Раскройте свой потенциал! Вас окружают возможности. Узнайте 3 главных секрета, с помощью которых вы начнете изучать MQL5 или перейдете на новый уровень владения этим языком. Погрузимся в обсуждение советов и рекомендаций, в равной степени полезных и начинающим, и профи.
В этой статье мы рассмотрим особенности применения некоторых критериев тренда на практике. А также сделаем попытку разработать несколько новых критериев. Основное внимание будет уделено эффективности применения этих критериев для анализа рыночных данных и трейдинга.
Фреймворк Actor–Director–Critic — это эволюция классической архитектуры агентного обучения. В статье представлен практический опыт его реализации и адаптации к условиям финансовых рынков.
В данной статье продемонстрирован подход к созданию торговых стратегий для золота с помощью машинного обучения. Рассматривая предложенный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов.
Определяем перекупленность и перепроданность рынка по теории хаоса: интеграция принципов теории хаоса, фрактальной геометрии и нейронных сетей для прогнозирования финансовых рынков. Исследование демонстрирует применение показателя Ляпунова, как меры рыночной хаотичности, и динамическую адаптацию торговых сигналов. Методология включает алгоритм генерации фрактального шума, гиперболическую тангенциальную активацию и оптимизацию с моментом.
Предлагаем познакомиться с фреймворком Actor-Director-Critic, который сочетает в себе иерархическое обучение и многокомпонентную архитектуру для создания адаптивных торговых стратегий. В этой статье мы подробно рассмотрим, как использование Режиссера для классификации действий Актера помогает эффективно оптимизировать торговые решения и повышать устойчивость моделей в условиях финансовых рынков.
Parabolic Stop-and-Reversal (SAR) - это индикатор точек подтверждения и окончания тренда. Поскольку он отстает в определении трендов, его основной целью было позиционирование скользящих стоп-лоссов по открытым позициям. Мы рассмотрим, можно ли его использовать в качестве сигнала советника с помощью пользовательских классов сигналов советников, собранных с помощью Мастера.
RSI — популярный импульсный осциллятор, который измеряет темп и размер недавнего изменения цены ценной бумаги для оценки ситуаций переоценки или недооценки ее цены. Эти знания о скорости и масштабах имеют ключевое значение для определения точек разворота. Мы применим этот осциллятор в работе очередного пользовательского класса сигналов и изучим особенности некоторых из его сигналов. Однако начнем мы с того, что подведем итог нашему разговору о полосах Боллинджера.
В статье рассматривается практическая реализация фреймворка HiSSD в задачах алгоритмического трейдинга. Показано, как иерархия навыков и адаптивная архитектура могут быть использованы для построения устойчивых торговых стратегий.
Помните советник Ilan 1.6 Dymanic? Попробуем улучшить его с помощью машинного обучения! Реанимируем старую разработку в статье и добавляем машинное обучение с Q-таблицей. По шагам.
В данной статье рассматривается подход к торговле только в выбранном направлении (на покупку или на продажу). Для этого используется техника причинно-следственного вывода и машинное обучение.
Полосы Боллинджера — очень распространенный индикатор конвертов, используемый многими трейдерами для ручного размещения и закрытия сделок. Мы изучим этот индикатор, рассмотрев как можно больше различных сигналов, которые он генерирует, и посмотрим, как их можно использовать в советнике, собранном с помощью Мастера.
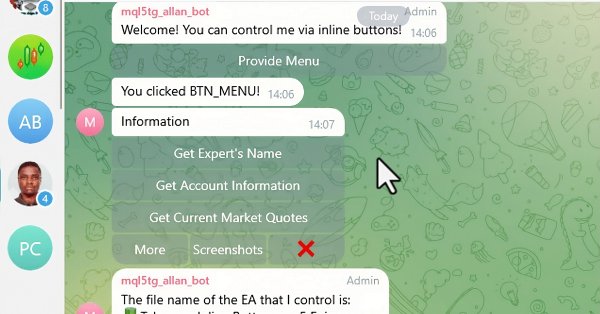
В этой статье мы интегрируем интерактивные встроенные кнопки в MQL5-советник, что позволяет осуществлять управление в режиме реального времени через Telegram. Каждое нажатие кнопки запускает определенные действия и отправляет ответы обратно пользователю. Мы также создадим функции для эффективной обработки Telegram-сообщений и callback-запросов.
Предлагаем познакомиться с фреймворком HiSSD, который объединяет иерархическое обучение и мультиагентные подходы для создания адаптивных систем. В этой работе мы подробно рассмотрим, как этот инновационный подход помогает выявлять скрытые закономерности на финансовых рынках и оптимизировать стратегии торговли в условиях децентрализации.
В настоящей статье улучшим оперативность работы панели администратора, созданную нами ранее. Кроме того, мы рассмотрим важность быстрого обмена сообщениями в контексте торговых сигналов.
Продолжаем работу над имплементацией подходов фреймворка CATCH, который объединяет преобразование Фурье и механизм частотного патчинга, обеспечивая точное выявление рыночных аномалий. В этой работе мы завершаем реализацию собственного видения предложенных подходов и проведем тестирование новых моделей на реальных исторических данных.
Хотите узнать, как извлекать выгоду из разницы в процентных ставках? В статье мы посмотрим, как использовать своп-арбитраж на Форексе, чтобы каждую ночь получать стабильный доход, создавая портфель, устойчивый к рыночным колебаниям.
Настоящий советник, получивший название SMOC (что, вероятно, означает оптимальное управление стохастической моделью (Stochastic Model Optimal Control), является простым примером передовой алгоритмической торговой системы для MetaTrader 5. Он использует комбинацию технических индикаторов, прогностического контроля моделей и динамического управления рисками для принятия торговых решений. Советник включает в себя адаптивные параметры, определение размера позиции на основе волатильности и анализ трендов для оптимизации его работы в изменяющихся рыночных условиях.
Фреймворк CATCH сочетает преобразование Фурье и частотный патчинг для точного выявления рыночных аномалий, недоступных традиционным методам. В данной работе мы рассмотрим, как этот подход раскрывает скрытые закономерности в финансовых данных.
В этой статье мы создадим несколько классов для облегчения взаимодействия в реальном времени между MQL5 и Telegram. Мы займемся извлечением команд из Telegram, их декодированием и интерпретацией, а также отправкой соответствующих ответов. Под конец мы протестируем эти взаимодействия и убедимся в их правильной работе в торговой среде.
Создаем адаптивный самообучающийся торговый советник на основе машинного обучения DQN, с многомерным причинно-следственным выводом, который будет успешно торговать одновременно на 7 валютных парах, причем агенты разных пар будут обмениваться друг с другом информацией.
Продолжаем построение алгоритмов, заложенные в основу фреймворка DADA — передового инструмента для обнаружения аномалий во временных рядах. Этот подход позволяет эффективно отличать случайные флуктуации от значимых отклонений. В отличие от классических методов, DADA динамически адаптируется к разным типам данных, выбирая оптимальный уровень сжатия в каждом конкретном случае.
Линейные ядра — простейшая матрица, используемая в машинном обучении для линейной регрессии и опорных векторных машин. Ядро Матерна (Matérn) представляет собой более универсальную версию радиальной базисной функции (Radial Basis Function, RBF), которую мы рассматривали в одной из предыдущих статей, и оно отлично подходит для отображения функций, которые не настолько гладкие, как предполагает RBF. Создадим специальный класс сигналов, который использует оба ядра для прогнозирования условий на покупку и продажу.
В настоящей статье мы разрабатываем торговый советник Rapid-Fire на MQL5, используя индикаторы Parabolic SAR и простую скользящую среднюю (SMA) для создания гибкой торговой стратегии. Мы подробно описываем реализацию стратегии, включая использование индикаторов, генерацию сигналов, а также процесс тестирования и оптимизации.
Обучение с подкреплением — один из трех основных принципов машинного обучения, наряду с обучением с учителем и без учителя. Поэтому возникает необходимость в оптимальном управлении или изучении наилучшей долгосрочной политики, которая наилучшим образом соответствует целевой функции. Именно на этом фоне мы исследуем его возможную роль в информировании процесса обучения MLP советника, собранного в Мастере.
Ранее мы обсуждали советник на основе индикатора, который также работал в паре с независимым скриптом для построения структуры риска и вознаграждения. Сегодня мы обсудим архитектуру MQL5-советника, объединяющего все функции в одной программе.
Сегодня разберем моего первого робота в сфере арбитража — поставщика ликвидности (если его можно так назвать) на синетических активах. Сегодня данный бот успешно работает как модуль в большой системе на машинном обучении, но я поднял старый арбитражный робот на Форекс из облака, и давайте посмотрим на него, и подумаем, что мы можем с ним сделать сегодня?
Предлагаем познакомиться с фреймворком DADA — инновационным методом выявления аномалий во временных рядах. Он помогает отличить случайные колебания от подозрительных отклонений. В отличие от традиционных методов, DADA гибко подстраивается под разные данные. Вместо фиксированного уровня сжатия он использует несколько вариантов и выбирает наиболее подходящий для каждого случая.
В этой статье мы реорганизуем существующий код отправки сообщений и скриншотов из MQL5 в Telegram, преобразовав его в многоразовые модульные функции. Это оптимизирует процесс, обеспечивая более эффективное выполнение и более простое управление кодом в нескольких экземплярах.
В настоящей статье представлено подробное руководство по реализации сложной торговой системы с использованием сетевого анализа причинно-следственных связей (CNA) и векторной авторегрессии (VAR) в MQL5. В ней излагаются теоретические основы этих методов, предлагаются подробные объяснения ключевых функций торгового алгоритма, а также приводится пример кода для реализации.
Сегодня мы рассмотрим, зачем нам нужна функция iSpread. Одновременно с этим мы поймем, как система информирует нас об оставшемся времени бара, когда для этого нет ни одного доступного тика. Представленные здесь материалы предназначены только для обучения. Ни в коем случае не рассматривайте его как окончательное приложение, целью которого не является изучение представленных концепций.
Рассмотрим создание арбитражной панели на языке MQl5. Как получать справедливые курсы валют на Forex разными способами? Создадим индикатор для получения отклонений рыночных цен от справедливых курсов, а также для оценки выгоды от арбитражных путей обмена одной валюты на другую (как в треугольном арбитраже).
Продолжаем реализацию подходов, предложенных авторами фреймворка DUET, который предлагает инновационный подход к анализу временных рядов, сочетая временную и канальную кластеризацию для выявления скрытых закономерностей в анализируемых данных.
Настоящая статья посвящена применению теории игр Джона Нэша, в частности теории равновесия Нэша, в трейдинге. В ней обсуждается, как трейдеры могут использовать скрипты Python и платформу MetaTrader 5 для выявления и использования неэффективности рынка спомощью принципов Нэша. В статье приводится пошаговое руководство по реализации этих стратегий, включая использование скрытых Марковских моделей (HMM) и статистического анализа, для повышения эффективности торговли.
Регрессия опорных векторов — это идеалистический способ поиска функции или "гиперплоскости" (hyper-plane), который наилучшим образом описывает взаимосвязь между двумя наборами данных. Мы попытаемся использовать его при прогнозировании временных рядов в пользовательских классах Мастера MQL5.
В этой статье обсудим, как можно создать советник, способный самостоятельно выбирать и менять торговые стратегии в зависимости от преобладающих на рынке условий. Познакомимся с цепями Маркова и с их возможностями с точки зрения пользы для нас, алготрейдеров.
Фреймворк DUET предлагает инновационный подход к анализу временных рядов, сочетая временную и канальную кластеризацию для выявления скрытых закономерностей в анализируемых данных. Это позволяет адаптировать модели к изменениям во времени и повысить качество прогнозирования за счет устранения шума.
Ограниченные машины Больцмана (Restricted Boltzmann Machines, RBM) — форма нейронной сети, разработанная в середине 1980-х годов, когда вычислительные ресурсы были непомерно дорогими. Вначале она опиралась на выборку Гиббса (Gibbs Sampling) и контрастивную дивергенцию (Contrastive Divergence) с целью уменьшения размерности или выявления скрытых вероятностей/свойств во входных обучающих наборах данных. Мы рассмотрим, как обратное распространение ошибки (backpropagation) может работать аналогичным образом, когда RBM "встраивает" (embeds) цены в прогнозирующий многослойный перцептрон.
В этой статье мы автоматизируем торговлю с помощью стратегии Parabolic SAR на MQL5, создав эффективный советник. Советник будет совершать сделки по трендам, определяемым индикатором Parabolic SAR.
В статье рассматривается торговая стратегия, объединяющая линейный дискриминантный анализ (Linear Discriminant Analysis, LDA) с полосами Боллинджера с использованием прогнозов категориальных зон для стратегических сигналов входа в рынок.