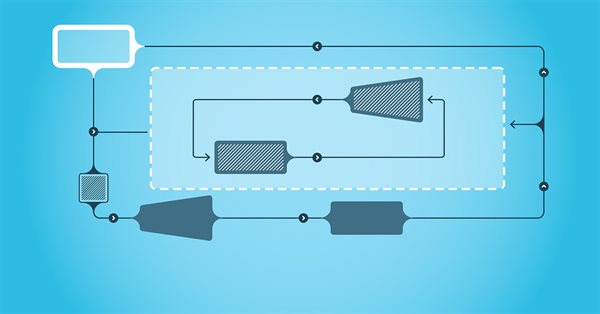
Neste artigo, por EA multimoeda, entendemos um robô investidor ou um robô de negociação que pode negociar (abrir/fechar ordens, gerenciar ordens como trailing-stop-loss e trailing profit) mais de um par de moedas em um gráfico. Desta vez, usaremos apenas um indicador, o Parabolic SAR ou iSAR, em vários timeframes, começando com PERIOD_M15 e terminando com PERIOD_D1.
Neste artigo de referência, vamos dar uma olhada nos indicadores padrão da categoria Indicadores de tendência. Criaremos modelos prontos a serem usados em Expert Advisors, modelos esses que incluirão: declaração e configuração de parâmetros, inicialização/desinicialização de indicadores e recuperação de dados/sinais a partir de buffers de indicador em EAs.
Neste artigo, examinaremos os indicadores padrão das categorias Volumes e Bill Williams. Criaremos modelos prontos a serem usados em Expert Advisors, modelos esses que incluirão: declaração e configuração de parâmetros, inicialização/desinicialização de indicadores e recuperação de dados/sinais a partir de buffers de indicador em EAs.
Apresentamos um algoritmo relativamente novo, o Stochastic Marginal Actor-Critic (SMAC), que permite a construção de políticas de variáveis latentes no contexto da maximização da entropia.
Ao criar um sistema de negociação, há sempre uma tarefa que deve ser resolvida com eficiência. Essa tarefa é a colocação de ordens ou seu processamento automático pelo sistema de negociação. Neste artigo, apresentamos a criação de um sistema de negociação do ponto de vista da colocação eficiente de ordens.
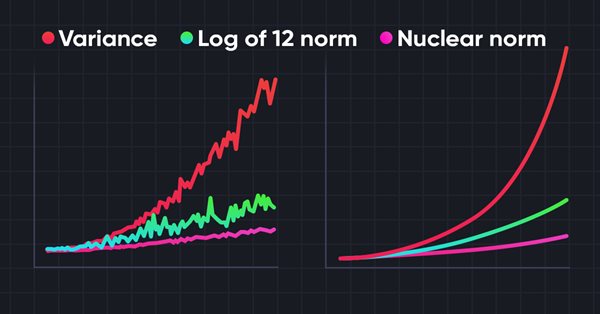
A pesquisa do ambiente em tarefas de aprendizado por reforço é um problema atual. Anteriormente, já examinamos algumas abordagens. E hoje, eu proponho que nos familiarizemos com mais um método, baseado na maximização da norma nuclear. Ele permite que os agentes destaquem estados do ambiente com alto grau de novidade e diversidade.
O aprendizado contrastivo é um método de aprendizado de representação sem supervisão. Seu objetivo é ensinar o modelo a identificar semelhanças e diferenças nos conjuntos de dados. Neste artigo, discutiremos o uso de abordagens de aprendizado contrastivo para explorar diferentes habilidades do Ator.
Neste artigo, mostrarei a primeira parte das melhorias que me permitiram não apenas fechar todo o ciclo de automação para negociação no MetaTrader 4 e 5, mas também fazer algo muito mais interessante. A partir de agora, esta solução me permite automatizar completamente tanto o processo de criação de EAs quanto o processo de otimização, além de minimizar o esforço necessário para encontrar configurações de negociação eficazes.
A cada vez que consideramos métodos de aprendizado por reforço, nos deparamos com a questão da exploração eficiente do ambiente. A solução deste problema frequentemente leva à complexificação do algoritmo e ao treinamento de modelos adicionais. Neste artigo, vamos considerar uma abordagem alternativa para resolver esse problema.
Neste artigo, vamos brevemente revisar a biblioteca de análise numérica ALGLIB 3.19, suas aplicações e novos algoritmos que aumentam a eficácia da análise de dados financeiros.
Neste artigo, por EA multimoeda, entendemos um Expert Advisor ou robô de negociação capaz de negociar (abrir/fechar ordens, gerenciar ordens, etc.) mais de um par de símbolos a partir de um único gráfico.
Já falamos várias vezes sobre a importância de escolher corretamente a função de recompensa que usamos para incentivar o comportamento desejável do Agente, adicionando recompensas ou penalidades por ações específicas. Mas a questão de como o Agente interpreta nossos sinais permanece em aberto. Neste artigo, discutiremos a decomposição da recompensa em termos de transmissão de sinais individuais ao Agente a ser treinado.
À medida que a política do Ator se afasta cada vez mais dos exemplos armazenados no buffer de reprodução de experiências, a eficácia do treinamento do modelo, baseado nesse buffer, diminui. Neste artigo, examinamos um algoritmo que aumenta a eficácia do uso de amostras em algoritmos de aprendizado por reforço.
Nos últimos dois artigos, discutimos o algoritmo Soft Actor-Critic, que incorpora regularização de entropia na função de recompensa. Essa abordagem permite equilibrar a exploração do ambiente e a exploração do modelo, mas é aplicável apenas a modelos estocásticos. Neste artigo, exploraremos uma abordagem alternativa que é aplicável tanto a modelos estocásticos quanto determinísticos.
No artigo anterior, implementamos o algoritmo Soft Actor-Critic, mas não conseguimos treinar um modelo lucrativo. Neste artigo, vamos realizar a otimização do modelo previamente criado para obter os resultados desejados a nível de seu funcionamento.
Estratégias de negociação tradicionais. Neste artigo, vamos explorar uma estratégia de acompanhamento de tendências. Essa abordagem é totalmente baseada em análise técnica e faz uso de vários indicadores e ferramentas para gerar sinais e identificar metas de negociação. Os elementos-chave dessa estratégia incluem um oscilador estocástico de 14 períodos, um oscilador estocástico de cinco períodos, uma média móvel de 200 períodos e uma projeção de Fibonacci (para determinar as metas de negociação).
Continuamos nossa exploração dos algoritmos de aprendizado por reforço na resolução de problemas em espaços de ação contínua. Neste artigo, apresento o algoritmo Soft Actor-Critic (SAC). A principal vantagem do SAC está em sua capacidade de encontrar políticas ótimas que não apenas maximizam a recompensa esperada, mas também têm a máxima entropia (diversidade) de ações.
Combinar estratégias pode aumentar a eficácia da negociação. Podemos combinar indicadores e padrões para obter confirmações adicionais. As médias móveis nos ajudam a confirmar a tendência e a segui-la. Este é o indicador técnico mais conhecido, o que se explica pela sua simplicidade e eficácia comprovada na análise.
No artigo anterior, nós exploramos o método DDPG, projetado para treinar modelos em espaços de ação contínua. No entanto, como outros métodos de aprendizado Q, ele está sujeito ao problema da sobreavaliação dos valores da função Q. Esse problema geralmente leva eventualmente ao treinamento de um agente com uma estratégia não otimizada. Neste artigo, examinaremos algumas abordagens para superar o problema mencionado.
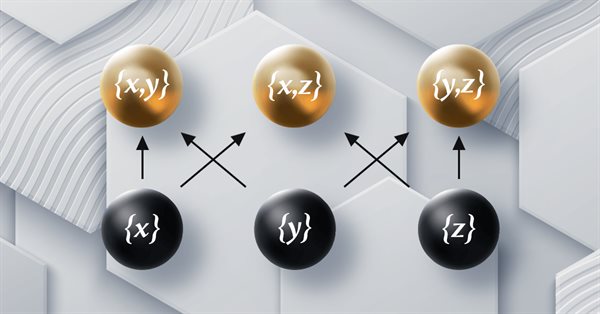
Este artigo faz parte de uma série sobre a implementação de grafos usando a teoria das categorias no MQL5 e é dedicado à teoria da ordem (Order Theory). Consideraremos dois tipos básicos de ordenação e exploraremos como os conceitos de relação de ordem podem auxiliar os conjuntos monoidais na tomada de decisões de negociação.
Esse artigo é uma continuação da série sobre como implementar a teoria das categorias no MQL5. Aqui consideramos como a teoria dos grafos pode ser integrada com monoides e outras estruturas de dados ao desenvolver uma estratégia para fechar um sistema de negociação.
Neste artigo, estamos ampliando o escopo das tarefas do nosso agente. No processo de treinamento, incluiremos alguns aspectos de gerenciamento de dinheiro e risco, que são partes integrantes de qualquer estratégia de negociação.
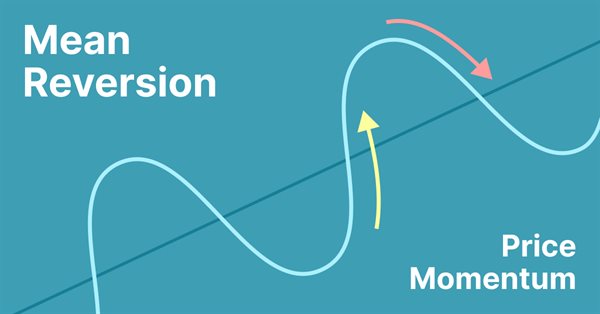
A reversão à média é um tipo de negociação contra-tendência em que o trader espera que o preço retorne a algum tipo de equilíbrio, geralmente medido por uma média ou outra estatística de tendência central.
Convido você a conhecer mais uma abordagem no campo do aprendizado por reforço. É chamada de aprendizado por reforço condicionado a metas, conhecida pela sigla GCRL (Goal-conditioned reinforcement learning). Nessa abordagem, o agente é treinado para alcançar diferentes metas em cenários específicos.
Aprender habilidades úteis sem uma função de recompensa explícita é um dos principais desafios do aprendizado por reforço hierárquico. Anteriormente, já nos familiarizamos com dois algoritmos para resolver esse problema. Mas a questão da completa exploração do ambiente ainda está em aberto. Neste artigo, é apresentada uma abordagem diferente para o treinamento de habilidades, cujo uso depende diretamente do estado atual do sistema.
No artigo anterior, apresentamos o método DIAYN, que oferece um algoritmo para aprender uma variedade de habilidades. O uso das habilidades adquiridas pode ser usado para diversas tarefas. Mas essas habilidades podem ser bastante imprevisíveis, o que pode dificultar seu uso. Neste artigo, veremos um algoritmo para ensinar habilidades previsíveis.
Este artigo descreve a implementação de um modelo de regressão de árvores de decisão para prever preços de ativos financeiros. Foram realizadas etapas de preparação dos dados, treinamento e avaliação do modelo, com ajustes e otimizações. No entanto, é importante destacar que o modelo é apenas um estudo e não deve ser usado em negociações reais.
Esse artigo é uma continuação da série sobre como implementar a teoria das categorias em MQL5. Nele, consideramos os grupos monoides como um meio de normalizar os conjuntos monoides e permitir uma comparação mais precisa em um espectro mais amplo de conjuntos monoides e tipos de dados.
O problema com o aprendizado por reforço é a necessidade de definir uma função de recompensa, que pode ser complexa ou difícil de formular, porém abordagens baseadas no tipo de ação e na exploração do ambiente que permitem que as habilidades sejam aprendidas sem uma função de recompensa explícita estão sendo exploradas para resolver esse problema.
A procrastinação de modelos no contexto do aprendizado por reforço pode ser causada por vários motivos, e a solução desse problema requer medidas apropriadas. Este artigo discute algumas das possíveis causas da procrastinação do modelo e métodos para superá-las.
Este artigo descreve modelos hierárquicos de aprendizado que propõem uma abordagem eficaz para resolver tarefas complexas de aprendizado de máquina. Os modelos hierárquicos consistem em vários níveis, cada um responsável por aspectos diferentes da tarefa.
Neste artigo, discutiremos a aplicação do algoritmo Go-Explore ao longo de um período de treinamento prolongado, uma vez que uma estratégia de seleção aleatória de ações pode não levar a uma passagem lucrativa à medida que o tempo de treinamento aumenta.
Continuamos com o tema da exploração do ambiente no aprendizado por reforço. Neste artigo, abordaremos mais um algoritmo, o Go-Explore, que permite explorar eficazmente o ambiente durante a fase de treinamento do modelo.
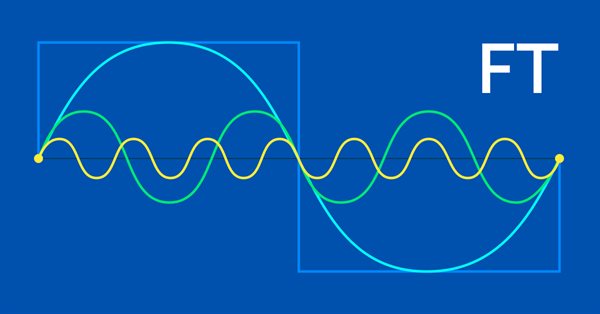
A transformada de Fourier é um método de decompor uma onda de pontos de dados em possíveis partes constituintes que foi introduzida por Joseph Fourier. Esse recurso pode ser útil para os traders, e é isso que abordaremos neste artigo.
Veja um exemplo do uso do perceptron como um meio autossuficiente de previsão de preços. Esse artigo aborda conceitos gerais, apresenta um Expert Advisor simples e pronto para uso e os resultados de sua otimização.
A teoria das categorias é um ramo diversificado e em expansão da matemática que só recentemente começou a ser abordado na comunidade MQL5. Esta série de artigos tem como objetivo analisar alguns de seus conceitos para criar uma biblioteca aberta e utilizar ainda mais essa maravilhosa seção na criação de estratégias de negociação.
Uso da abordagem de negociação em grade com ordens pendentes de stop em um Expert Advisor usando a linguagem de estratégias de negociação MQL5 para o MetaTrader 5 na Bolsa de Valores de Moscou (MOEX). Ao negociar no mercado, uma das estratégias mais simples é uma grade de ordens projetada para "capturar" o preço de mercado.
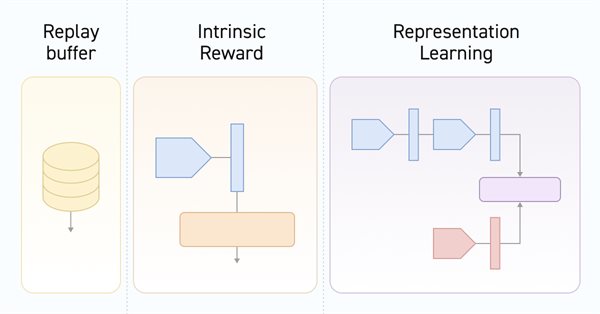
Um dos principais desafios do aprendizado por reforço é a exploração do ambiente. Anteriormente, já nos iniciamos no método de exploração baseado na curiosidade interna. E hoje proponho considerar outro algoritmo, o de exploração por desacordo.