Découvrir un nouveau monde de trading automatisé sur barres 3D. À quoi ressemble un robot de trading sur des barres de prix multidimensionnelles ? Les grappes de barres 3D « jaunes » sont-elles capables de prédire les retournements de tendance ? À quoi ressemble le trading multidimensionnel ?
Modèles de régression non linéaire sur le marché boursier : Est-il possible de prédire les marchés financiers ? Prenons l'exemple de la création d'un modèle de prévision des cours de l'EUR/USD, et de la création de deux robots basés sur ce modèle : l'un en Python et l'autre en MQL5.
Comment appliquer les règles prédictives de l'analyse des données de vente au détail en supermarché au marché réel du Forex ? Quel est le lien entre les achats de biscuits, de lait et de pain et les transactions boursières ? Cet article présente une approche novatrice du trading algorithmique basée sur l'utilisation de règles d'association.
Cet article explore la possibilité d'améliorer les prévisions de prix basées sur l'analyse des volumes de transactions en intégrant les principes de l'analyse technique à l'architecture du réseau neuronal LSTM. Une attention particulière est portée à la détection et à l'interprétation des volumes anormaux, à l'utilisation du clustering et à la création de caractéristiques basées sur les volumes et leur définition dans le contexte de l'apprentissage automatique.
Quel est le lien entre la météo et le Forex ? La théorie économique classique a longtemps ignoré l'influence de facteurs tels que les conditions météorologiques sur le comportement du marché. Mais tout a changé. Essayons de trouver des liens entre les conditions météorologiques et la position des devises agricoles sur le marché.
Dans cet article, nous allons créer un système d'arbitrage qui reste légal aux yeux des courtiers, crée des milliers de prix synthétiques sur le marché du Forex, les analyse et effectue des transactions fructueuses.
La position des planètes et des étoiles affecte-t-elle les marchés financiers ? Armons-nous de statistiques et de big data, et embarquons pour un voyage passionnant dans le monde où les étoiles et les graphiques boursiers se croisent.
Comment utiliser les données économiques de la Banque Mondiale pour les prévisions ? Que se passe-t-il lorsque l'on combine les modèles d'IA et l'économie ?
Nous poursuivons la série d'articles sur le développement d'un robot de trading en Python et en MQL5. Dans cet article, nous allons créer un algorithme de trading en Python.
Nous poursuivons la série d'articles sur le développement d'un robot de trading en Python et MQL5. Aujourd'hui, nous allons résoudre le problème de la sélection et de l'entraînement d'un modèle, de son test, de la mise en œuvre de la validation croisée, de la recherche en grille, ainsi que le problème de l'ensemble de modèles.
Développement d'un robot de trading basé sur l'apprentissage automatique : Un guide détaillé. Le premier article de la série traite de la collecte et de la préparation des données et des caractéristiques. Le projet est mis en œuvre à l'aide du langage de programmation et des bibliothèques Python, ainsi que de la plateforme MetaTrader 5.
L'apprentissage automatique est devenu une méthode populaire pour l'élaboration de stratégies. Alors que l'accent a été mis sur la maximisation de la rentabilité et de la précision des prédictions, l'importance du traitement des données utilisées pour construire des modèles prédictifs n'a pas fait l'objet d'une grande attention. Dans cet article, nous envisageons d'utiliser le concept d'entropie pour évaluer l'adéquation des indicateurs à utiliser dans la construction de modèles prédictifs, comme indiqué dans le livre Testing and Tuning Market Trading Systems de Timothy Masters.
Dans cet article, nous allons créer un modèle de forêt aléatoire (random forest) en Python, entraîner le modèle et le sauvegarder en tant que pipeline ONNX avec un pré-traitement des données. Ensuite, nous utiliserons le modèle dans le terminal MetaTrader 5.
L'article décrit les principes, les méthodes et les possibilités d'utilisation de l'Algorithme Electro-Magnétique dans divers problèmes d'optimisation. L'algorithme EM est un outil d'optimisation efficace capable de travailler avec de grandes quantités de données et des fonctions multidimensionnelles.
L'algorithme SSG (Saplings Sowing and Growing up) s'inspire de l'un des organismes les plus résistants de la planète, qui fait preuve d'une capacité de survie exceptionnelle dans des conditions très diverses.
Nombreux sont ceux qui les apprécient, mais rares sont ceux qui comprennent l'ensemble des opérations qui se cachent derrière les réseaux neuronaux. Dans cet article, j'essaierai d'expliquer en termes simples tout ce qui se passe derrière les portes closes d'une perception multicouche feed-forward.
Dans cet article, j'examinerai l'algorithme d'optimisation Monkey Algorithm (MA). La capacité de ces animaux à surmonter des obstacles difficiles et à atteindre les cimes des arbres les plus inaccessibles est à l'origine de l'idée de l'algorithme MA.
Dans cet article, j'étudierai et testerai l'algorithme d'optimisation le plus puissant : la recherche harmonique (HS), inspirée par le processus de recherche de l'harmonie sonore parfaite. Quel est donc l'algorithme qui domine aujourd'hui notre classement ?
GSA est un algorithme d'optimisation de la population inspiré de la nature inanimée. Grâce à la loi de la gravité de Newton implémentée dans l'algorithme, la grande fiabilité de la modélisation de l'interaction des corps physiques nous permet d'observer la danse enchanteresse des systèmes planétaires et des amas de galaxies. Dans cet article, j'examinerai l'un des algorithmes d'optimisation les plus intéressants et les plus originaux. Le simulateur de mouvement des objets spatiaux est également fourni.
La stratégie de recherche de nourriture de la bactérie E. coli a inspiré les scientifiques pour créer l'algorithme d'optimisation BFO. L'algorithme contient des idées originales et des approches prometteuses en matière d'optimisation et mérite d'être étudié plus avant.
Dans cet article, nous allons explorer l'application de tous les modèles de classification disponibles dans la bibliothèque Scikit-Learn pour résoudre la tâche de classification de l'ensemble de données Iris de Fisher. Nous tenterons de convertir ces modèles au format ONNX et d'utiliser les modèles résultants dans les programmes MQL5. Nous comparerons également la précision des modèles originaux avec leurs versions ONNX sur l'ensemble du jeu de données Iris.
Dans cet article, nous allons explorer l'application des modèles de régression du paquet Scikit-learn, tenter de les convertir au format ONNX, et utiliser les modèles résultants dans des programmes MQL5. Nous comparerons également la précision des modèles originaux avec leurs versions ONNX pour la précision flottante et la précision double. Nous examinerons aussi la représentation ONNX des modèles de régression, afin de mieux comprendre leur structure interne et leurs principes opérationnels.
L'étonnante capacité des mauvaises herbes à survivre dans une grande variété de conditions est devenue l'idée d'un puissant algorithme d'optimisation. L'IWO est l'un des meilleurs algorithmes parmi ceux qui ont été examinés précédemment.
La régression consiste à prédire une valeur réelle à partir d'un exemple non étiqueté. Les mesures dites de régression sont utilisées pour évaluer la précision des prédictions des modèles de régression.
Nous ne décrirons ici qu'un seul des aspects de l'apprentissage automatique, à savoir les fonctions d'activation. Dans les réseaux neuronaux artificiels, la fonction d'activation d'un neurone calcule la valeur d'un signal de sortie en fonction des valeurs d'un signal d'entrée ou d'un ensemble de signaux d'entrée. Nous nous pencherons sur les rouages du processus.
ONNX (Open Neural Network eXchange) est un format ouvert conçu pour représenter les réseaux neuronaux. Dans cet article, nous allons montrer comment utiliser simultanément 2 modèles ONNX dans un Expert Advisor.
Dans cet article, je considérerai la méthode d'optimisation de l'Algorithme Firefly (FA). Grâce à la modification, l'algorithme est passé d'un outsider à un véritable leader du classement.
ONNX (Open Neural Network Exchange) est un format ouvert, conçu pour représenter des modèles d'apprentissage automatique. Dans cet article, nous verrons comment créer un modèle CNN-LSTM pour prévoir des séries temporelles financières. Nous montrerons également comment utiliser le modèle ONNX créé dans un Expert Advisor MQL5.
Le Fish School Search (FSS) est un nouvel algorithme d'optimisation inspiré du comportement des poissons dans un banc, dont la plupart (jusqu'à 80%) nagent au sein d'une communauté organisée de parents. Il a été prouvé que les agrégations de poissons jouent un rôle important dans l'efficacité de la recherche de nourriture et dans la protection contre les prédateurs.
Le nouvel algorithme que je considérerai est l'optimisation de la recherche de coucou à l'aide des vols de Levy. C'est l'un des derniers algorithmes d'optimisation et un nouveau leader dans le classement.
Considérons l'un des algorithmes d'optimisation modernes les plus récents : le Grey Wolf Optimization. Le comportement original sur les fonctions de test fait de cet algorithme l'un des plus intéressants parmi ceux considérés précédemment. C'est l'un des meilleurs algorithmes à utiliser dans la formation de réseaux de neurones, des fonctions fluides avec de nombreuses variables.
Dans cet article, nous étudierons l'algorithme d'une colonie d'abeilles artificielles. Nous compléterons nos connaissances avec de nouveaux principes d'étude des espaces fonctionnels. Dans cet article, je présenterai mon interprétation de la version classique de l'algorithme.
Cette fois, je vais analyser l'algorithme d'Optimisation des Colonies de Fourmis. L'algorithme est très intéressant et complexe. Dans cet article, je tente de créer un nouveau type d'ACO.
Dans cet article, j'examinerai l'algorithme populaire d'Optimisation par Essaims Particulaires (OEP ou Particle Swarm Optimization - PSO). Précédemment, nous avons abordé les caractéristiques importantes des algorithmes d'optimisation telles que la convergence, le taux de convergence, la stabilité et l'évolutivité, et nous avons développé un banc d'essai et examiné l'algorithme RNG le plus simple.
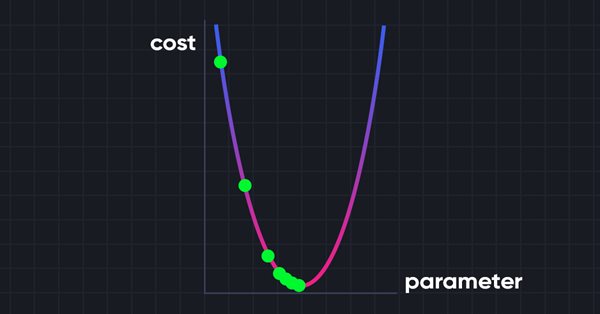
La Descente de Gradient joue un rôle important dans la formation des réseaux neuronaux et de nombreux algorithmes d'apprentissage automatique. C'est un algorithme rapide et intelligent. Mais malgré son travail impressionnant, il est encore mal compris par beaucoup de data scientists. Voyons de quoi il s'agit.
Les Arbres de Décision imitent la façon dont les humains pensent pour classer les données. Voyons comment construire des arbres et comment les utiliser pour classer et prédire certaines données. L'objectif principal de l'algorithme des arbres de décision est de séparer les données contenant des impuretés en nœuds purs ou proches.
Dans cet article, je vais tenter d'utiliser notre modèle logistique pour prédire le krach boursier en me basant sur les fondamentaux de l'économie américaine. Nous allons nous concentrer sur les actions NETFLIX et APPLE. En utilisant les krachs boursiers précédents de 2019 et 2020, voyons comment notre modèle se comportera dans la morosité actuelle.
En utilisant les types de données spéciaux "matrix" et "vector", il est possible de créer un code très proche de la notation mathématique. Avec ces méthodes, vous pouvez éviter de créer des boucles imbriquées ou de faire attention à l'indexation correcte des tableaux dans les calculs. Par conséquent, l'utilisation des méthodes matricielles et des méthodes vectorielles augmente la fiabilité et la rapidité du développement de programmes complexes.