En este artículo, vamos a empezar a hacer algo que ojalá hubiera hecho hace mucho más tiempo. Sin embargo, debido a la falta de "terreno firme", no me sentía seguro para presentarlo públicamente. Ahora, tengo las bases para poder hacer lo que vamos a empezar a hacer a partir de ahora. Es una buena idea centrarse al máximo en comprender el contenido de este artículo, y no lo digo para que lo leas por leer. Quiero y necesito recalcar que, si no entiendes este artículo en concreto, puedes abandonar por completo cualquier esperanza de comprender el contenido de los siguientes.
Una de las cosas que más nos puede complicar la vida como programadores es el hecho de suponer cosas. En este artículo, te mostraré los peligros de hacer suposiciones: tanto en la parte de programación MQL5, donde se asume que un tipo tendrá un tamaño determinado, como cuando se utiliza MetaTrader 5, donde se asume que los diferentes servidores funcionan de la misma manera.
Tenemos que arreglar algunas cosas antes de poder continuar de verdad. Pero no es necesariamente una corrección, sino una mejora en la forma de gestionar y utilizar la clase. La razón es que hay fallos debidos a algún tipo de interacción dentro del sistema. A pesar de los intentos de comprender la razón de algunos de los fallos, para ponerles fin, todos ellos se vieron frustrados, ya que algunos no tenían sentido. Cuando usamos punteros o recursión en C / C++, y el programa empieza a fallar.
En este artículo concluiremos la primera fase de la construcción. Aunque será algo relativamente rápido, explicaré detalles que quizás no se comentaron anteriormente. Pero aquí explicaré algunas cosas que mucha gente no entiende por qué son como son. Uno de estos casos es el del ratón. ¡¡¡¿Sabes por qué tienes que pulsar la tecla Shift o Ctrl en tu teclado?!!!
Vamos a continuar el desarrollo del sistema de órdenes, pero verás que haremos una reutilización masiva de cosas ya vistas en otros artículos. Aun así, tendremos una pequeña recompensa en este artículo. Desarrollaremos, en primer lugar, un sistema que pueda ser operado junto al servidor de negociación real, ya sea usando una cuenta demo o una cuenta real. Haremos uso masivo y extensivo de la plataforma MetaTrader 5 para proporcionarnos todo el soporte que necesitaremos en este inicio de viaje.
En este artículo, analizaremos otro algoritmo de optimización inspirado en la naturaleza inanimada: el algoritmo de búsqueda de sistema cargado (CSS). El objetivo de este artículo es presentar un nuevo algoritmo de optimización basado en los principios de la física y la mecánica.
La clasificación de datos para el análisis y la predicción es un área muy diversa del aprendizaje automático con un gran número de enfoques y métodos. En este artículo analizaremos uno de estos enfoques, a saber, la Clasificación Jerárquica Aglomerativa (Agglomerative Hierarchical Classification).
Sumérjase en el mundo de ONNX, un potente formato abierto para compartir modelos de aprendizaje automático. Descubra cómo el uso de ONNX puede revolucionar el trading algorítmico en MQL5, permitiendo a los tráders integrar sin problemas modelos avanzados de IA y llevar sus estrategias al siguiente nivel. Descubra los secretos de la compatibilidad multiplataforma y aprenda a liberar todo el potencial de ONNX en sus operaciones MQL5. Mejore sus operaciones con esta guía detallada de ONNX.
En este artículo veremos la búsqueda por difusión estocástica, o SDS, que es un algoritmo de optimización muy potente y eficiente basado en los principios del paseo aleatorio. El algoritmo puede encontrar soluciones óptimas en espacios multidimensionales complejos, con una alta tasa de convergencia y la capacidad de evitar extremos locales.
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.
En este artículo, seguiremos analizando desde un nuevo ángulo los indicadores comerciales más populares. Vamos a procesar una composición horizontal de transformaciones naturales. El mejor indicador para ello será la media móvil exponencial doble (Double Exponential Moving Average, DEMA).
De todas las cosas desarrolladas hasta ahora, esta, como seguramente también notarás y con el tiempo estarás de acuerdo, es la más desafiante de todas. Lo que tenemos que hacer es algo simple: hacer que nuestro sistema simule lo que hace un servidor comercial en la práctica. Esto de tener que implementar una forma de simular exactamente lo que haría el servidor comercial parece simple. Al menos en palabras. Pero necesitamos hacer esto de manera que, para el usuario del sistema de repetición/simulación, todo suceda de la manera más invisible o transparente posible.
Desarrollar una manera de poner un cronómetro, de modo que durante una repetición/simulación, éste pueda decirnos cuánto tiempo falta, puede parecer a primera vista una tarea simple y de rápida solución. Muchos simplemente intentarían adaptar y usar el mismo sistema que se utiliza cuando tenemos el servidor comercial a nuestro lado. Pero aquí reside un punto que muchos quizás no consideran al pensar en tal solución. Cuando estás haciendo una repetición, y esto para no hablar del hecho de la simulación, el reloj no funciona de la misma manera. Este tipo de cosa hace complejo construir tal sistema.
Aquí te mostraré una técnica que puede ayudarte mucho en varios momentos de tu vida como programador. En contra de lo que muchos dicen, lo limitado no es la plataforma, sino los conocimientos del individuo que lo dice. Lo que se explicará aquí es que con un poco de sentido común y creatividad, se puede hacer que la plataforma MetaTrader 5 sea mucho más interesante y versátil, sin tener que crear programas locos ni nada por el estilo puedes crear un código sencillo, pero seguro y fiable. Utiliza tu ingenio para domar el código con el fin de modificar algo que ya existe, sin eliminar ni añadir una sola línea al código original.
Ahora que hemos mejorado la clase C_Mouse, podemos concentrarnos en crear una clase destinada a establecer una base totalmente nueva de estudios. Como mencioné al inicio del artículo, no utilizaremos herencia o polimorfismo para crear esta nueva clase. En cambio, vamos a modificar, o mejor, agregar nuevos objetos a la línea de precio. Esto es lo que haremos en este primer momento, y en el próximo artículo, mostraré cómo cambiar los estudios. Pero, realizaremos esto sin cambiar el código de la clase C_Mouse. Reconozco que, en la práctica, esto sería más fácilmente logrado mediante herencia o polimorfismo. No obstante, existen otras técnicas para alcanzar el mismo resultado.
En este artículo, analizaremos un algoritmo de la familia MEC llamado algoritmo MEC Simple de evolución mental (Simple MEC, SMEC). El algoritmo se caracteriza por la belleza de la idea expuesta y su sencillez de aplicación.
Este artículo, el número 21 de nuestra serie, continuaremos analizando las transformaciones naturales y cómo se pueden implementar mediante el análisis discriminante lineal. Como en el artículo anterior, la implementación se presentará en formato de clase de señal.
El artículo presenta una descripción detallada del algoritmo de salto de rana aleatorio (SFL) y sus capacidades para resolver problemas de optimización. El algoritmo SFL se inspira en el comportamiento de las ranas en su entorno natural y ofrece un enfoque innovador para la optimización de características. El algoritmo SFL supone una herramienta eficaz y flexible que puede gestionar una gran variedad de tipos de datos y alcanzar soluciones óptimas.
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.
Continuamos analizando las transformaciones naturales considerando la inducción cuadrática de la naturalidad. Pequeñas restricciones en la implementación de las capacidades multidivisa para los asesores ensamblados usando el wizard MQL5 significan que estamos demostrando nuestras capacidades en la clasificación de datos usando un script. Las principales áreas de aplicación son la clasificación de las variaciones de precios y, como consecuencia, su previsión.
Cuando los primeros sistemas capaces de factorizar algo comenzaron a ser producidos, todo requería la intervención de ingenieros con un amplio conocimiento sobre lo que se estaba diseñando. Estamos hablando de los albores de la computación, una época en la que ni siquiera existían terminales que permitieran la programación de algo. A medida que el desarrollo avanzaba y crecía el interés para que más personas pudieran crear algo, surgían nuevas ideas y métodos para programar esas máquinas, que antes dependían de la modificación de la posición de los conectores. Fue entonces cuando aparecieron los primeros terminales.
En este artículo, daremos vida a la clase C_Mouse. Está diseñada para permitir programar al más alto nivel posible. Sin embargo, hablar de programar a niveles altos o bajos no está relacionado con incluir palabrotas o jerga en el código. Todo lo contrario. Cuando mencionamos programación de alto o bajo nivel, nos referimos a lo fácil o difícil que es para otro programador entender el código.
Podemos comenzar a elaborar un EA para uso en repetición/simulación. Sin embargo, necesitamos algo refinado, no solo una solución cualquiera. No debemos, no obstante, ser intimidados por la complejidad inicial. Es esencial iniciar de algún punto, si no, acabaremos por acomodarnos, reflexionando sobre la dificultad del desafío sin realmente intentar superarlo. La esencia de la programación es exactamente esa: enfrentar un obstáculo y buscar superarlo a través de estudio, pruebas y extensa investigación.
En esta serie de artículos, presentaremos varias técnicas de etiquetado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El etiquetado específico de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorar la precisión del modelo e incluso ayudarle a dar un salto cualitativo.
En este artículo, concluimos la primera fase del desarrollo del sistema de repetición y simulador. Con este hito, afirmo, estimado lector, que el sistema ha alcanzado un nivel avanzado, abriendo camino para la incorporación de nuevas funcionalidades. El objetivo es enriquecer aún más el sistema, convirtiéndolo en una herramienta poderosa para estudios y para el desarrollo de análisis de mercado.
Hoy eliminaremos la restricción que impedía la ejecución de simulaciones basadas en el trazado de LAST e introduciremos un nuevo punto de entrada específico para este tipo de simulación. Ahora, vean que todo el mecanismo operativo se fundamentará en los principios del mercado de divisas. La principal distinción en esta rutina reside en la separación entre las simulaciones BID y LAST. Pero, es importante notar que la metodología empleada en la aleatorización del tiempo y su ajuste para la compatibilidad con la clase C_Replay permanece idéntica en ambos tipos de simulación. Esto es bueno, pues las alteraciones en uno de los modos resultan en mejoras automáticas en el otro, especialmente en lo que concierne al manejo del tiempo entre los ticks.
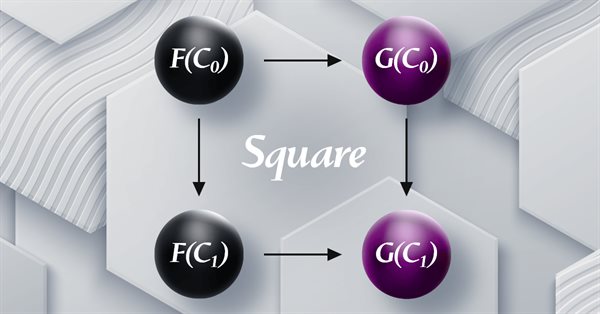
El artículo continúa la serie sobre teoría de categorías, presentando transformaciones naturales que suponen un elemento clave de la teoría. Hoy echaremos un vistazo a su definición (aparentemente compleja) y luego profundizaremos en los ejemplos y métodos de aplicación de las transformaciones para pronosticar la volatilidad.
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.
En este artículo echaremos un vistazo a cómo podemos realizar pruebas de permutación sobre la base de datos de ticks barajados en cualquier asesor experto utilizando solo MetaTrader 5.
El artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5, analizando los funtores como un puente entre grafos y conjuntos. Volveremos nuevamente a los datos del calendario y, a pesar de sus limitaciones en el uso de un simulador de estrategias, justificaremos el uso de funtores para predecir la volatilidad mediante la correlación.
En este artículo mostraré al lector un enfoque del trading algorítmico completamente distinto al que he tenido que llegar después de bastante tiempo. Obviamente, todo esto está relacionado con mi programa de fuerza bruta, que ha sufrido una serie de cambios que le permiten resolver varios problemas al mismo tiempo. No obstante, el artículo ha resultado lo más general y sencillo posible, por lo que también resultará apto para quienes no conocen el tema o simplemente están de paso.
En el marco del presente enfoque de ingeniería desarrollado por el autor, basado en la teoría de la probabilidad, se encuentran las condiciones para abrir una posición rentable, y también se calculan los valores óptimos (que maximizan las ganancias) para el stop loss y el take profit.
En este artículo nos familiarizaremos con uno de los métodos de análisis espectral y de procesamiento de señales: la transformada discreta de Hartley. Con ella podremos filtrar señales, analizar su espectro y mucho más. Las capacidades de la DHT no son inferiores a las de la transformada discreta de Fourier. Sin embargo, a diferencia de este, la DHT utiliza solo números reales, lo cual la hace más cómoda de implementar en la práctica y los resultados de su aplicación resultan más visuales.
El artículo analiza cómo se pueden incluir esquemas de bases de datos para la clasificación en MQL5. Vamos a repasar brevemente cómo los conceptos de esquema de base de datos pueden combinarse con la teoría de categorías para identificar información textual (cadenas) relevante para el comercio. La atención se centrará en los eventos del calendario.
La creación ahora se realiza en el mismo punto en el que convertimos los ticks en barras. Así, si algo va mal durante la conversión, nos daremos cuenta del error enseguida. Esto se debe a que el mismo código que coloca las barras de 1 minuto en el gráfico cuando avanzamos rápidamente también se utiliza para el sistema de posicionamiento y para colocar las barras durante el avance normal. En otras palabras, el código responsable de esta tarea ya no se duplica en ningún lugar. De esta manera, tenemos un sistema mucho más adecuado tanto para el mantenimiento como para las mejoras.
Para aquellos que aún no han comprendido la diferencia entre el mercado de acciones y el mercado de divisas (forex), a pesar de que este ya es el tercer artículo en el que abordo esto, debo dejar claro que la gran diferencia es el hecho de que en forex no existe, o mejor dicho, no se nos informa acerca de algunas cosas que realmente ocurrieron en la negociación.
Vamos a continuar el armado del sistema para cubrir el mercado FOREX. Entonces, para resolver este problema, primero necesitaríamos declarar la carga de los ticks antes de cargar las barras previas. Esto soluciona el problema, pero al mismo tiempo obliga al usuario a seguir un tipo de estructura en el archivo de configuración que, en mi opinión, no tiene mucho sentido. La razón es que, al desarrollar la programación responsable de analizar y ejecutar lo que está en el archivo de configuración, podemos permitir que el usuario declare las cosas en cualquier orden.
La intención inicial de este artículo no será cubrir todas las características de FOREX, sino más bien adaptar el sistema de manera que puedas realizar al menos una repetición del mercado. La simulación quedará para otro momento. Sin embargo, en caso de que no tengas los ticks y solo tengas las barras, con un poco de trabajo, puedes simular posibles transacciones que podrían haber ocurrido en FOREX. Esto será hasta que te muestre cómo adaptar el simulador. El hecho de intentar trabajar con datos provenientes de FOREX dentro del sistema sin modificarlo conlleva errores de rango.
Lo que vamos a hacer aquí es preparar el terreno para que, cuando sea necesario agregar nuevas funciones al código, esto se haga de manera fluida y sencilla. El código actual aún no puede cubrir o manejar algunas cosas que serán necesarias para un progreso significativo. Necesitamos que todo se construya de manera que el esfuerzo de implementar algunas cosas sea lo más mínimo posible. Si esto se hace adecuadamente, tendremos la posibilidad de tener un sistema realmente muy versátil. Capaz de adaptarse muy fácilmente a cualquier situación que deba ser cubierta.
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).