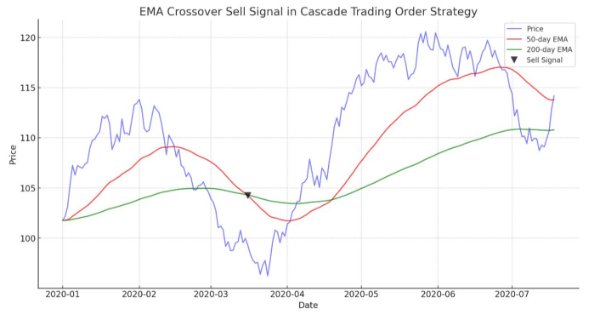
Este artigo orienta sobre como demonstrar um algoritmo automatizado baseado em cruzamentos de EMA para MetaTrader 5. Informações detalhadas sobre todos os aspectos de demonstrar um Expert Advisor em MQL5 e testá-lo no MetaTrader 5 – desde a análise de comportamentos de faixa de preços até o gerenciamento de risco.
Melhorar o painel GUI do MQL5 com recursos dinâmicos pode melhorar significativamente a experiência de negociação para os usuários. Ao incorporar elementos interativos, efeitos de hover e atualizações de dados em tempo real, o painel se torna uma ferramenta poderosa para os traders modernos.
Conceito de Smart Money (Break Of Structure) acoplado com o Indicador RSI para tomar decisões informadas de negociação automatizada com base na estrutura do mercado.
O artigo discute, de forma detalhada, como implementar a criação de um Expert Advisor (EA) baseado no algoritmo de negociação. Isso ajuda a automatizar o sistema em MQL5 e a controlar o Drawdown Diário.
Neste artigo, explicarei alguns detalhes e cuidados que você teve tomar quando for criar um protocolo de comunicação. São coisas bem básicas e simples. Não irei de fato pegar pesado neste artigo. Mas é preciso que você entenda o conteúdo deste artigo para entender o que acontecerá no receptor.
O Ângulo de Ataque é uma métrica frequentemente citada, cuja inclinação é entendida como tendo uma forte correlação com a força de uma tendência predominante. Vamos analisar como ele é comumente usado e compreendido e examinar se há mudanças que poderiam ser introduzidas na forma como é medido, para benefício de um sistema de negociação que o utilize.
Continuaremos automatizando etapas que anteriormente realizávamos manualmente. Desta vez, voltaremos à automação da segunda etapa, ou seja, a escolha do grupo ideal de instâncias individuais de estratégias de negociação, complementada pela capacidade de considerar os resultados dessas instâncias no período forward.
Imagine que você pode usar dados que não estão disponíveis no MetaTrader, você só obtém dados de indicadores por análise de preços e análise técnica. Agora imagine que você pode acessar dados que levarão seu poder de negociação a um novo nível. Você pode multiplicar o poder do software MetaTrader se misturar a saída de outros softwares, métodos de análise macroeconômica e ferramentas ultra-avançadas por meio da API de dados. Neste artigo, vamos ensinar como usar APIs e apresentar serviços de dados API úteis e valiosos.
O Exponente de Hurst é uma medida de quanto uma série temporal se autocorrela ao longo do tempo. Entende-se que ele captura as propriedades de longo prazo de uma série temporal e, portanto, tem um peso significativo na análise de séries temporais, mesmo fora do contexto econômico/financeiro. No entanto, focamos em seu potencial benefício para os traders ao analisar como essa métrica poderia ser combinada com médias móveis para construir um sinal potencialmente robusto.
Neste artigo, aplicamos um algoritmo relativamente complexo de rede neural chamado PatchTST, lançado em 2023, para prever a ação do preço nas próximas 24 horas. Usaremos o repositório oficial, faremos algumas modificações, treinaremos um modelo para EURUSD e o aplicaremos para fazer previsões futuras, tanto em Python quanto em MQL5.
Atualmente, nosso EA utiliza um banco de dados para obter as strings de inicialização de instâncias individuais de estratégias de trading. No entanto, o banco de dados é bastante volumoso e contém muitas informações desnecessárias para a operação real do EA. Tentaremos garantir o funcionamento do EA sem a necessidade de conexão obrigatória ao banco de dados.
Neste artigo, vamos introduzir a Análise de Sentimento e Modelos ONNX com Python para serem usados em um EA. Um script executa um modelo ONNX treinado do TensorFlow para previsões de deep learning, enquanto outro busca manchetes de notícias e quantifica o sentimento usando IA.
Por padrão, estratégias baseadas em múltiplos timeframes não podem ser testadas em Expert Advisors montados pelo assistente devido à arquitetura de código MQL5 utilizada nas classes de montagem. Exploramos uma possível solução para essa limitação em estratégias que utilizam múltiplos timeframes em um estudo de caso com a média móvel quadrática.
Este artigo explora os passos fundamentais para criar e implementar um painel de Interface Gráfica de Usuário (GUI) utilizando a Linguagem MetaQuotes 5 (MQL5). Painéis utilitários personalizados melhoram a interação do usuário no trading, simplificando tarefas comuns e visualizando informações essenciais de trading. Ao criar painéis personalizados, os traders podem otimizar seu fluxo de trabalho e economizar tempo durante as operações de trading.
O EA em desenvolvimento deve apresentar bons resultados ao operar com diferentes corretoras. Porém, até agora, os testes foram realizados com base em cotações de uma conta de demonstração da MetaQuotes. Vamos verificar se o EA está pronto para operar em contas reais com cotações diferentes das utilizadas durante os testes e otimizações.
Neste artigo vamos compreender como o código faltante no artigo anterior, DispatchMessage, funciona. Aqui será feita a introdução do que será visto no próximo artigo. Sendo assim é importante compreender o funcionamento deste procedimento antes de ver o próximo artigo. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.
É possível aplicar a teoria do caos nos mercados financeiros? Vamos explorar nesta matéria como a teoria clássica do caos e os sistemas caóticos diferem do conceito proposto por Bill Williams.
À medida que nos aproximamos de um EA pronto, é necessário prestar atenção em questões secundárias na etapa de teste da estratégia de trading, mas que se tornam importantes ao migrar para o trading real.
O gerenciador de risco anteriormente desenvolvido continha apenas funcionalidades básicas. Vamos explorar caminhos para aprimorá-lo, buscando melhorar os resultados de negociação sem alterar a lógica das estratégias de trading.
Neste artigo, revisitamos a clássica estratégia de cruzamento de médias móveis para avaliar sua eficácia atual. Dado o tempo desde sua criação, exploramos os possíveis aprimoramentos que a IA pode trazer a essa estratégia de negociação tradicional. Ao incorporar técnicas de IA, nosso objetivo é aproveitar as capacidades preditivas avançadas para otimizar pontos de entrada e saída de operações, adaptar-se a condições de mercado variáveis e melhorar o desempenho geral em comparação com abordagens convencionais.
Esta parte da série de artigos é dedicada à integração do WhatsApp com o MetaTrader 5 para notificações. Incluímos um fluxograma para simplificar o entendimento e discutiremos a importância das medidas de segurança na integração. O principal objetivo dos indicadores é simplificar a análise por meio da automação, e eles devem incluir métodos de notificação para alertar os usuários quando condições específicas forem atendidas. Descubra mais neste artigo.
Este artigo é um pouco diferente dos trabalhos anteriores desta série. Nele, discutiremos uma representação alternativa de séries temporais. A representação linear por partes de séries temporais é um método de aproximação de séries temporais usando funções lineares em pequenos intervalos.
Ao estudar diferentes arquiteturas de construção de modelos, temos dado pouca atenção ao processo de treinamento dos modelos. Neste artigo, tentarei preencher essa lacuna.
A extração e integração eficazes de dependências de longo prazo e características de curto prazo continuam sendo uma tarefa importante na análise de séries temporais. Compreendê-las e integrá-las corretamente é necessário para criar modelos preditivos precisos e confiáveis.
Continuamos o ciclo de artigos sobre a criação de um robô de negociação em Python e MQL5. Hoje, vamos abordar a tarefa de desenvolver um algoritmo de negociação em Python.
Os modelos baseados na arquitetura Transformer demonstram alta eficiência, mas seu uso é dificultado pelos altos custos de recursos, tanto na fase de treinamento quanto durante a utilização prática. Neste artigo, proponho conhecer algoritmos que permitem reduzir o uso de memória por esses modelos.
Na primeira parte deste artigo, mergulharemos no mundo das reações químicas e descobriremos uma nova abordagem para a otimização! O método de otimização por reações químicas (CRO) utiliza os princípios das leis da termodinâmica para alcançar resultados eficazes. Revelaremos os segredos da decomposição, síntese e outros processos químicos que servem de base para este método inovador.
Neste artigo, adicionaremos herança ao código anterior e ao novo. Implementaremos uma nova estrutura de banco de dados para garantir um bom desempenho. Além disso, criaremos uma classe de gerenciamento de risco para calcular volumes.
Ao estudarmos o método FEDformer, abrimos uma porta para a área de representação de séries temporais no domínio da frequência. No novo artigo, continuaremos o tema iniciado, e analisaremos um método que permite não apenas conduzir uma análise, mas também prever estados futuros no domínio frequencial.
Os objetivos deste artigo são: demonstrar a necessidade obrigatória de um gerenciador de riscos, adaptar os princípios de controle de risco para trading algorítmico em uma classe específica, permitindo que todos possam comprovar, de forma independente, a eficácia da abordagem de normalização de risco no day trading e em investimentos nos mercados financeiros. Neste artigo, exploraremos em detalhes a criação de uma classe de gerenciador de riscos para trading algorítmico, continuando o tópico abordado no artigo anterior sobre o gerenciador de riscos para trading manual.
Médias Móveis são um indicador muito comum, usado e compreendido pela maioria dos traders. Exploramos possíveis casos de uso que podem não ser tão comuns dentro dos Expert Advisors montados no MQL5 Wizard.
Este artigo é voltado para desenvolvedores iniciantes e experientes em MQL5. Ele oferece um código que define indicadores para gerar sinais, limitando-os com base nas tendências de timeframes mais altos. Dessa forma, traders podem aprimorar suas estratégias ao incluir uma visão mais ampla do mercado, o que pode resultar em sinais de negociação potencialmente mais confiáveis.
Hoje, estamos discutindo uma integração funcional do Telegram para notificações do Indicador MetaTrader 5 usando o poder do MQL5, em parceria com Python e a API do Bot do Telegram. Explicaremos tudo em detalhes para que ninguém perca nenhum ponto. Ao final deste projeto, você terá adquirido conhecimentos valiosos para aplicar em seus projetos.
Escreveremos do zero um script para facilitar a captura de capturas de tela (print-screens) de negociações, visando a análise de entradas. Em um único gráfico, será conveniente exibir todas as informações necessárias sobre uma negociação específica, com a possibilidade de desenhar diferentes timeframes.
Um guia abrangente para desenvolver um algoritmo de negociação automatizado baseado na estratégia de Suporte e Resistência. Informações detalhadas sobre todos os aspectos da criação de um expert advisor em MQL5 e testá-lo no MetaTrader 5 – desde a análise dos comportamentos de faixa de preço até o gerenciamento de risco.
Ao trabalhar com séries temporais, geralmente usamos os dados na sequência histórica. Mas isso é realmente o mais eficiente? Há quem acredite que modificar a sequência dos dados iniciais pode aumentar a eficácia dos modelos de aprendizado. Neste artigo, vou apresentar um desses métodos.
A primeira etapa do processo automatizado de otimização já foi implementada. Para diferentes símbolos e timeframes, realizamos a otimização com base em vários critérios e armazenamos as informações dos resultados de cada execução em um banco de dados. Agora, vamos nos dedicar à seleção dos melhores grupos de conjuntos de parâmetros encontrados na primeira etapa.
Dividiremos o código principal do MQL5 em trechos específicos para ilustrar a integração do Telegram e WhatsApp para receber notificações de sinais do indicador de Restrição de Tendência que estamos criando nesta série de artigos. Isso ajudará traders, tanto iniciantes quanto desenvolvedores experientes, a compreender o conceito com mais facilidade. Primeiro, abordaremos a configuração do MetaTrader 5 para notificações e sua importância para o usuário. Isso ajudará os desenvolvedores a tomarem nota antecipadamente para aplicar posteriormente em seus sistemas.
O artigo discute, de forma detalhada, os passos que precisam ser implementados para a criação de um advisor especializado baseado no algoritmo de negociação de Recuperação de Zona. Isso ajuda a automatizar o sistema, economizando tempo para os negociadores algorítmicos.