Últimamente, he recibido comentarios de varios compañeros tráders sobre cómo usar el asesor multidivisa que estamos analizando con brókeres que utilizan prefijos y/o sufijos con nombres de símbolos, así como sobre la forma de implementar zonas horarias comerciales o sesiones comerciales en el asesor.
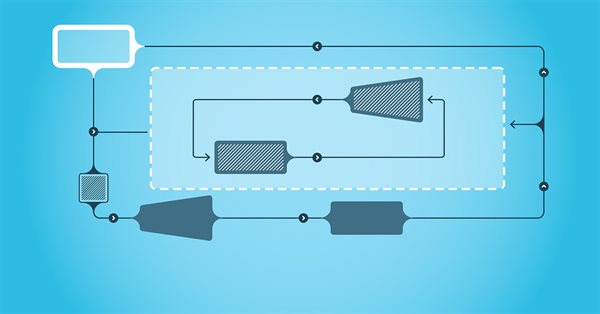
En artículos recientes, hemos visto varios usos del método Decision Transformer, que permite analizar no solo el estado actual, sino también la trayectoria de los estados anteriores y las acciones realizadas en ellos. En este artículo, veremos una variante del uso de este método en modelos jerárquicos.
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.
Ejemplos de transmisión de indicadores a un perceptrón. En el artículo ofreceremos conceptos generales y presentaremos un asesor listo para usar muy simple, así como los resultados de su optimización y sus pruebas forward.
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.
En el artículo anterior nos familiarizamos con el transformador de decisión. Sin embargo, el complejo entorno estocástico del mercado de divisas no nos permitió aprovechar plenamente el potencial del método presentado. Hoy veremos un algoritmo que tiene como objetivo mejorar el rendimiento de los algoritmos en entornos estocásticos.
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, por ejemplo, trailing-stop y trailing-profit, etc.) con más de un par de símbolos de un gráfico. Esta vez usaremos solo un indicador, a saber, Parabolic SAR o iSAR en varios marcos temporales, comenzando desde PERIOD_M15 y terminando con PERIOD_D1.
Continuamos nuestro análisis de los métodos de aprendizaje por refuerzo. Y en el presente artículo, presentaremos un algoritmo ligeramente distinto que considera la política del Agente en un paradigma de construcción de secuencias de acciones.
Este artículo describe la implementación de un modelo de regresión de árboles de decisión para predecir precios de activos financieros. Se realizaron etapas de preparación de datos, entrenamiento y evaluación del modelo, con ajustes y optimizaciones. Sin embargo, es importante destacar que el modelo es solo un estudio y no debe ser usado en operaciones reales.
Hoy le proponemos introducir un algoritmo bastante nuevo, el Stochastic Marginal Actor-Critic (SMAC), que permite la construcción de políticas de variable latente dentro de un marco de maximización de la entropía.
Al crear cualquier sistema comercial, existe una tarea que debemos resolver de forma efectiva. Esta tarea consiste en que el sistema comercial coloque órdenes o las procese de forma automática. El artículo analizará la creación de un sistema comercial desde el punto de vista de la colocación efectiva de órdenes.
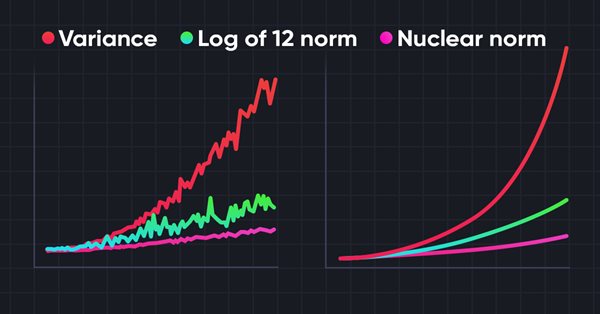
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.
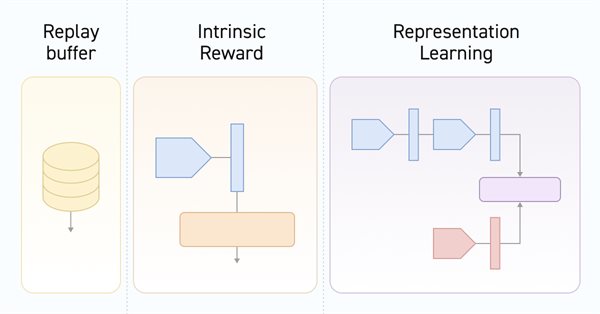
El aprendizaje contrastivo (Contrastive learning) supone un método de aprendizaje de representación no supervisado. Su objetivo consiste en entrenar un modelo para que destaque las similitudes y diferencias entre los conjuntos de datos. En este artículo, hablaremos del uso de enfoques de aprendizaje contrastivo para investigar las distintas habilidades del Actor.
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.
Siempre que analizamos métodos de aprendizaje por refuerzo, nos enfrentamos al problema de explorar eficientemente el entorno. Con frecuencia, la resolución de este problema hace que el algoritmo se complique, llevándonos al entrenamiento de modelos adicionales. En este artículo veremos un enfoque alternativo para resolver el presente problema.
En este artículo, echaremos un vistazo rápido a la biblioteca de análisis numérico ALGLIB 3.19, sus aplicaciones y sus nuevos algoritmos, que pueden mejorar la eficiencia del análisis de datos financieros.
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, etc.) con más de un par de símbolos de un gráfico.
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.
En el artículo anterior, implementamos el algoritmo Soft Actor-Critic (SAC), pero no pudimos entrenar un modelo rentable. En esta ocasión, optimizaremos el modelo creado previamente para obtener los resultados deseados en su rendimiento.
Estrategias comerciales antiguas. Este artículo presenta una estrategia de seguimiento de tendencias. La estrategia es puramente técnica y usa varios indicadores y herramientas para ofrecer señales y niveles objetivo. Los componentes de la estrategia incluyen: Un oscilador estocástico de 14 periodos, un oscilador estocástico de 5 periodos, una media móvil de 200 periodos y una proyección de Fibonacci (para fijar los niveles objetivo).
Continuamos nuestro análisis de los algoritmos de aprendizaje por refuerzo en problemas de espacio continuo de acciones. En este artículo, le propongo introducir el algoritmo Soft Astog-Critic (SAC). La principal ventaja del SAC es su capacidad para encontrar políticas óptimas que no solo maximicen la recompensa esperada, sino que también tengan la máxima entropía (diversidad) de acciones.
Las combinaciones de estrategias pueden mejorar el rendimiento de las transacciones. Podemos combinar indicadores y patrones para obtener confirmaciones adicionales. Las medias móviles nos ayudan a confirmar tendencias y seguirlas. Se trata del indicador técnico más famoso, lo cual se explica por su sencillez y su probada eficacia de análisis.
En el artículo anterior, presentamos el método DDPG, que nos permite entrenar modelos en un espacio de acción continuo. Sin embargo, al igual que otros métodos de aprendizaje Q, el DDPG tiende a sobreestimar los valores de la función Q. Con frecuencia, este problema provoca que entrenemos los agentes con una estrategia subóptima. En el presente artículo, analizaremos algunos enfoques para superar el problema mencionado.
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).
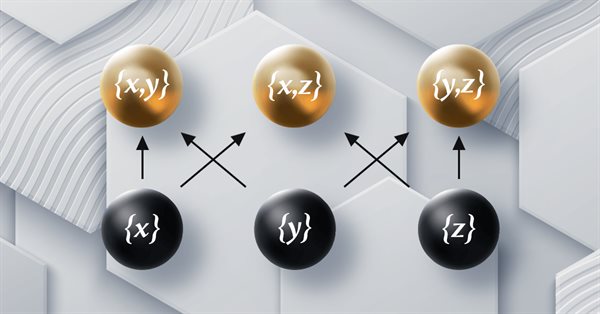
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Aquí veremos cómo podemos integrar la teoría de grafos con los monoides y otras estructuras de datos al desarrollar una estrategia de cierre del sistema comercial.
En este artículo ampliamos el abanico de tareas de nuestro agente. El proceso de entrenamiento incluirá algunos aspectos de la gestión de capital y del riesgo que forma parte integral de cualquier estrategia comercial.
En el artículo de hoy, nos familiarizaremos con otra tendencia en el campo del aprendizaje por refuerzo. Se denomina aprendizaje por refuerzo dirigido a objetivos (Goal-conditioned reinforcement learning, GCRL). En este enfoque, el agente se entrenará para alcanzar diferentes objetivos en determinados escenarios.
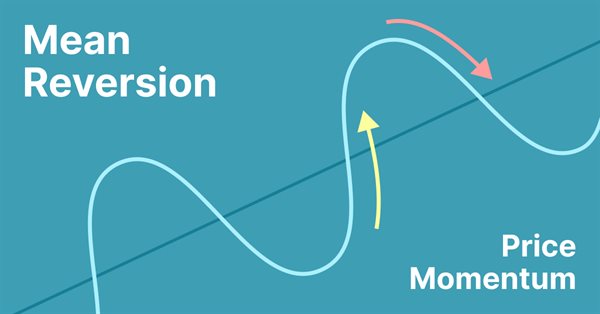
La reversión a la media es una técnica de negociación de contratendencia en la que el tráder espera que el precio regrese a algún tipo de equilibrio, que generalmente se mide usando una media u otro indicador estadístico de la tendencia promediada.
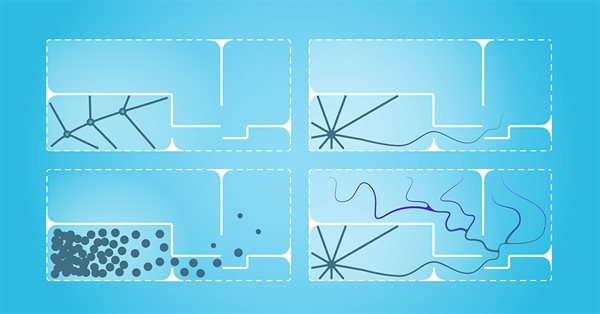
El entrenamiento de habilidades útiles sin una función de recompensa explícita es uno de los principales desafíos del aprendizaje por refuerzo jerárquico. Ya nos hemos familiarizado antes con dos algoritmos para resolver este problema, pero el tema de la exploración del entorno sigue abierto. En este artículo, veremos un enfoque distinto en el entrenamiento de habilidades, cuyo uso dependerá directamente del estado actual del sistema.
En el artículo anterior, nos familiarizamos con el método DIAYN, que ofrece un algoritmo para el aprendizaje de diversas habilidades. El uso de las habilidades aprendidas puede aprovecharse en diversas tareas, pero estas habilidades pueden resultar bastante impredecibles, lo cual puede dificultar su uso. En este artículo, analizaremos un algoritmo para el aprendizaje de habilidades predecibles.
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Hoy analizaremos los grupos monoidales como un medio que normaliza conjuntos de monoides y los hace más comparables entre una gama más amplia de conjuntos de monoides y tipos de datos.
El problema del aprendizaje por refuerzo reside en la necesidad de definir una función de recompensa, que puede ser compleja o difícil de formalizar. Para resolver esto, se están estudiando enfoques basados en la variedad de acciones y la exploración del entorno que permiten aprender habilidades sin una función de recompensa explícita.
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.
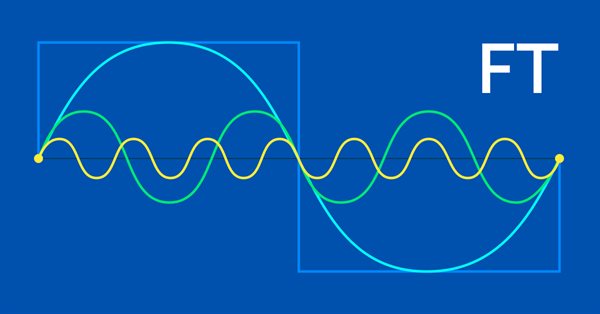
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.