Continuamos nuestro análisis de los algoritmos de aprendizaje por refuerzo en problemas de espacio continuo de acciones. En este artículo, le propongo introducir el algoritmo Soft Astog-Critic (SAC). La principal ventaja del SAC es su capacidad para encontrar políticas óptimas que no solo maximicen la recompensa esperada, sino que también tengan la máxima entropía (diversidad) de acciones.
En este artículo, ofreceremos una guía sencilla y comprensible para cualquier usuario que quiera crear una de las herramientas más valiosas y útiles en el trading: un panel gráfico que facilite las tareas comerciales. Los paneles gráficos nos permiten ahorrar tiempo y centrarnos más en las operaciones en sí.
Las combinaciones de estrategias pueden mejorar el rendimiento de las transacciones. Podemos combinar indicadores y patrones para obtener confirmaciones adicionales. Las medias móviles nos ayudan a confirmar tendencias y seguirlas. Se trata del indicador técnico más famoso, lo cual se explica por su sencillez y su probada eficacia de análisis.
En el artículo anterior, presentamos el método DDPG, que nos permite entrenar modelos en un espacio de acción continuo. Sin embargo, al igual que otros métodos de aprendizaje Q, el DDPG tiende a sobreestimar los valores de la función Q. Con frecuencia, este problema provoca que entrenemos los agentes con una estrategia subóptima. En el presente artículo, analizaremos algunos enfoques para superar el problema mencionado.
Descubra el potencial de la presentación dinámica de datos en sus estrategias y utilidades comerciales con nuestra guía detallada para crear GUI móviles en MQL5. Sumérjase en los principios fundamentales de la programación orientada a objetos y aprenda a diseñar y utilizar de manera fácil y eficiente una o más GUI móviles en un solo gráfico.
El presente artículo representa el primer intento de desarrollar un cliente MQTT nativo para MQL5. El MQTT es un protocolo de comunicación "publicación-suscripción". Es ligero, abierto, simple y está diseñado para implementarse con facilidad, lo cual permite su uso en muchas situaciones.
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).
Como desarrolladores, debemos aprender a crear y desarrollar software que sea reutilizable y flexible sin duplicar código, especialmente si tenemos diferentes objetos con comportamientos distintos. Esto se puede lograr fácilmente utilizando las técnicas y principios de la programación orientada a objetos. En este artículo le presentamos los conceptos básicos de la programación orientada a objetos en MQL5.
En este artículo ampliamos el abanico de tareas de nuestro agente. El proceso de entrenamiento incluirá algunos aspectos de la gestión de capital y del riesgo que forma parte integral de cualquier estrategia comercial.
En este artículo, experimentaremos y analizaremos la inteligencia artificial ChatGPT de OpenAI para comprender sus capacidades y reducir el tiempo y la intensidad del trabajo en el desarrollo de nuestros asesores, indicadores y scripts. Asimismo, repasaremos rápidamente esta tecnología e intentaremos ver cómo usarla correctamente para programar en MQL4 y MQL5.
En el artículo de hoy, nos familiarizaremos con otra tendencia en el campo del aprendizaje por refuerzo. Se denomina aprendizaje por refuerzo dirigido a objetivos (Goal-conditioned reinforcement learning, GCRL). En este enfoque, el agente se entrenará para alcanzar diferentes objetivos en determinados escenarios.
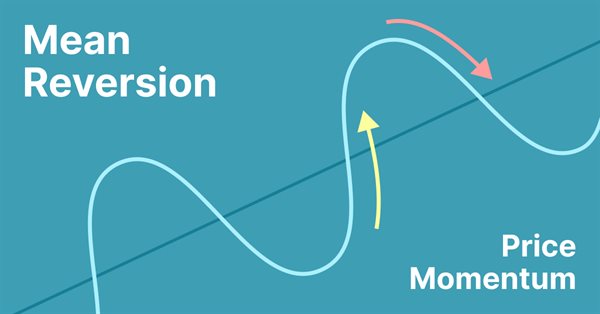
La reversión a la media es una técnica de negociación de contratendencia en la que el tráder espera que el precio regrese a algún tipo de equilibrio, que generalmente se mide usando una media u otro indicador estadístico de la tendencia promediada.
El entrenamiento de habilidades útiles sin una función de recompensa explícita es uno de los principales desafíos del aprendizaje por refuerzo jerárquico. Ya nos hemos familiarizado antes con dos algoritmos para resolver este problema, pero el tema de la exploración del entorno sigue abierto. En este artículo, veremos un enfoque distinto en el entrenamiento de habilidades, cuyo uso dependerá directamente del estado actual del sistema.
Existen muchas herramientas técnicas que se pueden usar para visualizar los canales de precios. Una de esas herramientas es el canal de Donchian. En este artículo, aprenderemos cómo crear un canal de Donchian, y también a usarlo como indicador personalizado dentro de un asesor experto.
En el artículo anterior, nos familiarizamos con el método DIAYN, que ofrece un algoritmo para el aprendizaje de diversas habilidades. El uso de las habilidades aprendidas puede aprovecharse en diversas tareas, pero estas habilidades pueden resultar bastante impredecibles, lo cual puede dificultar su uso. En este artículo, analizaremos un algoritmo para el aprendizaje de habilidades predecibles.
Les presento un nuevo artículo sobre la creación de indicadores personalizados. Esta vez trabajaremos con el True Strength Index (TSI) y crearemos un asesor basado en él.
El artículo presenta un método para detectar automáticamente patrones de acción del precio usando MQL5, tales como tendencias (ascendentes, descendentes, laterales) y patrones de gráficos (pico doble, valle doble).
Libere el poder de la presentación dinámica de datos en sus estrategias o utilidades comerciales con nuestra guía detallada para desarrollar una GUI móvil en MQL5. Sumérjase en los eventos del gráfico y aprenda a diseñar e implementar una GUI simple y con capacidad de movimiento múltiple en un solo gráfico. El artículo también analizará la adición de elementos a una interfaz gráfica, aumentando su funcionalidad y atractivo estético.
El problema del aprendizaje por refuerzo reside en la necesidad de definir una función de recompensa, que puede ser compleja o difícil de formalizar. Para resolver esto, se están estudiando enfoques basados en la variedad de acciones y la exploración del entorno que permiten aprender habilidades sin una función de recompensa explícita.
En este artículo crearemos un modelo matemático para simular la formación de precios multidivisa y completaremos el estudio del principio de diversificación en la búsqueda de mecanismos para aumentar la eficiencia del trading que inicié en el artículo anterior con cálculos teóricos.
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.
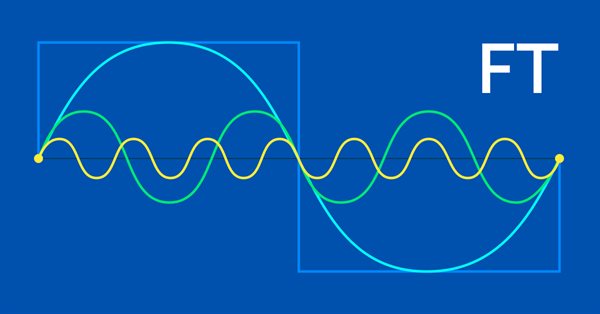
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.
Uno de los principales retos del aprendizaje por refuerzo es la exploración del entorno. Con anterioridad, hemos aprendido un método de exploración basado en la curiosidad interior. Hoy queremos examinar otro algoritmo: la exploración mediante el desacuerdo.
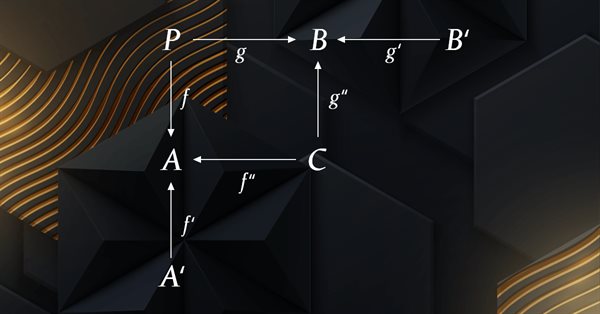
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Aquí presentamos los monoides como un dominio (conjunto) que distingue la teoría de categorías de otros métodos de clasificación de datos al incluir reglas y un elemento de identidad.
Hoy utilizaremos un enfoque comercial de cuadrícula con órdenes stop pendientes en un asesor experto en el lenguaje de estrategias comerciales MQL5 para MetaTrader 5 en la Bolsa de Moscú (MOEX). Al comerciar en el mercado, una de las estrategias más simples consiste en colocar una cuadrícula de órdenes diseñada para "atrapar" el precio del mercado.
En este artículo, usaremos el algoritmo de recompra como guía en un mundo con una mayor comprensión de la efectividad de los sistemas comerciales y comenzaremos a trabajar en los principios generales para mejorar la eficiencia comercial usando las matemáticas y la lógica; también aplicaremos los métodos menos comunes para aumentar la eficiencia en el contexto del uso de cualquier sistema comercial.
Ejemplo de utilización de un perceptrón como herramienta autónoma de predicción de precios. En el artículo exploraremos los conceptos generales y veremos un sencillo asesor experto ya preparado, así como los resultados de su optimización.
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.
¿Quiere encontrar un nuevo enfoque comercial que lo ayude a orientarse en mercados complejos y en cambio constante? Eche un vistazo a los mapas de Kohonen, una forma innovadora de redes neuronales artificiales que puede ayudarle a descubrir patrones y tendencias ocultos en los datos del mercado. En este artículo, veremos cómo funcionan los mapas de Kohonen y cómo usarlos para desarrollar estrategias comerciales efectivas. Creo que este nuevo enfoque resultará de interés tanto a los tráders experimentados como para los principiantes.
En este artículo, veremos una plantilla simple para crear un robot MetaTrader universal que se pueda usar en varios gráficos, pero adjunto a uno solo, sin necesidad de configurar cada ejemplar del robot en cada gráfico individual.
En el artículo anterior, analizamos los modelos relacionales que utilizan mecanismos de atención en su arquitectura. Una de las características de dichos modelos es su mayor uso de recursos informáticos. Este artículo propondrá uno de los posibles mecanismos para reducir el número de operaciones computacionales dentro del bloque Self-Attention o de auto-atención, lo cual aumentará el rendimiento del modelo en su conjunto.
La teoría de categorías es una rama de las matemáticas diversa y en expansión, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo describir algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.
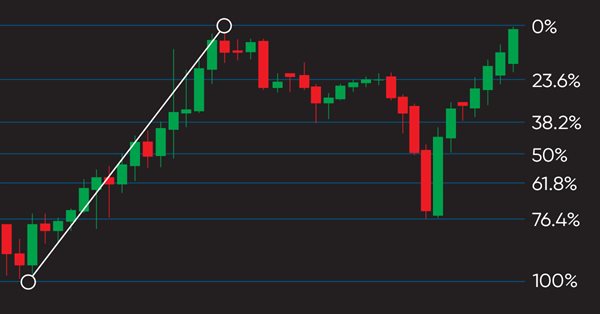
El presente artículo supone la continuación de la serie dedicada a la construcción de sistemas comerciales basados en los indicadores más populares. La próxima herramienta técnica que analizaremos será el indicador de Fibonacci. Hoy veremos cómo escribir un programa basado en las señales de este indicador.
Probablemente mucha gente esté cansada de intentar predecir el mercado bursátil constantemente. ¿No le gustaría tener una bola de cristal que le ayudara a tomar decisiones de inversión más informadas? Las redes neuronales de autoaprendizaje podrían ser su solución. En este artículo, analizaremos si estos potentes algoritmos pueden ayudarnos a "subirnos a la ola" y ser más astutos que el mercado bursátil. Mediante el análisis de grandes cantidades de datos y la identificación de patrones, las redes neuronales de autoaprendizaje pueden hacer predicciones que a menudo resultan más precisas que las realizadas por los tráders. Veamos si estas tecnologías de vanguardia pueden usarse para tomar decisiones de inversión inteligentes y ganar más.