에 우리로 하여금 행성계와 은하단의 매혹적인 춤을 관찰하게 해 줍니다. 이 기사에서는 가장 흥미롭고 독창적인 최적화 알고리즘 중 하나를 살펴볼 것입니다. 우주의 객체의 움직임에 대한 시뮬레이터도 있습니다.
이 글에서는 Scikit-learn 패키지의 회귀 모델을 적용하고 이를 ONNX 형식으로 변환하고 결과 모델을 MQL5 프로그램 내에서 사용하는 방법에 대해 살펴봅니다. 또한 부동 소수점 및 배정밀도 모두에서 오리지널 모델의 정확도를 ONNX 버전과 비교할 것입니다. 이후 더 나아가 회귀 모델의 내부 구조와 작동 원리를 더 잘 이해하기 위해 회귀 모델의 ONNX 표현을 살펴볼 것입니다.
이 글에서는 피셔의 붓꽃 데이터 세트의 분류 작업을 해결하기 위해서 Scikit-Learn 라이브러리에서 사용할 수 있는 모든 분류 모델을 적용하는 방법을 살펴봅니다. 우리는 이러한 모델을 ONNX 형식으로 변환하고 그 결과 모델을 MQL5 프로그램에서 활용하려고 합니다. 또한 전체 붓꽃 데이터 세트에서 원래 모델의 정확도를 ONNX 버전과 비교합니다.
ONNX(Open Neural Network Exchange)는 머신 러닝 모델을 나타내기 위해 구축된 개방형 형식입니다. 이 기사에서는 금융 시계열을 예측하기 위해 CNN-LSTM 모델을 만드는 방법에 대해 살펴보겠습니다. 또한 MQL5 Expert Advisor에서 생성된 ONNX 모델을 사용하는 방법도 보여드리겠습니다.
이번에는 최신의 최적화 알고리즘 중 하나인 그레이 울프 최적화에 대해 알아봅시다. 테스트 함수에서의 오리지널 행동은 이 알고리즘을 앞서 고려한 알고리즘 중 가장 흥미로운 알고리즘 중 하나로 만듭니다. 이 알고리즘은 신경망 훈련, 많은 변수가 있는 부드러운 함수의 훈련에 사용되는 최고의 알고리즘 중 하나입니다.
의사 결정 트리는 인간이 데이터를 분류하기 위해 생각하는 방식을 모방합니다. 트리를 구축하고 트리를 사용하여 데이터를 분류하고 예측하는 방법에 대해 알아보겠습니다. 의사 결정 트리 알고리즘의 주요 목표는 불순물이 있는 데이터를 순수한 것으로 분리하거나 노드에 가깝게 분리하는 것입니다.
이 기사에서는 로지스틱 모델을 사용하여 미국 경제의 펀더멘털을 기반으로 주식 시장 폭락을 예측하려고 합니다. NETFLIX와 APPLE은 우리가 집중해서 볼 주식입니다. 이전의 2019년과 2020년의 시장 폭락을 통해 우리 모델이 현재의 암울한 상황에서 어떻게 작동하는지를 알아 봅시다.