Neste artigo, continuaremos a falar sobre métodos de coleta de dados em uma amostra de treinamento. É claro que o processo de aprendizado requer constante interação com o ambiente. Mas as situações podem variar.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
Neste novo artigo da série dedicada a padrões de projeto, exploraremos os padrões comportamentais para entender como criar métodos eficazes de interação entre os objetos criados. Ao projetar esses padrões de comportamento, poderemos entender como desenvolver software reutilizável, expansível e testável.
Os modelos de aprendizado de máquina são difíceis de interpretar, e entender o motivo pelo qual os modelos não atendem às nossas expectativas pode ajudar muito a alcançar o resultado desejado ao usar esses métodos modernos. Sem um entendimento abrangente do funcionamento interno do modelo, pode ser difícil identificar erros que prejudicam o desempenho. Nesse processo, podemos dedicar tempo a criar funções que não impactam na qualidade da previsão. No final, por melhor que seja o modelo, perdemos todos os seus principais benefícios devido a nossos próprios erros. Felizmente, existe uma solução complexa, mas bem desenvolvida, que permite ver claramente o que está acontecendo sob o capô do modelo.
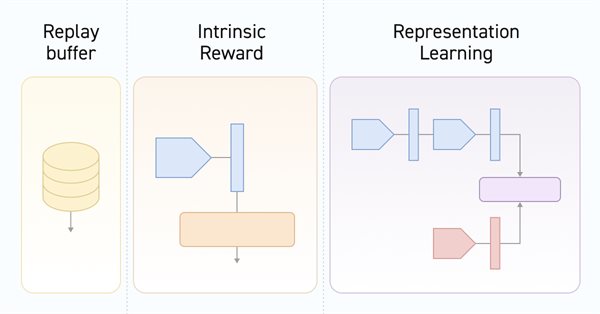
O treinamento de modelos em modo off-line é realizado com dados de uma amostra de treinamento previamente preparada. Isso nos oferece várias vantagens, mas também comprime significativamente as informações sobre o ambiente em relação às dimensões da amostra de treinamento. Isso, por sua vez, limita as possibilidades de pesquisa. Neste artigo, quero apresentar um método que permite enriquecer a amostra de treinamento com dados o mais diversificados possível.
Este artigo serve como uma introdução à programação em MQL5 para novatos, abrindo portas para o empolgante mundo da negociação algorítmica. Aqui, você vai descobrir os princípios básicos do MQL5, a linguagem de programação usada para desenvolver estratégias de negociação no MetaTrader 5, que facilita a entrada no universo da negociação automatizada. Abrangendo desde a compreensão dos conceitos iniciais até os primeiros passos na programação, este texto é projetado para desbloquear as possibilidades da negociação algorítmica para todos os leitores, incluindo aqueles sem nenhuma experiência prévia em programação. Espero que aprecie esta incursão pelo mundo do trading com MQL5.
Neste artigo, vamos desenvolver um modelo de floresta aleatória usando Python. Vamos treinar esse modelo e salvá-lo como um pipeline ONNX, já incluindo etapas de pré-processamento de dados. Depois, esse modelo será aplicado diretamente no terminal do MetaTrader 5.
Neste artigo, convido você a conhecer um algoritmo interessante que se situa na interseção entre os métodos de aprendizado supervisionado e de reforço.
Neste artigo, por EA multimoeda, entendemos um robô investidor, ou um robô de negociação, que pode negociar (abrir/fechar ordens, gerenciar ordens, por exemplo, do tipo trailing stop-loss e trailing profit) mais de um par de moedas em um gráfico. Desta vez, usaremos apenas um indicador, em particular a média móvel triangular em um ou mais timeframes, ou escalas de tempo.
Neste artigo, continuaremos a estudar os padrões de projeto que permitem aos desenvolvedores criar aplicativos expansíveis e confiáveis não apenas no MQL5, mas também em outras linguagens de programação. Desta vez, falaremos sobre outro tipo: modelos estruturais. Aprenderemos a projetar sistemas usando as classes disponíveis para formar estruturas maiores.
Neste artigo veremos como implementar a verificação cruzada combinatoriamente simétrica no MQL5 puro para medir o grau de ajuste após a otimização de uma estratégia usando o algoritmo completo e lento do testador de estratégias.
Pelo resultado dos testes realizados em artigos anteriores, concluímos que a qualidade da estratégia treinada depende muito da amostra de treinamento utilizada. Neste artigo, apresento a vocês um método simples e eficaz para selecionar trajetórias com o objetivo de treinar modelos.
Stop-loss e take-profit podem ter um impacto significativo nos resultados do trading. Neste artigo, vamos explorar algumas maneiras de encontrar os valores ótimos para ordens de stop.
Continuamos nossa análise, desta vez, explorando a família de transformadores de decisão. Em trabalhos anteriores, já observamos que o treinamento do transformador subjacente à arquitetura desses métodos é bastante desafiador e requer uma grande quantidade de dados de treinamento rotulados. Neste artigo, consideramos um algoritmo para usar trajetórias não rotuladas com o objetivo de pré-treinar modelos.
Recebi comentários de vários colegas traders sobre como usar o Expert Advisor multimoedas que estou analisando com corretoras que usam prefixos e/ou sufixos com nomes de símbolos, bem como sobre como implementar fusos horários de negociação ou sessões de negociação no Expert Advisor.
Existem métodos que podem ser usados para resolver problemas típicos. Depois de entender como usar esses métodos, você pode então escrever programas de maneira prática e aplicar o conceito DRY ("Don't Repeat Yourself" - "Não se Repita"). Neste contexto, os padrões de projeto são extremamente úteis, pois apresentam soluções para problemas bem descritos e recorrentes.
Nos últimos artigos, exploramos várias formas de usar o método Decision Transformer. Ele permite analisar não só o estado atual, mas também a trajetória de estados anteriores e as ações realizadas neles. Neste artigo, proponho que você conheça uma forma de usar este método em modelos hierárquicos.
Durante o aprendizado off-line, otimizamos a política do Agente com base nos dados da amostra de treinamento. A estratégia resultante confere ao Agente confiança em suas ações. Mas, essa confiança nem sempre é justificada, já que pode acarretar maiores riscos durante a utilização prática do modelo. Hoje vamos examinar um dos métodos para reduzir esses riscos.
A classificação de dados para análise e previsão é uma área muito diversificada do aprendizado de máquina, que compreende um grande número de abordagens e métodos. Neste artigo, examinaremos uma dessas abordagens, nomeadamente o agrupamento hierárquico aglomerativo (Agglomerative Hierarchical Clustering).
Os modelos de linguagem (LLMs) são uma parte importante da inteligência artificial que evolui rapidamente. E para aproveitar isso devemos pensar em como integrar LLMs avançados em nossa negociação algorítmica Muitos acham desafiador ajustar esses modelos de acordo com suas necessidades, implantá-los localmente e, logo, aplicá-los à negociação algorítmica. Esta série de artigos explorará uma abordagem passo a passo para alcançar esse objetivo.
Neste artigo, examinaremos os princípios para criar indicadores com vários símbolos/períodos e recuperar dados deles dentro de EAs e indicadores. Veremos as nuances mais importantes ao usar multi-indicadores em EAs e indicadores, e sua plotagem mediante buffers de indicador personalizado.
As últimas 2 partes foram dedicadas ao método transformador de decisões (DT), que modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. Neste artigo, vamos considerar outro algoritmo de otimização deste método.
É muito importante que os operadores e desenvolvedores de ferramentas de negociação entendam como manusear datas e horas de forma adequada e eficiente. Neste artigo, mostrarei como podemos trabalhar com datas e horas ao criar ferramentas de negociação eficientes.
Os modelos de linguagem são uma parte importante da inteligência artificial que evolui rapidamente, por isso devemos pensar em como integrar LLMs poderosos em nossa negociação algorítmica. Para a maioria das pessoas, é desafiador configurar esses poderosos modelos de acordo com suas necessidades, implementá-los localmente e, em seguida, aplicá-los à negociação algorítmica. Esta série de artigos explorará uma abordagem passo a passo para alcançar esse objetivo.
No artigo anterior, nos familiarizamos com o transformador de decisões. Porém, o complexo ambiente estocástico do mercado de moedas não permitiu revelar totalmente o potencial do método apresentado. Hoje, quero apresentar a vocês um algoritmo focado em melhorar o desempenho dos algoritmos em ambientes estocásticos.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
Neste artigo, apresentaremos a implementação de vários indicadores de rentabilidade e risco, considerados alternativas ao índice de Sharpe, e exploraremos curvas de patrimônio líquido hipotéticas para analisar suas características.
Continuamos a explorar os métodos de aprendizado por reforço. Neste artigo, proponho apresentar um algoritmo ligeiramente diferente que considera a política do agente sob a perspectiva de construir uma sequência de ações.
Neste artigo, por EA multimoeda, entendemos um robô investidor ou um robô de negociação que pode negociar (abrir/fechar ordens, gerenciar ordens como trailing-stop-loss e trailing profit) mais de um par de moedas em um gráfico. Desta vez, usaremos apenas um indicador, o Parabolic SAR ou iSAR, em vários timeframes, começando com PERIOD_M15 e terminando com PERIOD_D1.
Neste artigo, tentaremos simplificar a descrição dos conceitos discutidos nesta série, focando apenas em um indicador, o mais comum e, provavelmente, o mais fácil de entender. Estamos falando da média móvel. Também examinaremos o significado e as possíveis aplicações das transformações naturais verticais.
Vamos nos afastar um pouco de nossos tópicos mais comuns e analisar uma parte do algoritmo do ChatGPT. Ele possui algumas semelhanças ou conceitos emprestados das transformações naturais? Vamos tentar responder a essas e outras perguntas usando nosso código no formato de classe de sinal.
Neste artigo, examinaremos o pairs trade, ou negociação de pares, principalmente seus princípios e perspectivas quanto à sua aplicação prática. Além disso, tentaremos criar uma estratégia baseada nele.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
Apresentamos um algoritmo relativamente novo, o Stochastic Marginal Actor-Critic (SMAC), que permite a construção de políticas de variáveis latentes no contexto da maximização da entropia.
Ao criar um sistema de negociação, há sempre uma tarefa que deve ser resolvida com eficiência. Essa tarefa é a colocação de ordens ou seu processamento automático pelo sistema de negociação. Neste artigo, apresentamos a criação de um sistema de negociação do ponto de vista da colocação eficiente de ordens.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
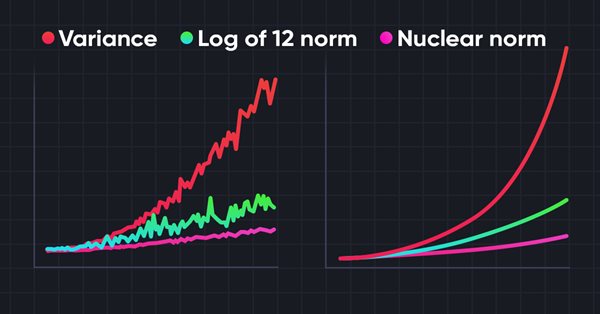
A pesquisa do ambiente em tarefas de aprendizado por reforço é um problema atual. Anteriormente, já examinamos algumas abordagens. E hoje, eu proponho que nos familiarizemos com mais um método, baseado na maximização da norma nuclear. Ele permite que os agentes destaquem estados do ambiente com alto grau de novidade e diversidade.
O aprendizado contrastivo é um método de aprendizado de representação sem supervisão. Seu objetivo é ensinar o modelo a identificar semelhanças e diferenças nos conjuntos de dados. Neste artigo, discutiremos o uso de abordagens de aprendizado contrastivo para explorar diferentes habilidades do Ator.
Este é o último artigo da série dedicada a funtores. Nele, reconsideramos monoides como uma categoria. Os monoides, que já apresentamos nesta série, são usados aqui para ajudar na definição do tamanho da posição juntamente com perceptrons multicamadas.