La correcta comprensión de las cosas nos permite hacer más con menos esfuerzo. En este artículo, explicaré por qué es necesario ajustar la aplicación de la plantilla antes de que el servicio comience a interactuar realmente con el gráfico. Además, ¿qué tal si mejoramos el indicador del mouse para que podamos hacer más cosas con él?
En este artículo, se introducirá la herencia en nuestro código anterior. Se implementará un nuevo diseño de base de datos para brindar eficiencia. Además, se creará una clase de gestión de riesgos para abordar los cálculos de volumen.
Aquí vamos a desarrollar un script desde cero que simplifica la descarga de pantallas de impresión de transacciones para analizar entradas comerciales. Toda la información necesaria sobre una única operación se puede mostrar cómodamente en un gráfico con la posibilidad de dibujar diferentes marcos temporales.
Descubra cómo aprovechar MQL5 para pronosticar el S&P 500 con precisión, combinando análisis técnico clásico para lograr mayor estabilidad y algoritmos con principios probados en el tiempo para obtener información sólida del mercado.
El en presente artículo analizaremos las posibilidades de formar y proporcionar datos sobre el uso del factor de estacionalidad al negociar con spreads en el mercado Fórex.
Este artículo explora técnicas avanzadas de optimización de cartera utilizando Python y MQL5 con MetaTrader 5. Demuestra cómo desarrollar algoritmos para el análisis de datos, la asignación de activos y la generación de señales comerciales, enfatizando la importancia de la toma de decisiones basada en datos en la gestión financiera moderna y la mitigación de riesgos.
El presente artículo describe las propiedades de un modelo de heteroscedasticidad condicional no lineal (GARCH). Sobre esta base se construye el indicador iGARCH para predecir la volatilidad un paso por delante. Para estimar los parámetros del modelo se usará la biblioteca de análisis numérico ALGLIB.
Hoy vamos a continuar con la serie de artículos sobre la creación de un robot comercial en Python y MQL5. En esta ocasión, resolveremos el problema relacionado con la creación de un algoritmo comercial en Python.
Hoy vamos a continuar con la serie de artículos sobre la creación de un robot comercial en Python y MQL5. En el presente artículo, resolveremos el problema de la selección y el entrenamiento de modelos, la prueba de los mismos, la aplicación de la validación cruzada, la búsqueda en cuadrícula y el problema del ensamblaje de modelos.
En este artículo exploramos diferentes formas en que los vectores propios y los valores propios pueden aplicarse en el análisis exploratorio de datos para revelar relaciones únicas en los datos.
En este artículo repensaremos las cerraduras de código, transformándolas de mecanismos de protección en herramientas para resolver problemas complejos de optimización. Descubra el mundo de las cerraduras de código, no como simples dispositivos de seguridad, sino como inspiración para un nuevo enfoque de la optimización. Hoy crearemos toda una población de "cerraduras" en la que cada cerradura representará una solución única a un problema. A continuación, desarrollaremos un algoritmo que "forzará" estas cerraduras y hallará soluciones óptimas en ámbitos que van desde el aprendizaje automático hasta el desarrollo de sistemas comerciales.
El ángulo de ataque es una métrica citada a menudo cuya inclinación se entiende que está estrechamente relacionada con la fuerza de una tendencia predominante. Nos fijamos en cómo se utiliza y se entiende comúnmente y examinamos si hay cambios que podrían introducirse en la forma de medirlo en beneficio de un sistema comercial que lo ponga en uso.
El exponente de Hurst es una medida del grado de autocorrelación de una serie temporal a largo plazo. Se entiende que capta las propiedades a largo plazo de una serie temporal y, por tanto, tiene cierto peso en el análisis de series temporales, incluso fuera de las series temporales económicas/financieras. Sin embargo, nos centramos en sus posibles beneficios para los operadores, examinando cómo esta métrica podría combinarse con las medias móviles para crear una señal potencialmente sólida.
En este artículo, analizaremos un nuevo algoritmo de optimización de autor, el CTA (Comet Tail Algorithm), que se inspira en objetos espaciales únicos: los cometas y sus impresionantes colas que se forman al acercarse al Sol. Este algoritmo se basa en el concepto del movimiento de los cometas y sus colas, y está diseñado para encontrar soluciones óptimas en problemas de optimización.
Las estrategias que se basan en múltiples marcos de tiempo no se pueden probar en los Asesores Expertos ensamblados por defecto debido a la arquitectura de código MQL5 utilizada en las clases de ensamblaje. Exploramos una posible solución a esta limitación para las estrategias que buscan utilizar múltiples marcos temporales en un estudio de caso con la media móvil cuadrática.
Hoy hablaremos sobre un algoritmo de optimización único inspirado en la evolución del caparazón de las tortugas. El algoritmo TSEA emula la formación gradual de los sectores de piel queratinizada que representan soluciones óptimas a un problema. Las mejores soluciones se vuelven más "duras" y se encuentran más cerca de la superficie exterior, mientras que las menos exitosas permanecen "blandas" y se hallan en el interior. El algoritmo utiliza la clusterización de soluciones según su calidad y distancia, lo cual permite conservar las opciones menos acertadas y aporta flexibilidad y adaptabilidad.
El artículo analiza uno de los criterios de homogeneidad no paramétricos más famosos: el criterio de Smirnov. Asimismo, se consideran tanto datos modelo como cotizaciones reales, y se ofrece un ejemplo de construcción de un indicador de no estacionariedad (iSmirnovDistance).
Las redes neuronales recurrentes (RNNs, Recurrent Neural Networks) destacan por aprovechar la información del pasado para predecir acontecimientos futuros. Sus notables capacidades predictivas se han aplicado en diversos ámbitos con gran éxito. En este artículo, utilizaremos modelos RNN para predecir tendencias en el mercado de divisas, demostrando su potencial para mejorar la precisión de las predicciones en el comercio de divisas.
Las medias móviles son un indicador muy común que la mayoría de los operadores utilizan y comprenden. Exploramos posibles casos de uso menos comunes dentro de los Asesores Expertos disponibles en el Asistente de MQL5.
En este artículo analizaremos el método de componentes principales, una técnica de reducción de la dimensionalidad para el análisis de datos, y cómo podemos aplicar este utilizando valores propios y vectores. Como siempre, intentaremos desarrollar un prototipo de la clase de señales del asesor experto que se pueda utilizar en el Wizard MQL5.
En los mercados de divisas es muy difícil predecir la tendencia futura sin tener una idea del pasado. Muy pocos modelos de aprendizaje automático son capaces de hacer predicciones futuras considerando valores pasados. En este artículo, vamos a discutir cómo podemos utilizar modelos de inteligencia artificial clásicos (no de series temporales) para superar al mercado.
En este artículo demostramos cómo los modelos ocultos de Márkov entrenados con Python pueden integrarse en las aplicaciones de MetaTrader 5. Los modelos ocultos de Márkov son una potente herramienta estadística utilizada para modelar datos de series temporales, en los que el sistema modelado se caracteriza por estados no observables (ocultos). Una premisa fundamental de los modelos ocultos de Márkov es que la probabilidad de estar en un estado determinado en un momento concreto depende del estado del proceso en el intervalo de tiempo anterior.
De manera predeterminada, los datos del calendario económico no están disponibles para realizar pruebas con asesores expertos dentro del Probador de estrategias. Analizamos cómo las bases de datos podrían ayudar a solucionar esta limitación. Entonces, en este artículo exploramos cómo se pueden usar las bases de datos SQLite para archivar noticias del Calendario Económico, de modo que los Asesores Expertos ensamblados mediante un asistente puedan usarlas para generar señales comerciales.
Estas técnicas avanzadas de árboles de decisión potenciados por gradiente ofrecen un rendimiento y una flexibilidad superiores, lo que las hace ideales para el modelado financiero y el comercio algorítmico. Aprenda a aprovechar estas herramientas para optimizar sus estrategias comerciales, mejorar la precisión predictiva y obtener una ventaja competitiva en los mercados financieros.
Con el rápido desarrollo de la inteligencia artificial actual, los modelos de lenguaje (LLM) son una parte importante de la inteligencia artificial, por lo que deberíamos pensar en cómo integrar LLM potentes en nuestro trading algorítmico. Para la mayoría de las personas, es difícil ajustar estos poderosos modelos según sus necesidades, implementarlos localmente y luego aplicarlos al comercio algorítmico. Esta serie de artículos abordará paso a paso cómo lograr este objetivo.
En la segunda parte del artículo pasaremos a la aplicación práctica del algoritmo BSO, realizaremos tests con funciones de prueba y compararemos la eficacia de BSO con otros métodos de optimización.
Conforme hemos ido avanzado, hemos utilizado cada vez más instancias simultáneas de estrategias comerciales en un mismo asesor experto. Hoy intentaremos averiguar a cuántas instancias podemos llegar antes de encontrarnos con limitaciones de recursos.
En este artículo analizaremos un innovador método de optimización denominado BSO (Brain Storm Optimization), inspirado en el fenómeno natural de la tormenta de ideas. También discutiremos un nuevo enfoque de resolución de tareas de optimización multimodales que utiliza el método BSO y nos permite encontrar múltiples soluciones óptimas sin tener que determinar de antemano el número de subpoblaciones. En este artículo, también analizaremos los métodos de clusterización K-Means y K-Means++.
La regresión simbólica es una forma de regresión que parte de supuestos mínimos o nulos sobre cómo sería el modelo subyacente que traza los conjuntos de datos objeto de estudio. Aunque puede implementarse mediante Métodos Bayesianos o Redes Neuronales, veremos cómo una implementación con Algoritmos Genéticos puede ayudar a personalizar una clase de señal experta utilizable en el asistente MQL5.
La inferencia bayesiana es la adopción del teorema de Bayes para actualizar la hipótesis de probabilidad a medida que se dispone de nueva información. Esto intuitivamente se inclina hacia la adaptación en el análisis de series de tiempo, por lo que observamos cómo podríamos usarlo para crear clases personalizadas no solo para la señal sino también para la gestión de dinero y los trailing stops.
Anteriormente hemos evaluado la selección de un grupo de instancias de estrategias comerciales para mejorar el rendimiento cuando trabajan juntas solo durante el mismo periodo de tiempo en el que se han optimizado las instancias individuales. Veamos qué ocurre en el periodo forward.
En esta cuarta parte, revisamos los asesores expertos (EA) Simple Hedge y Simple Grid desarrollados anteriormente. Nuestro enfoque se centra en perfeccionar Simple Grid EA a través del análisis matemático y un enfoque de fuerza bruta, apuntando al uso óptimo de la estrategia. Este artículo profundiza en la optimización matemática de la estrategia, preparando el escenario para la futura exploración de la optimización basada en codificación en entregas posteriores.
El presente artículo pretende demostrar la aparición de regresiones espurias cuando se intenta aplicar el análisis de regresión a procesos no estacionarios utilizando la simulación de Montecarlo.
Las regresiones espurias ocurren cuando dos series de tiempo exhiben un alto grado de correlación puramente por casualidad, lo que conduce a resultados engañosos en el análisis de regresión. En tales casos, aunque las variables parezcan estar relacionadas, la correlación es casual y el modelo puede no ser confiable.
El artículo analiza un algoritmo BSA basado en el comportamiento de las aves, que se inspira en las interacciones colectivas de bandadas de aves en la naturaleza. Las diferentes estrategias de búsqueda de individuos en el BSA, que incluyen el cambio entre el comportamiento de vuelo, la vigilancia y la búsqueda de alimento, hacen que este algoritmo sea multidimensional. El algoritmo usa los principios del comportamiento de las bandadas, la comunicación, la adaptabilidad, el liderazgo y el seguimiento de las aves para encontrar con eficacia soluciones óptimas.
En este artículo, realizamos un estudio del algoritmo Boids, que se basa en ejemplos únicos del comportamiento de enjambre o bandada de animales. El algoritmo Boids, a su vez, ha servido de base para la creación de toda una clase de algoritmos agrupados bajo el nombre de "inteligencia de enjambre".
Búsqueda de arquitectura neuronal, un enfoque automatizado para determinar la configuración ideal de la red neuronal, puede ser una ventaja cuando se enfrentan muchas opciones y grandes conjuntos de datos de prueba. Analizamos cómo, cuando se combinan vectores propios, este proceso puede resultar aún más eficiente.
En este artículo presentamos la implementación de un algoritmo de selección de características descrito en un artículo académico titulado "FREL: Un algoritmo de selección de características estable", llamado Ponderación de características como aprendizaje regularizado basado en energía.
Es muy probable que no te hayas dado cuenta de que el modelado de las matrices era un tanto extraño, ya que no se indicaban filas y columnas, solo columnas. Esto resulta muy raro al leer un código que realiza factorizaciones de matrices. Si esperabas ver las filas y columnas indicadas, podrías haberte sentido bastante confundido al intentar implementar la factorización. Además, esa forma de modelar las matrices no es, ni de cerca, la mejor manera. Esto se debe a que, cuando modelamos matrices de esa forma, nos enfrentamos a ciertas limitaciones que nos obligan a usar otras técnicas o funciones que no serían necesarias si el modelado se realiza de manera más adecuada.
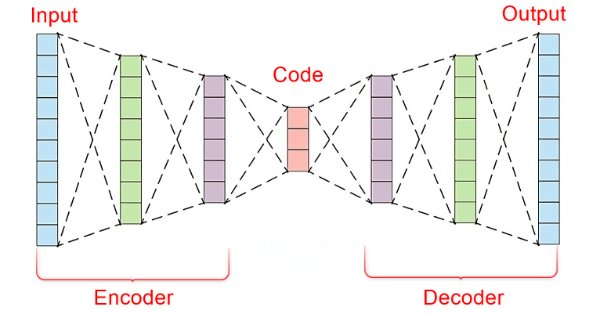
En el vertiginoso mundo de los mercados financieros, separar las señales significativas del ruido es crucial para operar con éxito. Al emplear sofisticadas arquitecturas de redes neuronales, los autocodificadores destacan a la hora de descubrir patrones ocultos en los datos de mercado, transformando datos ruidosos en información práctica. En este artículo, exploramos cómo los autocodificadores están revolucionando las prácticas de negociación, ofreciendo a los operadores una poderosa herramienta para mejorar la toma de decisiones y obtener una ventaja competitiva en los dinámicos mercados actuales.