L'articolo dimostra come l'integrazione tra Python e MetaTrader 5 combini la flessibilità della ricerca e l'esecuzione dei trade in un unico flusso di lavoro. Python viene utilizzato per l'analisi dei dati, la selezione delle feature e l'addestramento dei modelli, mentre MetaTrader 5 viene utilizzato per i test e l'automazione del trading. Questo approccio semplifica il trasferimento delle soluzioni nella pratica, aumenta la riproducibilità e rende lo sviluppo dei sistemi di trading più rapido e strutturato.
Alla scoperta di un nuovo mondo sul trading automatizzato con grafici a barre 3D. Come si presenta un robot di trading applicato a barre di prezzo multidimensionali? I cluster "gialli" delle barre 3D sono in grado di prevedere le inversioni di trend? Cosa si intende per trading multidimensionale?
Modelli di regressione non lineare nei mercati finanziari: È possibile prevedere i mercati finanziari? Consideriamo la possibilità di creare un modello per la previsione dei prezzi della coppia EUR/USD e di realizzare due robot basati su questo, utilizzando Python e MQL5.
Come applicare le regole predittive dell'analisi dei dati di vendita al dettaglio dei supermercati al mercato Forex reale? Che relazione c'è tra l'acquisto di biscotti, latte e pane e le transazioni in borsa? L'articolo illustra un approccio innovativo al trading algoritmico basato sull'utilizzo delle regole di associazione.
L'articolo esplora la possibilità di migliorare la previsione dei prezzi basata sull'analisi dei volumi di scambio, integrando i principi dell'analisi tecnica con l'architettura delle reti neurali LSTM. Particolare attenzione è dedicata all'individuazione e all'interpretazione dei volumi anomali, all'utilizzo del clustering, alla creazione di caratteristiche basate sui volumi e alla loro definizione nel contesto dell'apprendimento automatico.
Qual è la relazione tra le condizioni meteorologiche e il mercato Forex? La teoria economica classica ha a lungo ignorato l'influenza di fattori come le condizioni meteorologiche sul comportamento del mercato. Ma tutto è cambiato. Proviamo a individuare delle correlazioni tra le condizioni meteorologiche e l'andamento delle valute agricole sul mercato.
In questo articolo creeremo un sistema di arbitraggio che rimane lecito agli occhi dei broker, crea migliaia di prezzi sintetici sul mercato Forex, li analizza e opera con successo per ottenere profitti.
Le posizioni di pianeti e stelle influenzano i mercati finanziari? Armiamoci di statistiche e big data e intraprendiamo un viaggio emozionante nel mondo in cui stelle e grafici azionari si intersecano.
Come utilizzare i dati economici della Banca Mondiale per le previsioni? Cosa succede quando si combinano modelli di intelligenza artificiale ed economia?
Continuiamo la serie di articoli sullo sviluppo di un robot di trading in Python e MQL5. In questo articolo creeremo un algoritmo di trading in Python.
Continuiamo la serie di articoli sullo sviluppo di un robot di trading in Python e MQL5. Oggi risolveremo il problema della selezione e dell'addestramento di un modello, del suo test, dell'implementazione della convalida incrociata, della ricerca a griglia, nonché il problema dell'ensemble di modelli.
Sviluppo di un robot di trading basato sull'apprendimento automatico: Una guida dettagliata. Il primo articolo della serie tratta della raccolta e della preparazione dei dati e delle caratteristiche. Il progetto è stato implementato utilizzando il linguaggio di programmazione e le librerie Python, nonché la piattaforma MetaTrader 5.
L'apprendimento automatico è diventato un metodo popolare per lo sviluppo di strategie. Sebbene sia stata posta maggiore enfasi sulla massimizzazione della redditività e dell'accuratezza delle previsioni, l'importanza dell'elaborazione dei dati utilizzati per costruire i modelli predittivi non ha ricevuto molta attenzione. In questo articolo consideriamo l'utilizzo del concetto di entropia per valutare l'adeguatezza degli indicatori da utilizzare nella costruzione di modelli predittivi, come documentato nel libro Testing and Tuning Market Trading Systems di Timothy Masters.
In questo articolo, creeremo un modello foresta casuale in Python, lo addestreremo e lo salveremo come pipeline ONNX con la pre-elaborazione dei dati. Dopodiché, utilizzeremo il modello nel terminale MetaTrader 5.
L'articolo descrive i principi, i metodi e le possibilità di utilizzo dell'Algoritmo Elettromagnetico in vari problemi di ottimizzazione. L'algoritmo EM è un efficiente strumento di ottimizzazione in grado di lavorare con grandi quantità di dati e funzioni multidimensionali.
L'algoritmo Saplings Sowing and Growing up (SSG) si ispira a uno degli organismi più resistenti del pianeta, che dimostra un'eccezionale capacità di sopravvivenza in un'ampia varietà di condizioni.
Molte persone le amano, ma poche comprendono l'intero funzionamento delle Reti Neurali. In questo articolo cercherò di spiegare in parole povere tutto ciò che avviene dietro le porte chiuse di un percettrone multistrato feed-forward.
In questo articolo prenderò in considerazione l'algoritmo di ottimizzazione Monkey Algorithm (MA). La capacità di questi animali di superare ostacoli difficili e di raggiungere le cime degli alberi più inaccessibili ha costituito la base dell'idea dell'algoritmo MA.
In questo articolo, studierò e testerò il più potente algoritmo di ottimizzazione - la ricerca dell’armonia (HS), ispirata al processo di ricerca dell'armonia sonora perfetta. Quale algoritmo è ora leader nella nostra valutazione?
GSA è un algoritmo di ottimizzazione della popolazione ispirato alla natura inanimata. Grazie alla legge di gravità di Newton implementata nell'algoritmo, l'alta affidabilità della modellazione dell'interazione dei corpi fisici ci permette di osservare l'incantevole danza dei sistemi planetari e degli ammassi galattici. In questo articolo prenderò in considerazione uno degli algoritmi di ottimizzazione più interessanti e originali. È previsto anche un simulatore del movimento degli oggetti spaziali.
La strategia di foraggiamento del batterio E. coli ha ispirato gli scienziati a creare l'algoritmo di ottimizzazione BFO. L'algoritmo contiene idee originali e approcci promettenti all'ottimizzazione e merita ulteriori studi.
In questo articolo esploreremo l'applicazione dei modelli di regressione del pacchetto Scikit-learn, cercheremo di convertirli nel formato ONNX e utilizzeremo i modelli risultanti all’interno di programmi MQL5. Inoltre, confronteremo l'accuratezza dei modelli originali con le loro versioni ONNX sia per la precisione float che per la double. Inoltre, esamineremo la rappresentazione ONNX dei modelli di regressione, con l'obiettivo di fornire una migliore comprensione della loro struttura interna e dei principi operativi.
In questo articolo esploreremo l'applicazione di tutti i modelli di classificazione disponibili nella libreria Scikit-Learn per risolvere il compito di classificazione del set di dati Iris di Fisher. Cercheremo di convertire questi modelli in formato ONNX e di utilizzare i modelli risultanti nei programmi MQL5. Inoltre, confronteremo l'accuratezza dei modelli originali con le loro versioni ONNX sull'intero set di dati Iris.
La sorprendente abilità delle piante infestanti di sopravvivere in un'ampia varietà di condizioni è diventata l'idea per un potente algoritmo di ottimizzazione. IWO è uno dei migliori algoritmi tra quelli esaminati precedentemente.
La regressione ha il compito di prevedere un valore reale da un esempio non catalogato. Le cosiddette metriche di regressione vengono utilizzate per valutare l'accuratezza delle previsioni del modello di regressione.
La programmazione orientata agli oggetti consente di creare un codice più compatto che sia facile da leggere e da modificare. Qui di seguito vedremo l'esempio di tre modelli ONNX.
Qui descriveremo solo uno degli aspetti dell'apprendimento automatico - le funzioni di attivazione. Nelle reti neurali artificiali, una funzione di attivazione del neurone calcola il valore di un segnale di output in base ai valori di un segnale di input o di un insieme di segnali di input. Ci addentreremo nei meccanismi interni del processo.
ONNX (Open Neural Network eXchange) è un formato aperto costruito per rappresentare le reti neurali. In questo articolo mostreremo come utilizzare contemporaneamente due modelli ONNX in un Expert Advisor.
In questo articolo prenderò in considerazione il metodo di ottimizzazione dell'Algoritmo Firefly(FA). Grazie alla modifica, l'algoritmo si è trasformato da outsider a vero leader della classifica.
ONNX (Open Neural Network Exchange) è un formato aperto creato per rappresentare modelli di machine learning. In questo articolo considereremo come creare un modello CNN-LSTM per prevedere le serie temporali finanziarie. Mostreremo anche come utilizzare il modello ONNX creato in un Expert Advisor MQL5.
La Ricerca del Banco di Pesci (FSS) è un nuovo algoritmo di ottimizzazione ispirato al comportamento dei pesci in un banco, la maggior parte dei quali (fino all'80%) nuota in una comunità organizzata di affini. È stato dimostrato che le aggregazioni dei pesci svolgono un ruolo importante nell'efficienza del foraggiamento e nella protezione dai predatori.
Il prossimo algoritmo che considererò è l'ottimizzazione della ricerca del cuculo utilizzando i voli di Levy. Si tratta di uno dei più recenti algoritmi di ottimizzazione e di un nuovo leader in classifica.
Prendiamo in considerazione uno dei più recenti algoritmi di ottimizzazione moderni - l'ottimizzazione Grey Wolf. Il comportamento originale sulle funzioni test rende questo algoritmo uno dei più interessanti tra quelli considerati in precedenza. Si tratta di uno dei principali algoritmi per l'addestramento di reti neurali e funzioni regolari con molte variabili.
In questo articolo studieremo l'algoritmo di una colonia di api artificiali e integreremo le nostre conoscenze con nuovi principi dello studio degli spazi funzionali. In questo articolo presenterò la mia interpretazione della versione classica dell'algoritmo.
Questa volta analizzerò l'algoritmo di ottimizzazione Ant Colony. L'algoritmo è molto interessante e complesso. Nell'articolo, provo a creare un nuovo tipo di ACO.
In questo articolo, prenderò in considerazione il famoso algoritmo Particle Swarm Optimization (PSO). In precedenza, abbiamo discusso caratteristiche così importanti degli algoritmi di ottimizzazione come convergenza, tasso di convergenza, stabilità, scalabilità, nonché sviluppato un banco di prova e considerato il più semplice algoritmo RNG..
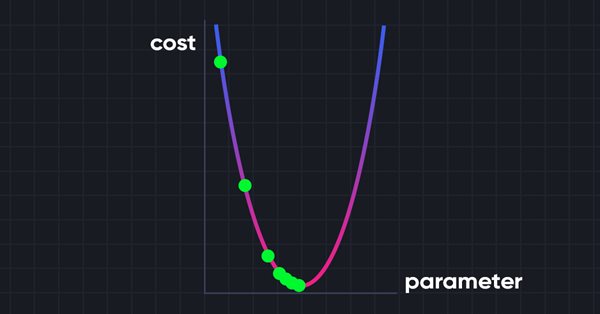
La discesa del gradiente gioca un ruolo significativo nell'addestramento delle reti neurali e di molti algoritmi di apprendimento automatico. È un algoritmo veloce e intelligente, nonostante il suo lavoro impressionante, è ancora frainteso da molti data scientist, vediamo di cosa si tratta.
Gli alberi decisionali imitano il modo in cui gli esseri umani pensano nel classificare i dati. Vediamo come costruire alberi e utilizzarli per classificare e prevedere alcuni dati. L'obiettivo principale dell'algoritmo degli alberi decisionali è separare i dati con impurità in nodi puri o vicini.
In questo articolo cercherò di utilizzare il nostro modello logistico per prevedere il crollo del mercato azionario basato sui fondamentali dell'economia statunitense, NETFLIX e APPLE sono i titoli su cui ci concentreremo. Utilizzando i precedenti crolli del mercato del 2019 e 2020 vediamo come funzionerà il nostro modello nelle attuali sventure e tenebre.