En este artículo, intentaremos usar nuestro modelo logístico para predecir una caída del mercado de valores según las principales acciones de la economía estadounidense: NETFLIX y APPLE. Analizaremos estas acciones, y también usaremos la información sobre las anteriores caídas del mercado en 2019 y 2020. Veamos cómo funcionará nuestro modelo en las poco favorables condiciones actuales.
En esta ocasión, vamos a crear modelos usando matrices: estas ofrecen una gran flexibilidad y permiten crear modelos potentes que pueden manejar no solo cinco variables independientes, sino muchas otras, tantas como los límites computacionales de nuestro ordenador nos permitan. El presente artículo será muy interesante, eso seguro.
Aquí tenemos un nuevo artículo de nuestra serie destinada a la creación de sistemas comerciales basados en indicadores técnicos populares. Esta vez está dedicado al índice de flujo de dinero (IMF). Estudiaremos este indicador con todo detalle y desarrollaremos sistemas comerciales MQL5 simples para su ejecución en MetaTrader 5.
En este breve curso en vídeo, aprenderá cómo descargar, instalar y configurar MetaTrader 5 para el comercio automatizado. También aprenderá cómo configurar el gráfico y las opciones del comercio automatizado. Asimismo, podrá realizar su primera prueba con la historia y aprenderá a importar un asesor que pueda comerciar por sí mismo las 24 horas del día, los 7 días de la semana sin que usted tenga que sentarse frente a una pantalla.
En este nuevo artículo de la serie sobre la creación de sistemas comerciales basados en indicadores técnicos populares, analizaremos el indicador de Acumulación/Distribución (A/D). También desarrollaremos un sistema comercial para la plataforma MetaTrader 5 utilizando algunas estrategias simples.
En el artículo anterior, creamos una clase para la clusterización de datos. En este artículo, queremos compartir con el lector diferentes opciones de uso de los resultados obtenidos para resolver problemas prácticos en el trading.
En este nuevo artículo de nuestra serie para principiantes en programación MQL5, aprenderemos a construir sistemas de trading usando los indicadores más populares. En esta ocasión, analizaremos el indicador On Balance Volume (OBV), aprenderemos a utilizarlo y también a crear un sistema comercial basado en él.
Continuamos analizando el método de clusterización. En este artículo, crearemos una nueva clase CKmeans para implementar uno de los métodos de clusterización de k-medias más extendidos. Según los resultados de la prueba, el modelo ha podido identificar alrededor de 500 patrones.
Esta es la continuación de una serie de artículos en los que aprendemos cómo crear sistemas comerciales usando los indicadores más populares. En el presente artículo, analizaremos el indicador Parabolic SAR. También desarrollaremos un sistema comercial para la plataforma MetaTrader 5 usando algunas estrategias simples.
En este artículo, analizaremos una nueva herramienta técnica que puede usarse en el trading. Esta es una continuación de nuestra serie para aprender a diseñar sistemas de trading sencillos. En esta ocasión, trabajaremos con otro popular indicador técnico, el rango medio verdadero (Average True Range, ATR).
En el artículo anterior, mencionamos la importancia de detectar las tendencias, es decir, de determinar la dirección del movimiento del precio. En este artículo, hablaremos sobre otro concepto importante en el trading, que también existe en forma de indicador: el impulso del precio o el indicador Momentum. Asimismo, desarrollaremos nuestro propio sistema comercial basado en este indicador.
Finalmente el sistema visual funcionará... aún no del todo. Aquí terminaremos de hacer los cambios básicos, y no serán pocos, serán muchos, y todos ellos necesarios, y todo el trabajo será bastante interesante.
Continuemos con la implantación del nuevo sistema de órdenes. La creación de este sistema es algo que exige un buen dominio de MQL5, así como entender cómo funciona en realidad la plataforma MetaTrader 5 y qué recursos nos proporciona.
La mayoría de los estudiantes de mis cursos consideraban que el lenguaje MQL5 era difícil de entender. Asimismo, buscaban formas sencillas de automatizar algunos procesos. En este artículo, el lector aprenderá cómo comenzar a trabajar directamente en MQL5 incluso sin conocimientos de programación y habiendo tenido incluso intentos fallidos de dominar este tema en el pasado.
Lo confieso: ha pasado más de un año desde que publiqué el último artículo. En tanto tiempo, me ha sido posible repensar mucho, desarrollar nuevos enfoques. Y en este nuevo artículo, me gustaría alejarme un poco del método anteriormente usado de aprendizaje supervisado, y sugerir una pequeña inmersión en los algoritmos de aprendizaje no supervisado. En particular, vamos a analizar uno de los algoritmos de clusterización, las k-medias.
Aquí vamos a desarrollar un sistema gráfico de órdenes, del tipo «vea lo que está pasando». Cabe decir que no partiremos de cero, sino que modificaremos el sistema existente añadiendo aún más objetos y eventos al gráfico del activo que estamos negociando.
Esta es la primera parte del nuevo sistema de ordenes. Desde que este EA comenzó a tener su desarrollo documentado en artículos, ha sufrido varios cambios y mejoras, si bien ha mantenido el mismo modelo de sistema de órdenes en el gráfico.
En este artículo continuaremos a aprender cómo obtener datos de la web para utilizarlos en un EA. Así que pongamos manos a la obra, o más bien a empezar a codificar un sistema alternativo.
Saber cómo introducir los datos de la Web en un EA no es tan obvio, o mejor dicho, no es tan simple que puede hacerse sin conocer y entender realmente todas las características que están presentes en MetaTrader 5.
Hoy añadiremos varios recursos a nuestro EA. Este artículo les resultará bastante interesante y puede orientarlos hacia nuevas ideas y métodos para presentar la información y, al mismo tiempo, corregir pequeños fallos en sus proyectos.
En este artículo, continuaremos nuestra serie sobre el diseño de sistemas de trading usando los indicadores más populares, y hablaremos del indicador del índice direccional medio (ADX). Analizaremos este indicador con detalle para entenderlo bien y utilizarlo con una sencilla estrategia. Y es que, profundizando en un indicador, podremos usarlo mejor en el trading.
En este artículo, continuaremos con nuestra serie dedicada al diseño de sistemas comerciales. En esta ocasión, aprenderemos a diseñar un sistema de trading usando uno de los indicadores más útiles y populares, el indicador Oscilador Estocástico, que servirá para construir un nuevo bloque en nuestro conocimiento de los fundamentos.
En este artículo, hablaremos de una nueva herramienta de nuestra serie, y aprenderemos a diseñar un sistema comercial basado en uno de los indicadores técnicos más populares: la convergencia/divergencia de medias móviles (MACD).
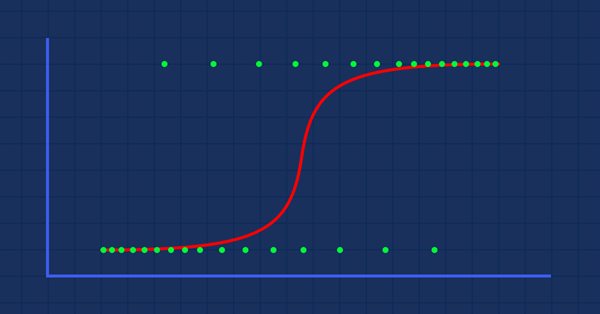
La clasificación de los datos es un punto crucial para los tráders algorítmicos y los programadores. En este artículo, nos centraremos en uno de los algoritmos logísticos de clasificación que podría ayudarnos a identificar los síes o los noes, las subidas y bajadas, las compras y las ventas.
En este nuevo artículo de nuestra serie sobre el diseño de sistemas comerciales, hablaremos del Índice del Canal de Mercaderías (CCI), estudiaremos sus entresijos y crearemos juntos un sistema comercial basado en este indicador.
En este artículo, hablaremos sobre otro indicador popular y de uso común: RSI. Asimismo, aprenderemos a desarrollar un sistema comercial basado en las lecturas de este indicador.
Creación de un sistema de órdenes cruzadas. Hay una clase de activos que les hace la vida muy difícil a los comerciantes, estos son los activos de contratos futuros, y ¿por qué le hacen la vida difícil al comerciante?
¿Cómo acceder a los indicadores personalizados directamente en el EA? A un EA comercial solo se le sacará partido realmente si se puede usar indicadores personalizados en él, de lo contrario, será solo un conjunto de códigos e instrucciones.
Colocación del Chart Trade en una ventana flotante. En el artículo anterior creamos el sistema base para utilizar templates dentro de una ventana flotante.
En este artículo, compartiré con ustedes uno de los métodos para comeciar con bandas. Esta vez analizaremos el indicador Envelopes y veremos lo fácil que resulta crear algunas estrategias basadas en él.
Este es uno de los indicadores más poderosos que existen. Para aquellos que operan y tratan de tener un cierto grado de asertividad, no pueden dejar de tener este indicador en su gráfico, aunque es más utilizado por aquellos que operan observando el flujo («tape reading») también puede ser utilizado por aquellos que utilizan sólo la acción del precio.
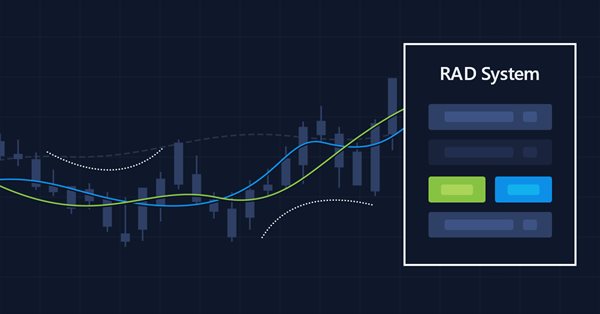
En el artículo anterior mostré cómo crear un Chart Trade utilizando los objetos de MetaTrader 5, por medio de la conversión de la plataforma en un sistema RAD. El sistema funciona muy bien, y creo que muchos han pensado en crear una librería para tener cada vez más funcionalidades en el sistema propuesto, y así lograr desarrollar un EA que sea más intuitivo a la vez que tenga una interfaz más agradable y sencilla de utilizar.
A pesar de no saber programar, muchas personas son bastante creativas y tienen grandes ideas, pero la falta de conocimientos o de entendimiento sobre la programación les impide hacer algunas cosas. Aprenda a crear un Chart Trade, pero utilizando la propia plataforma MT5, como si fuera un IDE.
En artículos anteriores, expliqué cómo crear un indicador con múltiples subventanas, lo que se vuelve interesante cuando usamos un indicador personalizado. Aquí entenderemos cómo añadir múltiples ventanas en un EA.
En este artículo, ofrecemos un análisis de los datos de divisas para entender mejor por qué los asesores expertos pueden tener un buen rendimiento en algunos intervalos y un mal rendimiento en otros.
En este artículo, hablaremos sobre las Bandas de Bollinger, uno de los indicadores más populares en el mundo del trading. Asimismo, trataremos el análisis técnico y veremos cómo diseñar un sistema de trading algorítmico basado en el indicador de las Bandas de Bollinger.
En este artículo, mostraremos los fundamentos de MQL que permitirán a los tráders principiantes diseñar su propio sistema de trading algorítmico (Asesor Experto) mediante el diseño de un sistema de trading algorítmico simple después de mencionar algunas ideas básicas de MQL5
La matriz y el vector de tipos de datos especiales nos permiten escribir un código próximo a la notación matemática. Esto elimina la necesidad de crear ciclos anidados y recordar la indexación correcta de las matrices que participan en los cálculos, aumentando la fiabilidad y la velocidad del desarrollo de programas complejos.