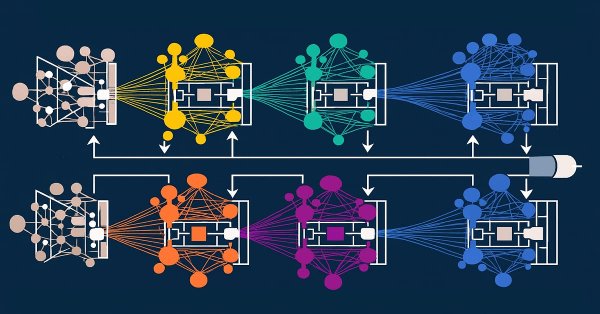
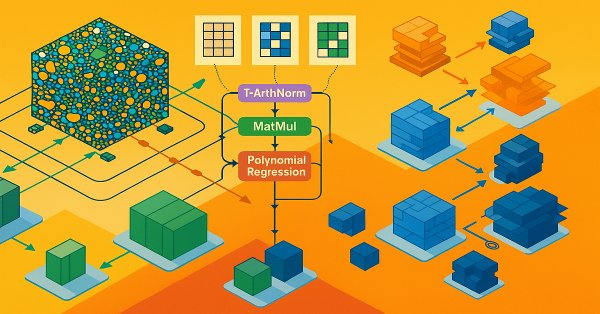
В статье мы завершаем работу по построению фреймворка SAGDFN средствами MQL5, подводя итоги разработки и демонстрируя результаты его практического тестирования. Объединим реализованные ранее модули в единую систему^ покажем сильные стороны подхода, отметим его уязвимости и обсудим возможные пути доработки.
В этой статье мы подробно рассмотрим практическую реализацию ключевых компонентов фреймворка SAGDFN. Покажем, как организованы разреженное внимание и выбор значимых соседей для прогнозирования временных рядов. Представленные подходы демонстрируют баланс между точностью прогнозов и эффективностью вычислений.
Soft Actor Critic (мягкий актер-критик) — это алгоритм обучения с подкреплением, использующий три нейронные сети — сеть актеров и две сети критиков. Такие модели машинного обучения объединены в партнерство "главный-подчиненный", где критики моделируются для повышения точности прогнозов сети актеров. Как обычно, рассмотрим, как эти идеи можно протестировать в качестве пользовательского сигнала советника, собранного с помощью Мастера.
Стратегия Darvas Box Breakout, созданная Николасом Дарвасом, представляет собой подход в технической торговле, который выявляет потенциальные сигналы на покупку, когда цена акций поднимается выше установленного диапазона «коридора», что указывает на сильный восходящий импульс. В этой статье мы применим эту стратегическую концепцию в качестве примера для изучения трех передовых методов машинного обучения. К ним относятся использование модели машинного обучения для генерации сигналов вместо фильтрации сделок, применение непрерывных сигналов вместо дискретных и использование для подтверждения сделок моделей, обученных на разных таймфреймах.
В статье мы раскрываем архитектуру SAGDFN — современного фреймворка, способного преобразовать подход к обработке пространственно-временных данных. Он сохраняет ключевую информацию даже в сложных графах и при этом снижает вычислительные издержки.
Статья представляет революционную архитектуру PatchTST — специально адаптированный трансформер для анализа финансовых временных рядов, который разбивает рыночные данные на патчи из 16 баров для эффективной обработки. Подробно рассматривается полная реализация торгового робота в MQL5 — от математических основ и структур данных до готового Expert Advisor с системами управления рисками и непрерывного обучения.
В этой статье рассмотрим и реализуем методы оценки качества модели, которые используют один и тот же набор данных как для обучения, так и для проверки.
В статье описана практическая реализация фреймворка HimNet на базе MQL5, который готов к интеграции в автоматическую торговлю. Мы показываем, как метапараметры, адаптированные под гетерогенность, превращают модель в универсальный инструмент, способный справляться с изменчивой волатильностью.
В этой статье мы подробно рассматриваем алгоритмы реализации ключевых компонентов фреймворка HimNet. Демонстрируем, как при минимальном числе обучаемых компонентов достигается высокая согласованность и управляемость всей системы. Представленная реализация отличается компактностью и прозрачностью, что облегчает её адаптацию к реальным рыночным задачам.
Статья представляет инновационную гибридную систему для прогнозирования валютных курсов, которая сочетает линейную авторегрессионную модель с архитектурой U-Transformer для анализа остатков. Система автоматически переключается между источниками сигналов в зависимости от их качества и включает полноценную торговую логику с averaging/pyramiding стратегиями. Ключевое преимущество подхода заключается в том, что нейросеть обучается на остатках линейной модели, что упрощает задачу и снижает риск переобучения. Реализация выполнена полностью на MQL5 и готова к использованию в реальной торговле с автоматической адаптацией к изменяющимся рыночным условиям.
Предлагаем познакомиться с фреймворком HimNet, который сочетает гибкость пространственно-временной адаптации с высокой вычислительной эффективностью, позволяя получать точные и стабильные прогнозы на финансовых временных рядах. В статье подробно показано, как его ключевые компоненты взаимодействуют между собой, превращая сложные алгоритмы в управляемую архитектуру.
Популяционный алгоритм оптимизации, вдохновленный спорным и малоизученным феноменом — механизмом человеческих сновидений. Группы агентов с разной "памятью", косинусоидальная модуляция движения и необычное распределение фаз 99/1 — узнайте, как эти особенности влияют на эффективность оптимизации ваших торговых стратегий.
Революционный подход к машинному обучению в трейдинге через квантовые вычисления. Статья демонстрирует практическую реализацию адаптивной системы QRC с постоянным дообучением для прогнозирования рыночных движений в реальном времени.
Представляем вашему вниманию завершающий этап реализации и тестирования фреймворка TQNet, в котором теория встречается с реальной торговой практикой. Мы пройдём путь от исторического обучения до стресс-теста на свежих рыночных данных, оценивая устойчивость и точность модели. Итоговые результаты — это не только сухие цифры, но и наглядная демонстрация прикладной ценности предложенного подхода.
Что если бы ваши торговые стратегии могли учиться друг у друга, как настоящие бойцы? Duelist Algorithm — новый метод оптимизации, где параметры торговых систем буквально сражаются в дуэлях за право называться лучшими.
Фреймворк TQNet открывает новые возможности в моделировании и прогнозировании финансовых временных рядов, сочетая модульность, гибкость и высокую производительность. В статье раскрывается возможность реализации сложных механизмом работы с глобальными корреляциями, включая продвинутые методы инициализации параметров.
В постоянно меняющемся мире трейдинга адаптация к изменениям на рынке — это просто необходимость. Каждый день появляются новые закономерности и тенденции, из-за чего даже самым продвинутым моделям машинного обучения становится сложно оставаться эффективными в меняющихся условиях. В этой статье мы поговорим о том, как поддерживать актуальность моделей и их способность реагировать на новые рыночные данные с помощью автоматического дообучения.
Статья исследует революционную архитектуру нейронной сети Mamba/SSM для прогнозирования финансовых временных рядов. Представлена полная реализация на MQL5 современной альтернативы Transformer с линейной сложностью O(N) вместо квадратичной O(N²). Детально рассмотрены селективные State Space Models, hardware-aware оптимизации, patching техники и продвинутые методы обучения AdamW. Включены практические результаты тестирования, показавшие увеличение точности с 62% до 71% при снижении времени обучения с 45 до 8 минут. Представлен готовый торговый советник с автообучением и адаптивным риск-менеджментом для MetaTrader 5.
Предлагаем познакомиться с алгоритмом разложения временного ряда на смысловые слои и построения из них экономной модели. Мы последовательно показываем архитектуру, практическую реализацию на MQL5/OpenCL и реальные тесты на исторических рыночных данных.
В данной статье мы представляем реализацию нескольких ансамблевых классификаторов на языке MQL5 и рассматриваем их эффективность в различных ситуациях.
Трейдинг характеризуется высокими требованиями к дисциплине риск-менеджмента. Настоящая работа представляет анализ основных причин неудач трейдеров и предлагает техническое решение в виде класса CEnhancedRiskManager для платформы MQL5. Включает практическое тестирование на агрессивном сеточном советнике.
Языковые модели (LLM) являются важной частью быстро развивающегося искусственного интеллекта, поэтому нам следует подумать о том, как интегрировать мощные LLM в нашу алгоритмическую торговлю. Большинству людей сложно настроить эти модели в соответствии со своими потребностями, развернуть их локально, а затем применить к алгоритмической торговле. В этой серии статей будет рассмотрен пошаговый подход к достижению этой цели.
В этой статье продолжаем практическое знакомство с SSCNN — архитектурным решением нового поколения, способным работать с фрагментированными временными рядами. Вместо слепого масштабирования — разумная модульность, внимание к деталям и точечная нормализация. Мы шаг за шагом создаём вычислительные блоки в среде MQL5 и закладываем основу для надёжного прогнозного анализа.
В этой части мы рассмотрим реализацию ключевых интерфейсов библиотеки Гауссовских процессов на MQL5 — IKernel, ILikelihood и IInference. Также мы продемонстрируем её работу на синтетических данных и и напишем индикаторы для классификации и регрессии, демонстрирующие её работу в онлайн-режиме — с переобучением модели на каждом новом баре.
В данной статье мы начинаем знакомство с фреймворком SSCNN — современным архитектурным решением для анализа временных рядов, сочетающим в себе точность, структурированность и высокую вычислительную эффективность. Мы последовательно рассмотрим его теоретические аспекты, обратим внимание на ключевые отличия от предшественников и начнем практическую реализацию базовых компонентов в среде MQL5.
В статье рассматриваются передовые методы интеграции MQL5 с мощными инструментами обработки данных, а также уделяется внимание эффективной обработке больших данных для улучшения торгового анализа и принятия решений.
Реализация алгоритма A3 на MQL5 — метаэвристического метода оптимизации, вдохновленного химическими процессами. Всего 2 настраиваемых параметра, компактность и небольшая популяция обеспечивают высокую скорость работы при достаточном качестве решений.
В статье подробно раскрывается SCNN-архитектура и один из вариантов её реализация средствами MQL5. Мы покажем, как декомпозиция временных рядов сочетается с нейросетевыми методами и вниманием.
Создаем торговую систему с настоящим квантовым симулятором вместо математических аналогий. Система использует 3 виртуальных кубита, квантовые гейты и принципы суперпозиции для анализа рынков. Реализована как торговый советник для MetaTrader 5 на MQL5. Главное достижение — переход от имитации к реальным квантовым принципам обработки финансовой информации.
Продолжение темы оптимизации научным сообществом. CoSO следует рассматривать не как готовое решение, а как перспективную исследовательскую платформу. При должной доработке, CoSO может найти свою нишу в задачах, где важна адаптивность и устойчивость к изменениям, а время вычислений не критично.
Предлагаем познакомиться с продолжением реализации фреймворка SCNN, который сочетает в себе гибкость и интерпретируемость, позволяя точно выделять структурные компоненты временного ряда. В статье подробно раскрываются механизмы адаптивной нормализации и внимания, что обеспечивает устойчивость модели к изменяющимся рыночным условиям.
Секреты эффективной оптимизации торговых стратегий в метаэвристических подходах. Community of Scientist Optimization — новый популяционный алгоритм, вдохновленный механизмами функционирования научного сообщества. В отличие от традиционных природных метафор, CoSO моделирует уникальные аспекты человеческой научной деятельности: публикацию результатов в журналах, конкуренцию за гранты и формирование исследовательских групп.
В статье представлена инновационная архитектура квантовой нейронной сети для алгоритмической торговли, объединяющая принципы квантовой механики с современными методами машинного обучения. Система включает квантовые эффекты (резонанс, интерференцию, декогеренцию), многоуровневую память различных временных масштабов, марковские цепи с библиотекой ALGLIB и адаптивное управление параметрами. Полная реализация выполнена на MQL5 с использованием встроенных типов matrix/vector, что устраняет барьеры внедрения в MetaTrader 5.
Предлагаем познакомиться с инновационным фреймворком SCNN, который выводит анализ временных рядов на новый уровень за счёт чёткого разделения данных на долгосрочные, сезонные, краткосрочные и остаточные компоненты. Такой подход значительно повышает точность прогнозирования, позволяя модели адаптироваться к сложной и меняющейся рыночной динамике.
В настоящей статье показано, что часть проблем, с которыми мы сталкиваемся, коренится в слепом следовании «лучшим практикам». Предоставляя читателю простые, основанные на реальном рынке доказательства, мы объясним ему, почему мы должны воздержаться от такого поведения и вместо этого принять передовой опыт, основанный на конкретных областях, если наше сообщество хочет получить хоть какой-то шанс на восстановление скрытого потенциала ИИ.
В статье представлен алгоритм конкурентного обучения (Competitive Learning Algorithm, CLA) — новый метаэвристический метод оптимизации, основанный на моделировании образовательного процесса. Алгоритм организует популяцию решений в виде классов со студентами и учителями, где агенты обучаются через три механизма: следование за лучшим в классе, использование личного опыта и обмен знаниями между классами.
Представляем вашему вниманию заключительную часть цикла, посвящённого GinAR — нейросетевому фреймворку для прогнозирования временных рядов. В этой статье мы анализируем результаты тестирования модели на новых данных и оцениваем её устойчивость в условиях реального рынка.
В данной статье мы рассмотрим модель классификации гауссовских процессов. Мы начнём с изучения её теоретических принципов, а затем перейдём к практической разработке библиотеки ГП на MQL5.
Предлагаем познакомиться с новой реализацией ключевых компонентов Фреймворка GinAR — адаптивного алгоритма для работы с графовыми временными рядами. В статье шаг за шагом разобраны архитектура, алгоритмы прямого прохода и обратного распространения ошибки.
ROC-кривые — графические представления, используемые для оценки эффективности классификаторов. Хотя графики ROC относительно просты, на практике при их использовании существуют распространенные заблуждения и подводные камни. Цель данной статьи — познакомить читателя с графиками ROC как инструментом для практикующих специалистов, стремящихся разобраться в оценке эффективности классификаторов.