In this article, we will talk about algorithms for using attention methods in solving problems of detecting objects in a point cloud. Object detection in point clouds is important for many real-world applications.
Portfolio Diversification and Optimization strategically spreads investments across multiple assets to minimize risk while selecting the ideal asset mix to maximize returns based on risk-adjusted performance metrics.
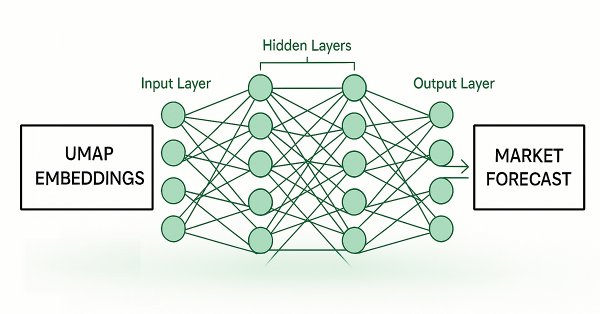
Dimension reduction techniques are widely used to improve the performance of machine learning models. Let us discuss a relatively new technique known as Uniform Manifold Approximation and Projection (UMAP). This new technique has been developed to explicitly overcome the limitations of legacy methods that create artifacts and distortions in the data. UMAP is a powerful dimension reduction technique, and it helps us group similar candle sticks in a novel and effective way that reduces our error rates on out of sample data and improves our trading performance.
In this article, we design a custom MQL5 toolkit for easy manual backtesting in the Strategy Tester. We explain its design and implementation, focusing on interactive trade controls. We then show how to use it to test strategies effectively
In this article, we introduce a trade layering strategy that combines MACD and RSI indicators with statistical methods to automate dynamic trading in MQL5. We explore the architecture of this cascading approach, detail its implementation through key code segments, and guide readers on backtesting to optimize performance. Finally, we conclude by highlighting the strategy’s potential and setting the stage for further enhancements in automated trading.
We continue to study algorithms for extracting features from a point cloud. In this article, we will get acquainted with the mechanisms for increasing the efficiency of the PointNet method.
In this discussion, we explore how to retrieve real-time market data and trading account information, perform various calculations, and display the results on a custom panel. To achieve this, we will dive deeper into developing an AnalyticsPanel class that encapsulates all these features, including panel creation. This effort is part of our ongoing expansion of the New Admin Panel EA, introducing advanced functionalities using modular design principles and best practices for code organization.
Direct point cloud analysis avoids unnecessary data growth and improves the performance of models in classification and segmentation tasks. Such approaches demonstrate high performance and robustness to perturbations in the original data.
This article explores the potential of the Value at Risk (VaR) model for multi-currency portfolio optimization. Using the power of Python and the functionality of MetaTrader 5, we demonstrate how to implement VaR analysis for efficient capital allocation and position management. From theoretical foundations to practical implementation, the article covers all aspects of applying one of the most robust risk calculation systems – VaR – in algorithmic trading.
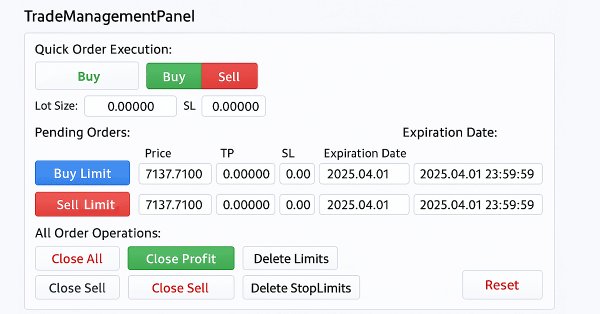
This discussion covers the updated TradeManagementPanel in our New_Admin_Panel EA. The update enhances the panel by using built-in classes to offer a user-friendly trade management interface. It includes trading buttons for opening positions and controls for managing existing trades and pending orders. A key feature is the integrated risk management that allows setting stop loss and take profit values directly in the interface. This update improves code organization for large programs and simplifies access to order management tools, which are often complex in the terminal.
We continue studying the Hierarchical Vector Transformer method. In this article, we will complete the construction of the model. We will also train and test it on real historical data.
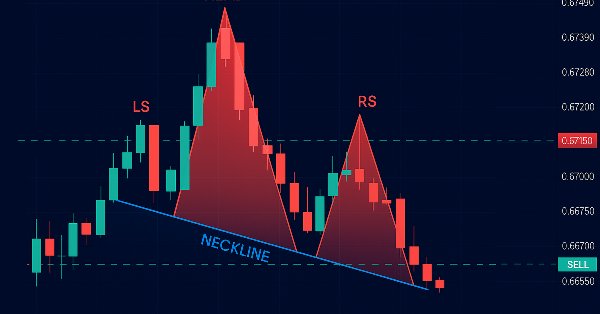
In this article, we automate the Head and Shoulders pattern in MQL5. We analyze its architecture, implement an EA to detect and trade it, and backtest the results. The process reveals a practical trading algorithm with room for refinement.
Learn to build a Harmonic Pattern indicator in MQL5 using chart objects. Discover how to detect swing points, apply Fibonacci retracements, and automate pattern recognition.
This article explores optimizing RSI levels and periods for better trading signals. We introduce methods to estimate optimal RSI values and automate period selection using grid search and statistical models. Finally, we implement the solution in MQL5 while leveraging Python for analysis. Our approach aims to be pragmatic and straightforward to help you solve potentially complicated problems, with simplicity.
We invite you to get acquainted with the Hierarchical Vector Transformer (HiVT) method, which was developed for fast and accurate forecasting of multimodal time series.
In this article, we build an MQL5 trading system that automates order block detection for Smart Money trading. We outline the strategy’s rules, implement the logic in MQL5, and integrate risk management for effective trade execution. Finally, we backtest the system to assess its performance and refine it for optimal results.
Understanding agent behavior is important in many different areas, but most methods focus on just one of the tasks (understanding, noise removal, or prediction), which reduces their effectiveness in real-world scenarios. In this article, we will get acquainted with a model that can adapt to solving various problems.
Join us for an in-depth discussion on the latest advancements in MQL5 interface design as we unveil the redesigned Communications Panel and continue our series on building the New Admin Panel using modularization principles. We'll develop the CommunicationsDialog class step by step, thoroughly explaining how to inherit it from the Dialog class. Additionally, we'll leverage arrays and ListView class in our development. Gain actionable insights to elevate your MQL5 development skills—read through the article and join the discussion in the comments section!
In this article, I would like to introduce you to an interesting trajectory prediction method developed to solve problems in the field of autonomous vehicle movements. The authors of the method combined the best elements of various architectural solutions.
In this article, we develop a multi-level grid trading system EA using MQL5, focusing on the architecture and algorithm design behind grid trading strategies. We explore the implementation of multi-layered grid logic and risk management techniques to handle varying market conditions. Finally, we provide detailed explanations and practical tips to guide you through building, testing, and refining the automated trading system.
A large number of the models we have reviewed so far are based on the Transformer architecture. However, they may be inefficient when dealing with long sequences. And in this article, we will get acquainted with an alternative direction of time series forecasting based on state space models.
In our previous article, we introduced a simple script called "The Quarters Drawer." Building on that foundation, we are now taking the next step by creating a monitor Expert Advisor (EA) to track these quarters and provide oversight regarding potential market reactions at these levels. Join us as we explore the process of developing a zone detection tool in this article.
Discover how to effortlessly import and utilize the History Manager EX5 library in your MQL5 source code to process trade histories in your MetaTrader 5 account in this series' final article. With simple one-line function calls in MQL5, you can efficiently manage and analyze your trading data. Additionally, you will learn how to create different trade history analytics scripts and develop a price-based Expert Advisor as practical use-case examples. The example EA leverages price data and the History Manager EX5 library to make informed trading decisions, adjust trade volumes, and implement recovery strategies based on previously closed trades.
This article guides you through building a custom Heikin Ashi indicator from scratch and demonstrates how to integrate custom indicators into an EA. It covers indicator calculations, trade execution logic, and risk management techniques to enhance automated trading strategies.
In this article, we develop an Expert Advisor in MQL5 for the Trend Flat Momentum Strategy. We combine a two moving averages crossover with RSI and CCI momentum filters to generate trade signals. We also cover backtesting and potential enhancements for real-world performance.
Points of support and resistance are critical levels that signal potential trend reversals and continuations. Although identifying these levels can be challenging, once you pinpoint them, you’re well-prepared to navigate the market. For further assistance, check out the Quarters Drawer tool featured in this article, it will help you identify both primary and minor support and resistance levels.
In this article, we implement automated trade entry using the MQL5 Economic Calendar by applying user-defined filters and time offsets to identify qualifying news events. We compare forecast and previous values to determine whether to open a BUY or SELL trade. Dynamic countdown timers display the remaining time until news release and reset automatically after a trade.
In this article, we build an Expert Advisor in MQL5 for the Asian Breakout Strategy by calculating the session's high and low and applying trend filtering with a moving average. We implement dynamic object styling, user-defined time inputs, and robust risk management. Finally, we demonstrate backtesting and optimization techniques to refine the program.
In this article, we build an MQL5 Expert Advisor to detect Butterfly harmonic patterns. We identify pivot points and validate Fibonacci levels to confirm the pattern. We then visualize the pattern on the chart and automatically execute trades when confirmed.
Most modern multimodal time series forecasting methods use the independent channels approach. This ignores the natural dependence of different channels of the same time series. Smart use of two approaches (independent and mixed channels) is the key to improving the performance of the models.
Join us in our discussion today as we look for an algorithmic procedure to minimize the total number of times we get stopped out of winning trades. The problem we faced is significantly challenging, and most solutions given in community discussions lack set and fixed rules. Our algorithmic approach to solving the problem increased the profitability of our trades and reduced our average loss per trade. However, there are further advancements to be made to completely filter out all trades that will be stopped out, our solution is a good first step for anyone to try.
We continue our acquaintance with the TEMPO method. In this article we will evaluate the actual effectiveness of the proposed approaches on real historical data.
Embracing technical indicators in price action analysis is a powerful approach. These indicators often highlight key levels of reversals and retracements, offering valuable insights into market dynamics. In this article, we demonstrate how we developed an automated tool that generates signals using the Parabolic SAR indicator.
In this article, we build a grid trading expert advisor in MQL5 that uses dynamic lot scaling. We cover the strategy design, code implementation, and backtesting process. Finally, we share key insights and best practices for optimizing the automated trading system.
In this discussion, we take a step further in breaking down our MQL5 program into smaller, more manageable modules. These modular components will then be integrated into the main program, enhancing its organization and maintainability. This approach simplifies the structure of our main program and makes the individual components reusable in other Expert Advisors (EAs) and indicator developments. By adopting this modular design, we create a solid foundation for future enhancements, benefiting both our project and the broader developer community.
We continue to study time series forecasting models. In this article, we get acquainted with a complex algorithm built on the use of a pre-trained language model.
In this article, we automate order block detection in MQL5 using pure price action analysis. We define order blocks, implement their detection, and integrate automated trade execution. Finally, we backtest the strategy to evaluate its performance.
Lightweight time series forecasting models achieve high performance using a minimum number of parameters. This, in turn, reduces the consumption of computing resources and speeds up decision-making. Despite being lightweight, such models achieve forecast quality comparable to more complex ones.
This discussion delves into the challenges encountered when working with large codebases. We will explore the best practices for code organization in MQL5 and implement a practical approach to enhance the readability and scalability of our Trading Administrator Panel source code. Additionally, we aim to develop reusable code components that can potentially benefit other developers in their algorithm development. Read on and join the conversation.