La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.
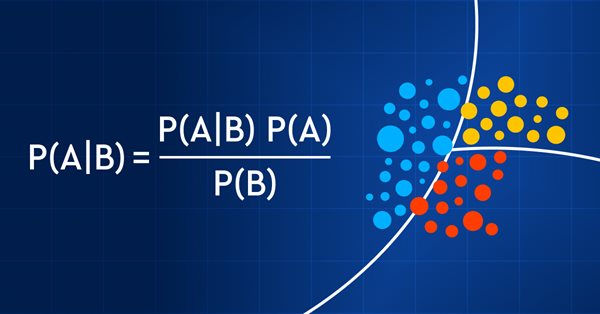
Comerciar con probabilidades es como caminar por la cuerda floja: requiere precisión, equilibrio y una clara comprensión del riesgo. En el mundo del trading, la probabilidad lo es todo: es lo que determina el resultado, el éxito o el fracaso, los beneficios o las pérdidas. Usando el poder de la probabilidad, los tráders pueden tomar decisiones mejor informadas, gestionar el riesgo con mayor eficacia y alcanzar sus objetivos financieros. Tanto si es usted un inversor experimentado como un tráder principiante, comprender las probabilidades puede ser la clave para liberar su potencial comercial. En este artículo, analizaremos el fascinante mundo del trading probabilístico y le mostraremos cómo llevar su modo de comerciar al siguiente nivel.
Hoy estudiaremos y pondremos a prueba un algoritmo de optimización muy potente, la búsqueda armónica (HS), que se inspira en el proceso de búsqueda de la armonía sonora perfecta. ¿Qué algoritmo lidera ahora mismo nuestra clasificación?
¿Qué te parece crear un sistema para estudiar el mercado cuando está cerrado o simular situaciones de mercado? Aquí iniciaremos una nueva secuencia de artículos para tratar este tema.
El GSA es un algoritmo de optimización basado en la población e inspirado en la naturaleza no viviente. La simulación de alta fidelidad de la interacción entre los cuerpos físicos, gracias a la ley de la gravedad de Newton presente en el algoritmo, permite observar la mágica danza de los sistemas planetarios y los cúmulos galácticos, capaz de hipnotizar en la animación. Hoy vamos a analizar uno de los algoritmos de optimización más interesantes y originales. Adjuntamos un simulador de movimiento de objetos espaciales.
Alan Andrews es uno de los "educadores" más célebres del mundo moderno en el campo del trading. Su "tridente" está incluido en casi todos los programas modernos de análisis de cotizaciones, pero la mayoría de los tráders no utilizan ni una quinta parte de las posibilidades que ofrece esta herramienta. Y el curso original de Andrews incluye una descripción no solo del tridente (aunque sigue siendo lo esencial), sino también de algunas otras líneas útiles. Este artículo ofrece al lector una idea de las maravillosas técnicas de análisis de gráficos que Andrews enseñó en su curso original. Le advertimos que hay muchas fotos.
El aprendizaje automático se ha convertido en una técnica popular de desarrollo de estrategias. Por lo general, en el trading se presta más atención a la maximización de la rentabilidad y la precisión de los pronósticos. Al mismo tiempo, el procesamiento de los datos utilizados para la construcción de los modelos predictivos permanece en la periferia. En este artículo, analizaremos el uso del concepto de entropía para evaluar la idoneidad de los indicadores en la construcción de modelos predictivos, como se describe en el libro «Testing and Tuning Market Trading Systems» de Timothy Masters.
La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.
La estrategia de búsqueda de alimento de la bacteria E.coli inspiró a los científicos para crear el algoritmo de optimización BFO. El algoritmo contiene ideas originales y enfoques prometedores para la optimización y merece ser investigado en profundidad.
La asombrosa capacidad de las malas hierbas para sobrevivir en una gran variedad de condiciones inspiró la idea de un potente algoritmo de optimización. El IWO es uno de los mejores entre los analizados anteriormente.
Las cadenas de Markov son una poderosa herramienta matemática que se puede usar para modelar y predecir los datos de las series temporales en varios campos, incluido el financiero. En el modelado y la previsión de series temporales financieras, las cadenas de Markov se usan a menudo para modelar la evolución de los activos financieros a lo largo del tiempo, como los precios de las acciones o los tipos de cambio. Una de las principales ventajas de los modelos de cadenas de Markov es su simplicidad y sencillez de uso.
Hoy analizaremos el método de optimización «Búsqueda con ayuda del algoritmo de luciérnagas» 'Firefly Algorithm Search' (FA). Tras modificar el algoritmo, este ha pasado de ocupar un lugar marginal a convertirse en un verdadero líder en la tabla de calificación.
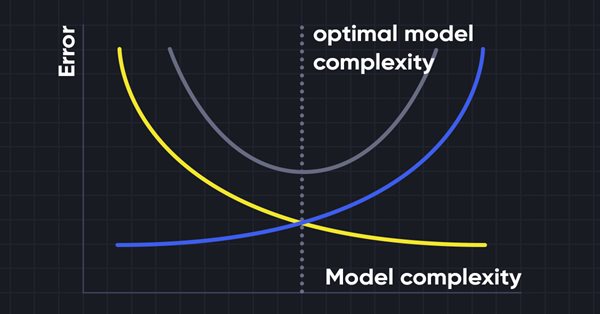
La regresión de cresta (Ridge Regression) es una técnica simple para reducir la complejidad del modelo y combatir el ajuste que puede derivar de una regresión lineal simple.
Las matrices sirven de base a los algoritmos de aprendizaje automático y a las computadoras en general por su capacidad para procesar con eficacia grandes operaciones matemáticas. La biblioteca estándar tiene todo lo que necesitamos, pero también podemos ampliarla añadiendo varias funciones al archivo utils.
La teoría de categorías es un área diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.
La búsqueda de bancos de peces (FSS) es un nuevo algoritmo de optimización moderno inspirado en el comportamiento de los peces en un banco, la mayoría de los cuales, hasta el 80%, nadan en una comunidad organizada de parientes. Se ha demostrado que las asociaciones de peces juegan un papel importante a la hora de buscar alimento y protegerse contra los depredadores de forma eficiente.
El siguiente algoritmo que analizaremos será la optimización de la búsqueda de cuco usando los vuelos de Levy. Este es uno de los últimos algoritmos de optimización, así como el nuevo líder en la clasificación.
Hoy analizaremos uno de los algoritmos de optimización más modernos: la Optimización del Lobo Gris. El original comportamiento de las funciones de prueba hace que este sea uno de los algoritmos más interesantes entre los analizados anteriormente. Uno de los líderes para la aplicación en el entrenamiento de redes neuronales y funciones suaves con muchas variables.
Seguimos analizando algoritmos de aprendizaje Q distribuidos. En artículos anteriores hemos analizado los algoritmos de aprendizaje Q distribuido y cuantílico. En el primero, enseñamos las probabilidades de los rangos de valores dados. En el segundo, enseñamos los rangos con una probabilidad determinada. Tanto en el primer algoritmo como en el segundo, usamos el conocimiento a priori de una distribución y enseñamos la otra. En el presente artículo, veremos un algoritmo que permite al modelo aprender ambas distribuciones.
Hoy estudiaremos el algoritmo de colonia artificial de abejas. Asimismo, complementaremos nuestros conocimientos con nuevos principios para el estudio de los espacios funcionales. En este artículo hablaremos sobre mi interpretación de la versión clásica del algoritmo.
El tráder moderno está casi siempre a la búsqueda de nuevas ideas, probando constantemente nuevas estrategias, modificándolas y descartando las que han fracasado. En esta serie de artículos, trataremos de demostrar que el Wizard MQL5 es la verdadera columna vertebral para un tráder en su búsqueda.
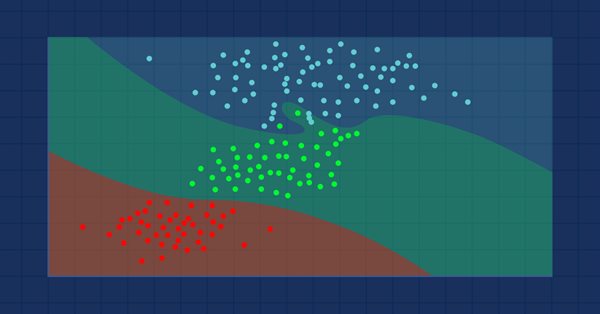
Se trata de un algoritmo perezoso que no aprende a partir de una muestra de entrenamiento, sino que almacena todas las observaciones disponibles y clasifica los datos en cuanto recibe una nueva muestra. A pesar de su sencillez, este método se usa en muchas aplicaciones del mundo real.
En esta ocasión, analizaremos el algoritmo de optimización de colonias de hormigas (ACO). El algoritmo es bastante interesante y ambiguo al mismo tiempo. Intentaremos crear un nuevo tipo de ACO.
En este artículo, analizaremos el popular algoritmo de optimización de la población «Enjambre de partículas» (PSO — particle swarm optimisation). Con anterioridad, ya discutimos características tan importantes de los algoritmos de optimización como la convergencia, la tasa de convergencia, la estabilidad, la escalabilidad, y también desarrollamos un banco de pruebas y analizamos el algoritmo RNG más simple.
La regresión polinomial es un modelo flexible diseñado para resolver de forma eficiente problemas que un modelo de regresión lineal no puede gestionar. En este artículo, aprenderemos a crear modelos polinómicos en MQL5 y a sacar provecho de ellos.
Este artículo trata sobre aquello que no encontrará en el informe de simulación, sobre qué esperar al usar un asesor, cómo administrar su dinero usando robots y cómo cubrir una pérdida significativa para seguir comerciando con el trading automatizado.
¿Qué tal si añadimos un nuevo tipo de gráfico a MetaTrader 5? Mucha gente dice que le faltan algunas cosas que ya están presentes en otras plataformas, pero lo cierto es que MetaTrader 5 es una plataforma muy práctica que nos permite hacer cosas que no es posible hacer en muchas otras plataformas, al menos no tan fácilmente.
Seguimos explorando el aprendizaje por refuerzo. En este artículo, hablaremos del método de aprendizaje Q profundo o deep Q-learning. El uso de este método permitió al equipo de DeepMind crear un modelo capaz de superar a los humanos jugando a los videojuegos de ordenador de Atari. Nos parece útil evaluar el potencial de esta tecnología para las tareas comerciales.
Continuamos estudiando los métodos de aprendizaje automático. En este artículo, iniciaremos otro gran tema llamado «Aprendizaje por refuerzo». Este enfoque permite a los modelos establecer ciertas estrategias para resolver las tareas. Esperamos que esta propiedad del aprendizaje por refuerzo abra nuevos horizontes para la construcción de estrategias comerciales.
En el artículo anterior, comenzamos a estudiar las redes neuronales con conexión directa, pero hay algunas cosas que quedaron sin resolver. Una de ellas es el diseño de la arquitectura. Por ello, en el presente artículo, veremos cómo diseñar una red neuronal flexible, teniendo en cuenta los datos de entrada, el número de capas ocultas y los nodos de cada red.
En este artículo, le mostraremos cómo calcular el beneficio o las pérdidas totales de cualquier operación, incluyendo la comisión y el swap. Hoy crearemos un modelo matemático más preciso, escribiremos el código basado en él y lo compararemos con un referente. También intentaremos meternos analizar los entresijos de la función principal de MQL5 para calcular el beneficio y llegaremos al fondo de todos los valores necesarios de la especificación.
En los últimos dos artículos, hemos creado una herramienta que nos permite crear y editar modelos de redes neuronales. Ahora es el momento de evaluar el uso potencial de la tecnología de Transfer Learning en ejemplos prácticos.
Artículo de introducción a los algoritmos de optimización (AO). Clasificación. En el artículo, intentaremos crear un banco de pruebas (un conjunto de funciones) que servirá en el futuro para comparar los AO entre sí, e incluso, quizás, para identificar el algoritmo más universal de todos los ampliamente conocidos.
A muchos les gustan todas las operaciones que hay detrás de las redes neuronales, pero pocos las entienden. En este artículo, intentaremos explicar en términos sencillos lo que ocurre detrás un perceptrón multinivel con conexión Feed Forward.
Continuamos analizando los algoritmos de aprendizaje no supervisado. Hoy hablaremos sobre el uso de autocodificadores en el entrenamiento de modelos recurrentes.
En el anterior artículo, vimos el algoritmo del autocodificador. Como cualquier otro algoritmo, tiene ventajas y desventajas. En la implementación original, el autocodificador se encarga de dividir los objetos de la muestra de entrenamiento tanto como sea posible. Y en este artículo, en cambio, hablaremos de cómo solucionar algunas de sus deficiencias.
Continuamos analizando los algoritmos de aprendizaje no supervisado. El lector podría preguntarse sobre la relevancia de las publicaciones recientes en el tema de las redes neuronales. En este nuevo artículo, retomaremos el uso de las redes neuronales.