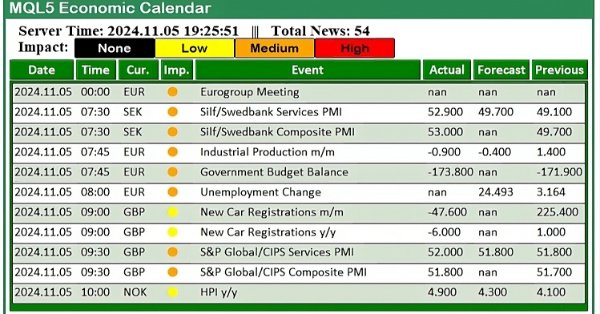
In this article, we create a practical news dashboard panel using the MQL5 Economic Calendar to enhance our trading strategy. We begin by designing the layout, focusing on key elements like event names, importance, and timing, before moving into the setup within MQL5. Finally, we implement a filtering system to display only the most relevant news, giving traders quick access to impactful economic events.
The moving averages and the stochastic oscillator could be used to generate trend following trading signals. However, these signals will only be observed after the price action has occurred. We can effectively overcome this inherent lag in technical indicators using AI. This article will teach you how to create a fully autonomous AI-powered Expert Advisor in a manner that can improve any of your existing trading strategies. Even the oldest trading strategy possible can be improved.
The authors of the FreDF method experimentally confirmed the advantage of combined forecasting in the frequency and time domains. However, the use of the weight hyperparameter is not optimal for non-stationary time series. In this article, we will get acquainted with the method of adaptive combination of forecasts in frequency and time domains.
The article explores the development of a quantum-inspired trading system, transitioning from a Python prototype to an MQL5 implementation for real-world trading. The system uses quantum computing principles like superposition and entanglement to analyze market states, though it runs on classical computers using quantum simulators. Key features include a three-qubit system for analyzing eight market states simultaneously, 24-hour lookback periods, and seven technical indicators for market analysis. While the accuracy rates might seem modest, they provide a significant edge when combined with proper risk management strategies.
This article will expand on the trade management class to include buy-stop and sell-stop orders to trade news events and implement an expiration constraint on these orders to prevent any overnight trading. A slippage function will be embedded into the expert to try and prevent or minimize possible slippage that may occur when using stop orders in trading, especially during news events.
In this article, we explore how to use the MQL5 Economic Calendar for trading by first understanding its core functionalities. We then implement key functions of the Economic Calendar in MQL5 to extract relevant news data for trading decisions. Finally, we conclude by showcasing how to utilize this information to enhance trading strategies effectively.
This article will dive into methods to improve the expert's runtime in the strategy tester, the code will be written to divide news event times into hourly categories. These news event times will be accessed within their specified hour. This ensures that the EA can efficiently manage event-driven trades in both high and low-volatility environments.
By studying the FEDformer method, we opened the door to the frequency domain of time series representation. In this new article, we will continue the topic we started. We will consider a method with which we can not only conduct an analysis, but also predict subsequent states in a particular area.
Today, we will discuss enhancing security for the Trading Administrator Panel currently under development. We will explore how to implement MQL5 in a new security strategy, integrating the Telegram API for two-factor authentication (2FA). This discussion will provide valuable insights into the application of MQL5 in reinforcing security measures. Additionally, we will examine the MathRand function, focusing on its functionality and how it can be effectively utilized within our security framework. Continue reading to discover more!
All the models we have considered so far analyze the state of the environment as a time sequence. However, the time series can also be represented in the form of frequency features. In this article, I introduce you to an algorithm that uses frequency components of a time sequence to predict future states.
In this article, we focus on transforming our static MQL5 dashboard panel into an interactive tool by enabling button responsiveness. We explore how to automate the functionality of the GUI components, ensuring they react appropriately to user clicks. By the end of the article, we establish a dynamic interface that enhances user engagement and trading experience.
In this article, we create an MQL5 Expert Advisor based on the Daily Range Breakout strategy. We cover the strategy’s key concepts, design the EA blueprint, and implement the breakout logic in MQL5. In the end, we explore techniques for backtesting and optimizing the EA to maximize its effectiveness.
Imagine a malicious actor infiltrating the Trading Administrator room, gaining access to the computers and the Admin Panel used to communicate valuable insights to millions of traders worldwide. Such an intrusion could lead to disastrous consequences, such as the unauthorized sending of misleading messages or random clicks on buttons that trigger unintended actions. In this discussion, we will explore the security measures in MQL5 and the new security features we have implemented in our Admin Panel to safeguard against these threats. By enhancing our security protocols, we aim to protect our communication channels and maintain the trust of our global trading community. Find more insights in this article discussion.
Learn how to develop and implement a comprehensive pending orders EX5 library in your MQL5 code or projects. This article will show you how to create an extensive pending orders management EX5 library and guide you through importing and implementing it by building a trading panel or graphical user interface (GUI). The expert advisor orders panel will allow users to open, monitor, and delete pending orders associated with a specified magic number directly from the graphical interface on the chart window.
Join us as we empirically analyzed the MACD indicator, to test if applying AI to a strategy, including the indicator, would yield any improvements in our accuracy on forecasting the EURUSD. We simultaneously assessed if the indicator itself is easier to predict than price, as well as if the indicator's value is predictive of future price levels. We will furnish you with the information you need to decide whether you should consider investing your time into integrating the MACD in your AI trading strategies.
In this article, we create an interactive trading dashboard using the Controls class in MQL5, designed to streamline trading operations. The panel features a title, navigation buttons for Trade, Close, and Information, and specialized action buttons for executing trades and managing positions. By the end of the article, you will have a foundational panel ready for further enhancements in future installments.
In this article, we create an Expert Advisor (EA) in MQL5 based on the PIRANHA strategy, utilizing Bollinger Bands to enhance trading effectiveness. We discuss the key principles of the strategy, the coding implementation, and methods for testing and optimization. This knowledge will enable you to deploy the EA in your trading scenarios effectively
In this discussion, we will carefully extend the existing Dialog library to incorporate theme management logic. Furthermore, we will integrate methods for theme switching into the CDialog, CEdit, and CButton classes utilized in our Admin Panel project. Continue reading for more insightful perspectives.
Create a trading journal using MetaTrader and Google Sheets! You will learn how to sync your trading data via HTTP POST and retrieve it using HTTP requests. In the end, You have a trading journal that will help you keep track of your trades effectively and efficiently.
Problem-solving can establish a concise routine for mastering complex skills, such as programming in MQL5. This approach allows you to concentrate on solving problems while simultaneously developing your skills. The more problems you tackle, the more advanced expertise is transferred to your brain. Personally, I believe that debugging is the most effective way to master programming. Today, we will walk through the code-cleaning process and discuss the best techniques for transforming a messy program into a clean, functional one. Read through this article and uncover valuable insights.
The objectives of this article are to prove the necessity of using a risk manager and to implement the principles of controlled risk in algorithmic trading in a separate class, so that everyone can verify the effectiveness of the risk standardization approach in intraday trading and investing in financial markets. In this article, we will create a risk manager class for algorithmic trading. This is a logical continuation of the previous article in which we discussed the creation of a risk manager for manual trading.
In this article, we explore how to integrate Telegram commands with MQL5 to automate the addition of indicators on trading charts. We cover the process of parsing user commands, executing them in MQL5, and testing the system to ensure smooth indicator-based trading
In an attempt to obtain the most accurate forecasts, researchers often complicate forecasting models. Which in turn leads to increased model training and maintenance costs. Is such an increase always justified? This article introduces an algorithm that uses the simplicity and speed of linear models and demonstrates results on par with the best models with a more complex architecture.
This MetaTrader 5 Expert Advisor implements a Scalping OrderFlow strategy with advanced risk management. It uses multiple technical indicators to identify trading opportunities based on order flow imbalances. Backtesting shows potential profitability but highlights the need for further optimization, especially in risk management and trade outcome ratios. Suitable for experienced traders, it requires thorough testing and understanding before live deployment.
This project explores the fusion of deep learning and technical analysis to test trading strategies in forex. A Python script is used for rapid experimentation, employing an ONNX model alongside traditional indicators like PSAR, SMA, and RSI to predict EUR/USD movements. A MetaTrader 5 script then brings this strategy into a live environment, using historical data and technical analysis to make informed trading decisions. The backtesting results indicate a cautious yet consistent approach, with a focus on risk management and steady growth rather than aggressive profit-seeking.
We will add Deep Learning to those three examples that were published in previous articles and compare results with previous. The aim is to learn how to add DL to other EA.
In this article, we will focus on visually styling the graphical user interface (GUI) of our Trading Administrator Panel using MQL5. We’ll explore various techniques and features available in MQL5 that allow for customization and optimization of the interface, ensuring it meets the needs of traders while maintaining an attractive aesthetic.
Step by step guide for auto optimization in MQL5 for Expert Advisors. We will cover robust optimization logic, best practices for parameter selection, and how to reconstruct strategies with back-testing. Additionally, higher-level methods like walk-forward optimization will be discussed to enhance your trading approach.
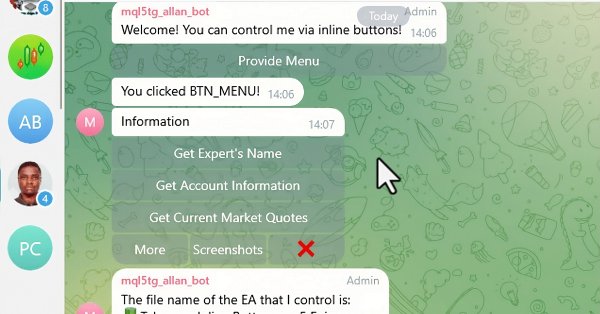
In this article, we integrate interactive inline buttons into an MQL5 Expert Advisor, allowing real-time control via Telegram. Each button press triggers specific actions and sends responses back to the user. We also modularize functions for handling Telegram messages and callback queries efficiently.
Dynamic multi pair Expert Advisor leverages both on correlation and inverse correlation strategies to optimize trading performance. By analyzing real-time market data, it identifies and exploits the relationship between currency pairs.
In this article, we create several classes to facilitate real-time communication between MQL5 and Telegram. We focus on retrieving commands from Telegram, decoding and interpreting them, and sending appropriate responses back. By the end, we ensure that these interactions are effectively tested and operational within the trading environment
In this article, I would like to introduce you to a new complex timeseries forecasting method, which harmoniously combines the advantages of linear models and transformers.
We already know that pre-processing of the input data plays a major role in the stability of model training. To process "raw" input data online, we often use a batch normalization layer. But sometimes we need a reverse procedure. In this article, we discuss one of the possible approaches to solving this problem.
In this article, we refactor the existing code used for sending messages and screenshots from MQL5 to Telegram by organizing it into reusable, modular functions. This will streamline the process, allowing for more efficient execution and easier code management across multiple instances.
This article introduces the Conformer algorithm originally developed for the purpose of weather forecasting, which in terms of variability and capriciousness can be compared to financial markets. Conformer is a complex method. It combines the advantages of attention models and ordinary differential equations.
This article presents a comprehensive guide to implementing a sophisticated trading system using Causality Network Analysis (CNA) and Vector Autoregression (VAR) in MQL5. It covers the theoretical background of these methods, provides detailed explanations of key functions in the trading algorithm, and includes example code for implementation.