Вы могли не заметить, что моделирование матриц оказалось немного странным, так как указывались не строки и столбцы, а только столбцы. Это выглядит очень странно при чтении кода, выполняющего матричные факторизации. Если вы ожидали увидеть указанные строки и столбцы, то могли бы запутаться при попытке выполнить факторизацию. Более того, данный способ моделирования матриц не самый лучший. Это связано с тем, что когда мы моделируем матрицы таким образом, то сталкиваемся с некими ограничениями, которые заставляют нас использовать другие методы или функции, которые не были бы необходимы, если бы моделирование осуществлялось более подходящим способом.
Продолжаем, начатую в предыдущей статье работу, по построению фреймворка RefMask3D средствами MQL5. Данный фреймворк разработан для всестороннего изучения мультимодального взаимодействия и анализа признаков в облаке точек, с последующей идентификацией целевого объекта на основе описания, предоставленного на естественном языке.
В этой статье мы пересмотрим классическую стратегию торговли сырой нефтью с целью ее усовершенствования за счет использования алгоритмов машинного обучения с учителем. Мы построим модель наименьших квадратов для прогнозирования будущих цен на нефть марки Brent на основе разницы между ценами на нефть марки Brent и WTI. Наша цель — найти опережающий индикатор будущих изменений цен на нефть марки Brent.
Предпринята попытка построить торговый эксперт для предсказания котировок валютных курсов. За основу алгоритма взяты классические модели классификации — логистическая и пробит регрессия. В качестве фильтра торговых сигналов используется критерий отношения правдоподобия.
В этой статье мы представим полное руководство для начинающих по созданию советников (EA) на MQL5. Вы найдете пошаговые инструкции по созданию экспертов с использованием псевдокода и возможностей кода, сгенерированного ИИ. Эта статья предназначена для тех, кто только начинает свой пусть в алготрейдинге, а также для всех, кто хочет улучшить навыки разработки эффективных советников.
В статье представлен Алгоритм Искусственного Орошения (ASHA) – новый метаэвристический метод, разработанный для решения общих задач оптимизации. Основанный на моделировании процессов потоков и накопления воды, этот алгоритм выстраивает концепцию идеального поля, в котором каждая единица ресурса (вода) вызывается для поиска оптимального решения. Узнайте, как ASHA адаптирует принципы потока и накопления для эффективного распределения ресурсов в условиях поискового пространства, а также познакомьтесь с его реализацией и итогами тестирования.
Символьная регрессия — это форма регрессии, которая начинается с минимальных или нулевых предположений относительно того, как будет выглядеть базовая модель, отображающая изучаемые наборы данных. Несмотря на то, что ее можно реализовать с помощью байесовских методов или нейронных сетей, мы рассмотрим, как реализация с использованием генетических алгоритмов может помочь настроить класс сигналов советника, пригодный для использования в Мастере MQL5.
В процессе анализа рыночной ситуации мы делим её на отдельные сегменты, выявляя ключевые тенденции. Однако традиционные методы анализа часто фокусируются на одном аспекте, что ограничивает восприятие. В данной статье мы познакомимся с методом, позволяющем выделять несколько объектов, что даёт более полное и многослойное понимание ситуации.
В статье объясняется, как использовать треугольный арбитраж, а также как применять прогнозы и специализированное программное обеспечение для более разумной торговли валютами, даже если вы новичок на рынке. Готовы торговать как профессионалы?
В данной статье мы продолжим погружение в реализацию алгоритма ACMO (Atmospheric Cloud Model Optimization). В частности, обсудим два ключевых аспекта: перемещение облаков в регионы с низким давлением и моделирование процесса дождя, включая инициализацию капель и распределение их между облаками. Мы также разберем другие методы, которые играют важную роль в управлении состоянием облаков и обеспечении их взаимодействия с окружающей средой.
В данной статье предлагаем познакомиться с методом Mask-Attention-Free Transformer (MAFT) и его применение в области трейдинга. В отличие от традиционных Transformer, требующих маскирования данных при обработке последовательностей, MAFT оптимизирует процесс внимания, устраняя необходимость в маскировании, что значительно повышает вычислительную эффективность.
Статья посвящена метаэвристическому алгоритму Atmosphere Clouds Model Optimization (ACMO), который моделирует поведение облаков для решения задач оптимизации. Алгоритм использует принципы генерации, движения и распространения облаков, адаптируясь к "погодным условиям" в пространстве решений. Статья раскрывает, как метеорологическая симуляция алгоритма находит оптимальные решения в сложном пространстве возможностей и подробно описывает этапы работы ACMO, включая подготовку "неба", рождение облаков, их перемещение и концентрацию дождя.
Ложные регрессии возникают, когда два временных ряда демонстрируют высокую степень корреляции чисто случайно, что приводит к вводящим в заблуждение результатам регрессионного анализа. В таких случаях, даже если переменные кажутся связанными, корреляция является случайной и модель может быть ненадежной.
В данной статья предлагаем познакомиться с методом сегментации 3D-люъектов на основе Superpoint Transformer (SPFormer), который устраняет необходимость в промежуточной агрегации данных. Что ускоряет процесс сегментации и повышает производительность модели.
Поиск нейронной архитектуры (Neural Architecture Search), автоматизированный подход к определению идеальных настроек нейронной сети, может стать преимуществом при наличии большого количества вариантов и больших наборов тестовых данных. Здесь мы рассмотрим, как этот подход можно сделать еще более эффективным с помощью парных собственных векторов (Eigen Vectors).
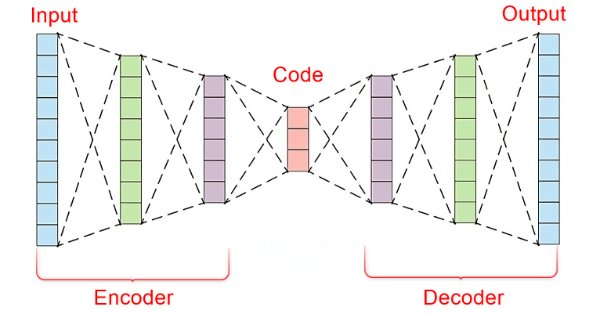
В динамичном мире финансовых рынков для успешно торговли важно уметь отделять значимые сигналы от шума. Используя сложную архитектуру нейронных сетей, автоэнкодеры успешно выявляют скрытые закономерности в рыночных данных и преобразуют нечеткие входные данные в полезные идеи. В этой статье мы рассмотрим, как такие нейросети могут помочь принимать торговые решения на современных динамичных рынках.
Мы рассмотрим статистический арбитраж, выполним поиск символов корреляции и коинтеграции с помощью Python, создадим индикатор для коэффициента Пирсона, а также советник для торговли статистическим арбитражем с прогнозами, сделанными с помощью Python и моделей ONNX.
Статья представляет реализацию алгоритма выбора признаков, описанного в научной работе "FREL: Стабильный алгоритм выбора признаков" (FREL: A stable feature selection algorithm). Сам алгоритм называется "Взвешивание признаков как регуляризованное обучение на основе энергии" (Feature weighting as regularized energy based learning).
Эффективное выявление и сохранение локальной структуры рыночных данных в условиях шума является важной задачей в трейдинге. Использование механизма Self-Attention показало хорошие результаты в обработке подобных данных, но классический метод не учитывают локальные особенности исходной структуры. В данной статье я предлагаю познакомиться с алгоритмом, способным учитывать эти структурные зависимости.
Предлагаем вам познакомиться с новым подход обнаружения объектов при помощи гиперсетей. Гиперсети могут генерировать весовые коэффициенты для основной модели, что позволяет учитывать особенности текущего состояния рынка. Такой подход позволяет улучшить точность прогнозирования, адаптируя модель к различным торговым условиям.
В данной статье подробно рассматривается алгоритм оптимизации, вдохновленный стрельбой из лука, с акцентом на использование метода рулетки в качестве механизма выбора перспективных областей для "стрел". Этот метод позволяет оценивать качество решений и отбирать наиболее многообещающие позиции для дальнейшего изучения.
В этой статье мы продолжаем изучение семейства алгоритмов группового учета аргументов. Реализуем средствами MQL5 комбинаторный алгоритм, а также его усовершенствованную версию — комбинаторный селективный алгоритм.
В данной статье мы поговорим об алгоритмах использования методов внимания при решении задач обнаружения объектов в облаке точек. Обнаружение объектов в облаках точек имеет важное значение для многих реальных приложений.
В статье представлена оригинальная версия алгоритма бактериальной хемотаксисной оптимизации (BCO) и его модифицированный вариант. Мы подробно рассмотрим все отличия, уделяя особое внимание новой версии BCOm, которая упрощает механизм движения бактерий, снижает зависимость от истории изменений позиций и использует более простые математические операции по сравнению с перегруженной вычислениями оригинальной версией. Также будут проведены тесты и подведены итоги.
Продолжаем изучение алгоритмов для извлечения признаков из облака точек. И в данной статье мы познакомимся с механизмами повышения эффективности метода PointNet.
В статье рассматривается метод главных компонент — метод снижения размерности при анализе данных, а также то, как его можно реализовать с использованием собственных значений и векторов. Как всегда, мы попытаемся разработать прототип класса сигналов советника, который можно будет использовать в Мастере MQL5.
ONNX — отличный инструмент для интеграции сложного ИИ-кода на разных платформах. Однако при его использовании возникают некоторые сложности, которые необходимо преодолеть, чтобы извлечь из него максимальную пользу. В этой статье мы обсудим распространенные проблемы, с которыми вы можете столкнуться, и способы их устранения.
Прямой анализ облака точек позволяет избежать излишнего увеличения объема данных и повышает эффективность моделей в задачах классификации и сегментации. Подобные подходы демонстрируют высокую производительность и устойчивость к возмущениям в исходных данных.
Влияет ли положение планет и звезд на финансовые рынки? Вооружимся статистикой и большими данными и отправимся в увлекательное путешествие в мир, где пересекаются звезды и биржевые графики.
Продолжаем изучение метода Иерархического Векторного Transformer. И в данной статье мы завершим построение модели. А также проведем её обучение и тестирование на реальных исторических данных.
В статье рассматривается алгоритм табу-поиска — один из первых и наиболее известных методов метаэвристики. Мы подробно разберем, как работает алгоритм, начиная с выбора начального решения и исследования соседних вариантов, с акцентом на использование табу-листа. Статья охватывает ключевые аспекты алгоритма и его особенности.
Продолжим изучение возможностей языка программирования MQL5. В этой статье, предназначенной для начинающих, мы продолжим изучать функции для работы массивами, перейдя к более сложным концепциям, которые обязательно пригодятся при разработке эффективных торговых стратегий. В этот раз познакомимся с функциями ArrayPrint, ArrayInsert, ArraySize, ArrayRange, ArrarRemove, ArraySwap, ArrayReverse и ArraySort. Функции массивы знать обязательно, если вы хотите достичь высокого уровня в области алготрейдинга. Это очередная глава на пути к мастерству.
Поскольку цель здесь дидактическая, мы будем действовать максимально просто. То есть мы будем реализовывать только то, что нам необходимо: умножение матриц. Вы сегодня увидите, что этого достаточно для симуляции умножения матрицы на скаляр. Самая существенная трудность, с которой многие сталкиваются при реализации кода с использованием матричной факторизации, заключается в следующем: в отличие от скалярной факторизации, где почти во всех случаях порядок факторов не меняет результат, при использовании матриц это не так.
Предлагаем познакомиться с методом Иерархический Векторный Transformer (HiVT), который был разработан для быстрого и точного прогнозирования мультимодальных временных рядов.
Метод опорных векторов (Support Vector Machines) классифицирует данные на основе предопределенных классов, исследуя эффекты увеличения их размерности. Это метод обучения с учителем, который довольно сложен, учитывая его потенциальную возможность работы с многомерными данными. В этой статье мы рассмотрим, как эффективнее реализовать базовую версию двумерных данных с помощью полинома Ньютона при классификации ценовых действий.
Как уже объяснялось в теоретической части, при работе с нейронными сетями нам необходимо использовать линейные регрессии и производные. Но почему? Причина заключается в том, что линейная регрессия - одна из самых простых существующих формул. По сути, линейная регрессия - это просто аффинная функция. Однако, когда мы говорим о нейронных сетях, нас не интересуют эффекты прямой линейной регрессии. Нас интересует уравнение, которое порождает данную прямую. Созданная прямая не имеет большого значения. Но знаете ли вы, какое главное уравнение мы должны понять? Если нет, то я вам рекомендую прочесть эту статью, чтобы начать разбираться в этом.
Понимание поведения агентов важно в разных областях, но большинство методов фокусируются на одной задаче (понимание, удаление шума, прогнозирование), что снижает их эффективность в реальных сценариях. В данной статье я предлагаю познакомиться с моделью, которая способна адаптироваться к решению различных задач.
В данной статье рассматривается алгоритм искусственных водорослей (AAA), разработанный на основе биологических процессов, характерных для микроводорослей. Алгоритм включает спиральное движение, эволюционный процесс и адаптацию, что позволяет ему решать задачи оптимизации. Статья предлагает глубокий анализ принципов работы AAA и его потенциала в математическом моделировании, подчеркивая связь между природой и алгоритмическими решениями.