Предлагаем погрузиться в захватывающий мир LightGTS — лёгкого, но мощного фреймворка для прогноза временных рядов, где адаптивная свёртка и RoPE‑кодирование сочетаются с инновационным методами внимания. В нашей статье вы найдёте детальное описание всех компонентов — от создания патчей до сложной смеси экспертов в декодере, готовых к интеграции в MQL5‑проекты. Откройте для себя, как LightGTS выводит автоматическую торговлю на новый уровень!
Торговая стратегия захвата ликвидности является ключевым компонентом Концепции умных денег (Smart Money Concepts (SMC), которая направлена на выявление и использование действий институциональных игроков на рынке. Она предполагает нацеливание на области с высокой ликвидностью, такие как зоны поддержки или сопротивления, где крупные ордера могут спровоцировать движение цены до того, как рынок возобновит свой тренд. В настоящей статье подробно объясняется концепция захвата ликвидности и описывается процесс разработки советника по торговой стратегии захвата ликвидности на MQL5.
В настоящей статье мы представим основанный на объемах индикатор денежного потока Чайкина (Chaikin Money Flow, CMF) после того, как узнаем, как его можно построить, рассчитать и использовать. Разберемся как создать пользовательский индикатор. Проанализируем несколько простых стратегий, которые можно использовать и протестируем их, чтобы понять, какая стратегия лучше.
Предлагаем вам отправиться в захватывающее путешествие по миру адаптивного анализа финансовых временных рядов и узнать, как превратить сложный спектральный разбор и гибкую свёртку в реальные торговые сигналы. Вы увидите, как LightGTS слушает ритм рынка, подстраиваясь под его изменения шагом переменного окна, и как OpenCL-ускорение позволяет превратить вычисления в кратчайший путь к прибыльным решениям.
Аллигатор, детище Билла Вильямса, представляет собой универсальный индикатор определения тренда, который дает четкие сигналы и часто сочетается с другими индикаторами. Классы Мастера MQL5 позволяют нам тестировать различные сигналы на основе паттернов, что позволяет нам рассмотреть и этот индикатор.
Предлагаем познакомиться с инновационной техникой адаптивного патчинга — способа гибко сегментировать временные ряды с учётом их внутренней периодичности. А также с техникой эффективного кодирования, позволяющего сохранять важные семантические характеристики при работе с данными разного масштаба. Эти методы открывают новые возможности для точной обработки сложных многомасштабных данных, характерных для финансовых рынков, и существенно повышают стабильность и обоснованность прогнозов.
В данной статье мы исследуем систему Profitunity авторства Билла Вильямса, подробно разобрав ее ключевые составляющие и уникальный подход к торговле в хаотичных условиях рынка. Мы продемонстрируем читателям реализацию системы на языке программирования MQL5, делая акцент на автоматизации ключевых индикаторов и сигналов для входа/выхода. Наконец, мы протестируем и оптимизируем стратегию, детально анализируя ее эффективность в различных рыночных сценариях.
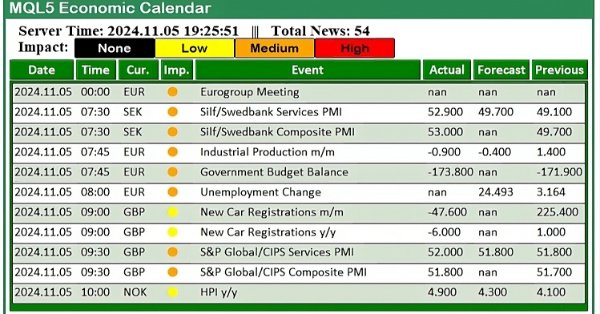
В этой статье мы создадим практичную новостную панель с использованием экономического календаря MQL5 для улучшения нашей торговой стратегии. Начнем с проектирования макета, уделив особое внимание ключевым элементам, таким как названия событий, важность и время, а затем перейдем к настройке в MQL5. Наконец, мы внедрим систему сортировки для отображения только самых актуальных новостей, предоставляя трейдерам быстрый доступ к важным экономическим событиям.
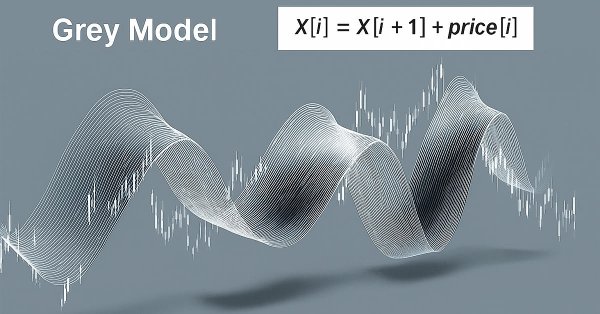
Данная статья посвящена изучению grey-модели — перспективного инструмента, способного расширить возможности трейдера. Мы рассмотрим некоторые варианты применения этой модели для технического анализа и построения торговых стратегий.
На форуме MQL5 есть множество сообщений с просьбами помочь рассчитать угол наклона изменения цены. В этой статье мы рассмотрим один из способов расчета наклона изменения цены. Этот способ применим на любом рынке. Кроме того, мы определим, стоит ли разработка этой новой функции дополнительных усилий и времени. Выясним, может ли угол наклона цены улучшить точность нашей AI-модели при прогнозировании пары USDZAR на минутном таймфрейме.
В этой заключительной части нашей серии библиотеки Connexus мы рассмотрели реализацию паттерна Наблюдатель, а также основные рефакторинги в путях к файлам и именах методов. В этой серии представлена вся разработка Connexus, предназначенная для упрощения HTTP-взаимодействия в сложных приложениях.
Эта статья увлекательно покажет, как SwiGLU‑эмбеддинг раскрывает скрытые паттерны рынка, а разреженная смесь экспертов внутри Decoder‑Only Transformer делает прогнозы точнее при разумных вычислительных затратах. Мы подробно разбираем интеграцию Time‑MoE в MQL5 и OpenCL, шаг за шагом описываем настройку и обучение модели.
Ichimuko Kinko Hyo — известный японский индикатор, представляющий собой систему определения тренда. Как и в предыдущих статьях, мы рассмотрим этот индикатор с использованием паттернов и поделимся стратегиями и отчетами о тестировании, применив классы библиотеки Мастера MQL5.
Предлагаем познакомиться с практической реализацией блока разреженной смеси экспертов для временных рядов в вычислительной среде OpenCL. В статье шаг за шагом разбирается работа маскированной многооконной свёртки, а также организация градиентного обучения в условиях множественных информационных потоков.
Предлагаем познакомиться с современным фреймворком Time-MoE, адаптированным под задачи прогнозирования временных рядов. В статье мы пошагово реализуем ключевые компоненты архитектуры, сопровождая их объяснениями и практическими примерами. Такой подход позволит вам не только понять принципы работы модели, но и применить их в реальных торговых задачах.
Python-пакет MetaTrader 5 предлагает простой способ создания торговых приложений для платформы MetaTrader 5 на языке Python. Будучи мощным и полезным инструментом данный модуль не так прост как язык программирования MQL5, когда дело касается разработки решений для алгоритмической торговли. В данной статье мы создадим классы для торговли, аналогичные предлагаемым в языке MQL5, чтобы создать схожий синтаксис и сделать разработку торговых роботов на Python такой же простой как и на MQL5.
Статья посвящена практическому построению модели TimeFound для прогнозирования временных рядов. Рассматриваются ключевые этапы реализации основных подходов фреймворка средствами MQL5.
Монте-Карло — четвертый алгоритм обучения с подкреплением, который мы рассматриваем в контексте его реализации в советниках, собранных с помощью Мастера. Хотя алгоритм основан на случайной выборке, он предоставляет обширные возможности моделирования.
В этой шестой статье из серии о библиотеке Connexus мы сосредоточимся на полном HTTP-запросе, рассмотрев каждый компонент, из которого состоит запрос. Мы создадим класс, представляющий запрос в целом, который поможет нам объединить ранее созданные классы.
В этой статье мы шаг за шагом собираем ядро интеллектуальной модели TimeFound, адаптированной под реальные задачи прогнозирования временных рядов. Если вас интересует практическая реализация нейросетевых патчинг-алгоритмов в MQL5 — вы точно по адресу.
Количество стратегий, которые можно интегрировать в виде советника, практически безгранично. Однако каждая дополнительная стратегия увеличивает сложность алгоритма. Благодаря использованию нескольких стратегий советник может лучше адаптироваться к изменяющимся рыночным условиям, что потенциально повышает его прибыльность. Сегодня мы рассмотрим, как реализовать в MQL5 одну из выдающихся стратегий, разработанных Ричардом Дончианом, продолжая при этом совершенствовать функциональность нашего советника Trend Constraint.
В этой статье мы рассмотрим, как использовать экономический календарь MQL5 для торговли, сначала разобравшись с его основными функциями. Затем мы реализуем ключевые функции экономического календаря в MQL5 для извлечения необходимых новостей для принятия торговых решений. Наконец, мы посмотрим, как использовать эту информацию для эффективного совершенствования торговых стратегий.
При возникновении необходимости вывести текстовую информацию на график мы можем воспользоваться функцией Comment(). Но её возможности достаточно сильно ограничены. Поэтому, в рамках этой статьи, мы создадим собственный компонент — диалоговое окно на весь экран, способное выводить многострочный текст с гибкими настройками шрифта и поддержкой прокрутки.
В настоящей статье мы разберемся с методами HTTP и кодами состояния, двумя очень важными элементами взаимодействия между клиентом и сервером в Интернете. Понимание того, что каждый метод действительно дает возможность более точно делать запросы, информируя сервер о том, какое действие надо выполнить, и делая его более эффективным.
Статья описывает вариант эмуляции опционов через базовый актив, реализованный на языке программирования MQL5. Сравниваются преимущества и недостатки выбранного подхода с реальными биржевыми опционами на примере срочного рынка ФОРТС московской биржи MOEX и криптобиржи Bybit.
Осциллятор ATR — очень популярный индикатор, используемый в качестве индикатора волатильности, особенно на валютных рынках, где данные об объемах скудны. Как и в случае с предыдущими индикаторами, мы рассмотрим паттерны и поделимся стратегиями и отчетами о тестировании.
В настоящей статье мы создаём советника на MQL5 на основе стратегии Прорыва дневного диапазона (Daily Range Breakout). Мы рассмотрим ключевые концепции стратегии, разработаем схему советника и реализуем логику прорыва на MQL5. В конце мы изучаем методы бэк-тестирования и оптимизации советника, чтобы максимально повысить его эффективность.
Фреймворк Mantis превращает сложные временные ряды в информативные токены и служит надёжным фундаментом для интеллектуального торгового Агента, готового работать в реальном времени.
Mantis — универсальный инструмент для глубокого анализа временных рядов, гибко масштабируемый под любые финансовые сценарии. Узнайте, как сочетание патчинга, локальных свёрток и кросс-внимания позволяет получить высокоточную интерпретацию рыночных паттернов.
В настоящей статье мы рассмотрели концепцию тела в HTTP-запросах, которое необходимо для отправки таких данных, как JSON и обычный текст. Мы обсудили и объяснили, как правильно его использовать с соответствующими заголовками. Мы также ввели класс ChttpBody, входящий в библиотеку Connexus, который упростит работу с телом запросов.
В статье рассмотрено повышение безопасности панели торгового администратора, которая в настоящее время находится в разработке. Мы рассмотрим, как внедрить MQL5 в новую стратегию безопасности, интегрировав API Telegram для двухфакторной аутентификации (2FA). Статья предоставит ценную информацию о применении MQL5 для усиления мер безопасности. Кроме того, мы рассмотрим функцию MathRand, сосредоточившись на ее функциональности и на том, как ее можно эффективно использовать в нашей системе безопасности.
Познакомьтесь с Mantis — лёгкой фундаментальной моделью для классификации временных рядов на базе Transformer с контрастным предварительным обучением и гибридным вниманием, обеспечивающими рекордную точность и масштабируемость.
В этой статье мы преобразуем нашу статическую панель мониторинга MQL5 в интерактивный инструмент, добавив отзывчивость кнопок. Мы рассмотрим, как автоматизировать функционал компонентов графического интерфейса, гарантируя, что они будут правильно реагировать на нажатия пользователя. К концу статьи мы создадим динамический интерфейс, который повышает вовлеченность пользователей и удобство торговли.
SARSA (State-Action-Reward-State-Action, состояние-действие-вознаграждение-состояние-действие) — еще один алгоритм, который можно использовать при реализации обучения с подкреплением. Рассмотрим, как можно реализовать этот алгоритм в качестве независимой модели (а не просто механизма обучения) в советниках, собранных в Мастере, аналогично тому, как мы это делали в случаях с Q-обучением и DQN.
В этой статье будут рассмотрены методы улучшения работы советника в тестере стратегий, будет написан код для разделения времени новостных событий на почасовые категории. Доступ к этим новостным событиям будет осуществляться в течение указанного для них часа. Это гарантирует, что советник может эффективно управлять сделками на основе событий как в условиях высокой, так и низкой волатильности.
SMC (Order Block) — это ключевые области, где институциональные трейдеры совершают значительные покупки или продажи. После значительного движения цены уровни Фибоначчи помогают определить потенциальный откат от недавнего максимума колебания (swing high) к минимуму колебания (swing low) для определения оптимальной точки входа в сделку.
В настоящей статье мы создаем советника (EA) на MQL5 на основе стратегии PIRANHA, использующего Полосы Боллинджера для повышения эффективности торговли. Мы обсуждаем ключевые принципы стратегии, реализацию кода, а также методы тестирования и оптимизации. Эти знания позволят эффективно использовать советник в ваших торговых сценариях
Эта статья позволит вам увидеть, как Mamba4Cast превращает теорию в рабочий торговый алгоритм и подготовить почву для собственных экспериментов. Не упустите возможность получить полный спектр знаний и вдохновения для развития собственной стратегии.
Вы узнаете, как разработать и внедрить комплексную библиотеку отложенных EX5-ордеров в ваш код или MQL5-проекты. Мы рассмотрим, как импортировать и реализовать такую библиотеку в составе торговой панели или графического пользовательского интерфейса (GUI). Панель ордеров советника позволит пользователям открывать, отслеживать и удалять отложенные ордера по магическому числу непосредственно из графического интерфейса в окне графика.
Продолжаем разработку библиотеки Connexus. В этой главе мы исследуем концепцию заголовков в протоколе HTTP, объясняя, что это такое, для чего они предназначены и как их использовать в запросах. Мы рассмотрим основные заголовки, используемые при взаимодействии с API, а также покажем практические примеры того, как настроить их в библиотеке.