O artigo explora a possibilidade de melhorar a previsão de preços com base na análise do volume de negociações, integrando os princípios da análise técnica com a arquitetura de redes neurais LSTM. Dá-se atenção especial à identificação e interpretação de volumes anômalos, uso de clusterização e criação de características baseadas em volume, além de sua definição no contexto de aprendizado de máquina.
Implementar a parte que será executada aqui no MetaTrader 5, está longe de ser complicado. Mas existem diversos cuidados e pontos de atenção a serem observados. Isto para que você caro leitor, consiga de fato fazer com que o sistema funcione. Lembre-se de uma coisa: Você não executará um único programa. Você estará na verdade, executando três programas ao mesmo tempo. E é importante que cada um seja implementado e construído de forma que trabalhem e conversem entre si. Isto sem que eles fiquem completamente sem saber o que cada um está querendo ou desejando fazer.
O artigo aborda o algoritmo AOS (Atomic Orbital Search), que utiliza conceitos do modelo orbital atômico para simular a busca por soluções. O algoritmo se baseia em distribuições probabilísticas e na dinâmica das interações dentro de um átomo. O artigo discute detalhadamente os aspectos matemáticos do AOS, incluindo a atualização das posições dos candidatos a soluções e os mecanismos de absorção e emissão de energia. O AOS abre novos caminhos para a aplicação de princípios quânticos em tarefas computacionais, oferecendo uma abordagem inovadora para a otimização.
A Regressão por Vetores de Suporte é uma maneira idealista de encontrar uma função ou 'hiperplano' que melhor descreva a relação entre dois conjuntos de dados. Tentamos explorar isso na previsão de séries temporais dentro das classes personalizadas do MQL5 wizard.
Neste artigo, continuaremos a análise dos métodos de otimização restantes da biblioteca ALGLIB, com foco especial em seus testes em funções complexas e multidimensionais. Isso nos permitirá não apenas avaliar a eficiência de cada algoritmo, mas também identificar seus pontos fortes e fracos em diferentes condições.
Este artigo apresenta a implementação do algoritmo de Levenberg-Marquardt para o treinamento de redes neurais com propagação para frente. Foi feita uma análise comparativa de desempenho com os algoritmos da biblioteca scikit-learn do Python. Primeiramente, são discutidos métodos de treinamento mais simples, como a descida do gradiente, a descida do gradiente com momentum e a descida do gradiente estocástica.
Como o clima está relacionado ao mercado cambial? Na teoria econômica clássica, por muito tempo não se reconheceu a influência de fatores como o clima no comportamento do mercado. Porém, tudo mudou. Vamos tentar estabelecer conexões entre o estado do tempo e a situação das moedas agrícolas no mercado.
Máquinas de Boltzmann Restritas são uma forma de rede neural que foi desenvolvida no meio da década de 1980, numa época em que os recursos computacionais eram extremamente caros. No início, ela dependia de Gibbs Sampling e Divergência Contrastiva para reduzir a dimensionalidade ou capturar as probabilidades/propriedades ocultas sobre os conjuntos de dados de treinamento de entrada. Examinamos como o Backpropagation pode realizar de forma similar quando o RBM 'embebe' os preços para um Multi-Layer-Perceptron de previsão.
Neste artigo, vamos automatizar as estratégias de negociação com a Estratégia Parabolic SAR em MQL5: Criando um Expert Advisor Eficaz. O EA realizará negociações com base nas tendências identificadas pelo indicador Parabolic SAR.
Este artigo discute a criação de uma Interface de Mensagens para o MetaTrader 5, voltada para Administradores de Sistema, para facilitar a comunicação com outros traders diretamente dentro da plataforma. Integrações recentes de plataformas sociais com o MQL5 permitem a transmissão rápida de sinais através de diferentes canais. Imagine ser capaz de validar sinais enviados com apenas um clique—"SIM" ou "NÃO". Continue lendo para saber mais.
Estamos a um passo de concluir este desafio. Porém, quero que você, caro leitor, procure entender primeiro estes dois artigos. Tanto este como o anterior. Isto para que consiga de fato entender o próximo onde abordarei exclusivamente a parte referente a programação em MQL5. Apesar de que ali a coisa será igualmente voltada a ser fácil de entender. Se você não compreender estes dois últimos artigos. Com toda a certeza terá grandes problemas em entender o próximo. O motivo disto é simples: As coisas vão se acumulando. Quando mais coisas é preciso fazer, mais coisas é preciso criar e entender para poder atingir o objetivo.
Neste artigo, vamos conhecer os métodos de otimização da biblioteca ALGLIB para MQL5. O artigo inclui exemplos simples e visuais de aplicação da ALGLIB para resolver tarefas de otimização, o que tornará o processo de aprendizado dos métodos o mais acessível possível. Analisaremos detalhadamente a integração de algoritmos como BLEIC, L-BFGS e NS, e com base neles resolveremos uma tarefa de teste simples.
Modelos de aprendizado de máquina vêm com vários parâmetros ajustáveis. Nesta série de artigos, exploraremos como personalizar seus modelos de IA para se ajustar ao seu mercado específico utilizando a biblioteca SciPy.
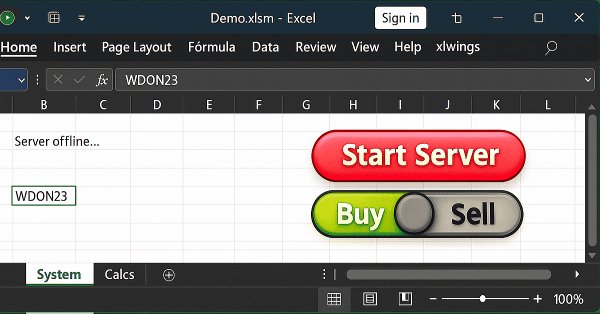
Neste artigo daqui, explicarei uma das soluções possíveis para o que venho tentando mostrar. Ou seja, como permitir que um usuário no Excel, consiga fazer algo no MetaTrader 5. Isto sem que ele de fato, envie ordens, abra ou feche uma posição usando o MetaTrader 5. A ideia, é que o usuário faça uso do Excel a fim de ter um estudo fundamentalista de algum ativo. E fazendo uso, apenas e somente do Excel, ele consiga dizer a um Expert Advisor, que esteja executando no MetaTrader 5, que é para abrir ou fechar uma dada posição.
O artigo aborda o algoritmo metaheurístico AEO, que modela as interações entre os componentes de um ecossistema, criando uma população inicial de soluções e aplicando estratégias adaptativas de atualização, e descreve detalhadamente as etapas do funcionamento do AEO, incluindo as fases de consumo e decomposição, bem como as diferentes estratégias de comportamento dos agentes. O artigo apresenta as características e vantagens do AEO.
Tentou-se criar um EA para prever cotações de taxas de câmbio. Como base para o algoritmo, foram adotados modelos clássicos de classificação, como regressão logística e probit. O critério de razão de verossimilhança é utilizado para filtrar os sinais de negociação.
Criamos um sistema de arbitragem legal aos olhos das corretoras, que gera milhares de preços sintéticos no mercado Forex, os analisa e negocia com sucesso e de forma lucrativa.
Existem padrões repetitivos e regularidades no mercado cambial? Decidi criar meu próprio sistema de análise de padrões usando Python e MetaTrader 5. Uma espécie de simbiose entre matemática e programação para conquistar o Forex.
Quando você desenvolve algo, seja no xlwings, ou qualquer outro pacote que nos permita ler e escrever diretamente no Excel. Você na verdade deve notar que todos os programas, funções ou procedimentos. Executam e logo finalizam a sua tarefa. Eles não ficam ali, dentro de um loop. E por mais que você tente fazer as coisas de uma forma diferente.
Este artigo apresenta o Algoritmo do Campo Elétrico Artificial (AEFA), inspirado na lei de Coulomb da força eletrostática. Por meio de partículas carregadas e suas interações, o algoritmo simula fenômenos elétricos para resolver tarefas complexas de otimização. O AEFA demonstra propriedades únicas em relação a outros algoritmos baseados em leis da natureza.
Os Kernels de Processos Gaussianos são a função de covariância da Distribuição Normal que pode desempenhar um papel em previsões. Exploramos esse algoritmo único em uma classe de sinal personalizada em MQL5 para ver se pode ser utilizado como um sinal principal de entrada e saída.
Na nossa série sobre integração do MQL5 com pacotes de processamento de dados, mergulhamos na poderosa combinação de aprendizado de máquina e análise preditiva. Exploraremos como conectar o MQL5 de forma perfeita com bibliotecas populares de aprendizado de máquina, para possibilitar modelos preditivos sofisticados para os mercados financeiros.
Neste artigo, vamos ver como resolver algumas questões e ver alguns problemas que temos ao usar código feito em Python dentro de outros programas. No caso o que mostrarei aqui, é um típico problema que existe, quando você vai usar o Excel junto com o MetaTrader 5. Mas para fazer esta comunicação estaremos usando o Python. Porém existe um pequeno problema nesta implementação. Não em todos os casos, mas em alguns casos específicos e quando o problema ocorre você tem que entender por que ele ocorre. Neste artigo iniciarei a explicação de como resolver tal coisa.
A função de perda (Loss Function) é uma métrica fundamental nos algoritmos de aprendizado de máquina, que fornece feedback para o processo de aprendizado ao quantificar o quão bem um determinado conjunto de parâmetros se comporta em comparação com o valor-alvo esperado. Vamos explorar os diferentes formatos dessa função na classe personalizada do Assistente MQL5.
A regularização é uma forma de penalizar a função de perda em proporção ao peso discreto aplicado ao longo das várias camadas de uma rede neural. Vamos observar a importância de algumas formas de regularização e o impacto que isso pode ter em testes realizados com um Expert Advisor montado por um assistente.
Neste artigo, analisamos em detalhes os aspectos importantes para a escolha dos dados mais relevantes e de qualidade do mercado Forex e para melhorar o desempenho dos modelos de inteligência artificial.
Neste artigo, discutimos o conceito de dynamic time warping como uma forma de identificar padrões preditivos em séries temporais financeiras. Veremos como ele funciona e também apresentaremos sua implementação em MQL5 puro.
A normalização em lote é um pré-processamento dos dados antes de sua entrada em um algoritmo de aprendizado de máquina, como uma rede neural. Ao aplicá-la, é essencial levar em conta o tipo de ativação que será usado pelo algoritmo. Exploraremos diferentes abordagens para extrair vantagens com um EA construído no Assistente.
Vamos começar a implementar a comunicação entre o Excel e o MetaTrader 5. Mas antes é preciso entender algumas coisas importantes. Isto para que não venha a ficar coçando a cabeça tentando entender por que as coisas funcionam ou não. Mas antes que você venha a torcer o nariz para a integração entre o Python e o Excel. Vamos ver como podemos usar o xlwings, a fim de poder controlar de alguma forma o MetaTrader 5. Isto através do Excel. O que irei mostrar aqui será como foco principal a didática. Não ache que podemos fazer apenas o que mostrarei.
A integração permite um fluxo de trabalho contínuo, no qual os dados financeiros brutos do MQL5 podem ser importados para pacotes de processamento de dados, como o Jupyter Lab, possibilitando análises avançadas, incluindo testes estatísticos.
Muitos modelos de inteligência artificial são projetados para prever um único valor futuro. Neste artigo, veremos como utilizar modelos de aprendizado de máquina para prever múltiplos valores futuros. Essa abordagem, chamada de previsão multietapa, permite não apenas prever o preço de fechamento de amanhã, mas também o de depois de amanhã e assim por diante. A previsão multietapa oferece uma vantagem inegável para traders e analistas de dados, pois amplia o espectro de informações para oportunidades de planejamento estratégico.
Estamos concluindo a análise da sensibilidade da taxa de aprendizado ao desempenho do EA, estudando taxas de aprendizado adaptáveis Essas taxas devem ser ajustadas para cada parâmetro da camada durante o treinamento, por isso precisamos avaliar os potenciais benefícios em relação às perdas esperadas no desempenho.
Neste artigo, nosso especialista em negociação de notícias começará a abrir negociações com base no calendário econômico armazenado em nosso banco de dados. Além disso, melhoraremos os gráficos do especialista para exibir informações mais relevantes sobre os próximos eventos do calendário econômico.
Aqui neste artigo mostrei o que você precisa fazer para começar a usar o Excel para controlar o MetaTrader 5. Mas faremos isto de uma forma bastante interessante. Para fazer isto iremos usar um Add-in no Excel. Isto para não precisar de fato fazer uso do VBA presente no Excel. Se você não sabe de que Add-in estou falando. Veja este artigo e aprenda como fazer para programar em Python diretamente dentro do Excel.
Neste artigo, investigamos como o Exponente de Hurst Generalizado e o Teste de Razão de Variância podem ser utilizados para analisar o comportamento das séries de preços em MQL5.
Este artigo é dedicado ao algoritmo meta-heurístico Atmosphere Clouds Model Optimization (ACMO), que modela o comportamento das nuvens para resolver problemas de otimização. O algoritmo utiliza os princípios de geração, movimento e dispersão de nuvens, adaptando-se às "condições climáticas" no espaço de soluções. O artigo explora como a simulação meteorológica do algoritmo encontra soluções ótimas em um espaço complexo de possibilidades e descreve detalhadamente as etapas do ACMO, incluindo a preparação do "céu", o nascimento das nuvens, seu deslocamento e a concentração de chuva.
Neste artigo, discutimos como a causalidade estatística pode ser aplicada para identificar variáveis preditivas. Exploraremos a relação entre causalidade e entropia de transferência, além de apresentar um código MQL5 para detectar transferências direcionais de informação entre duas variáveis.
Neste artigo, continuaremos a explorar a implementação do algoritmo ACMO (Atmospheric Cloud Model Optimization). Em particular, discutiremos dois aspectos-chave: o movimento das nuvens para regiões de baixa pressão e a modelagem do processo de chuva, incluindo a inicialização das gotas e sua distribuição entre as nuvens. Analisaremos também outros métodos importantes para a gestão do estado das nuvens e para garantir sua interação com o ambiente.
Este artigo é continuação do artigo anterior. Aqui vamos ver como o Expert Advisor será implementado. Mas principalmente como deverá ser feito o código do servidor. Isto por que, o código que foi visto no artigo anterior não é o suficiente para que possamos de fato fazer com que as coisas funcionem como deverão. Então é necessário que você veja ambos artigos para compreender mais profundamente o que estará acontecendo.