Anteriormente hemos evaluado la selección de un grupo de instancias de estrategias comerciales para mejorar el rendimiento cuando trabajan juntas solo durante el mismo periodo de tiempo en el que se han optimizado las instancias individuales. Veamos qué ocurre en el periodo forward.
En esta cuarta parte, revisamos los asesores expertos (EA) Simple Hedge y Simple Grid desarrollados anteriormente. Nuestro enfoque se centra en perfeccionar Simple Grid EA a través del análisis matemático y un enfoque de fuerza bruta, apuntando al uso óptimo de la estrategia. Este artículo profundiza en la optimización matemática de la estrategia, preparando el escenario para la futura exploración de la optimización basada en codificación en entregas posteriores.
El algoritmo de Conformer que le mostraremos hoy se desarrolló para la previsión meteorológica, una esfera del saber que, por su constante variabilidad, puede compararse con los mercados financieros. El Conformer es un método completo que combina las ventajas de los modelos de atención y las ecuaciones diferenciales ordinarias.
Daremos un paseo por el arbitraje estadístico, buscaremos con Python símbolos de correlación y cointegración, haremos un indicador para el coeficiente de Pearson y haremos un EA para operar arbitraje estadístico con predicciones hechas con Python y modelos ONNX.
Tras optimizar una estrategia comercial, obtendremos conjuntos de parámetros en base a los cuales podremos crear varias instancias (ejemplares) de estrategias comerciales combinadas en un asesor experto. Antes lo hacíamos manualmente, pero ahora trataremos de automatizar el proceso
Una guía paso a paso para crear e implementar un algoritmo de trading automatizado en MQL5 basado en la estrategia de trading Fair Value Gap (FVG). Un tutorial detallado sobre la creación de un asesor experto que puede ser útil tanto para principiantes como para operadores experimentados.
Este artículo se centra en el aprovechamiento de los indicadores MetaTrader 5 incorporados para filtrar las señales fuera de tendencia. Avanzando desde el artículo anterior exploraremos cómo hacerlo utilizando código MQL5 para comunicar nuestra idea al programa final.
En este artículo, entenderemos por EA multidivisa un EA o robot comercial que utiliza indicadores ZigZag y Awesome Oscillator que filtran mutuamente sus señales.
Aprenda a crear indicadores personalizados utilizando MQL5. Este artículo introductorio le guiará a través de los fundamentos de la construcción de indicadores personalizados simples y demostrar un enfoque práctico para la codificación de diferentes indicadores personalizados para cualquier programador MQL5 nuevo en este interesante tema.
Las variables y los tipos de datos son temas muy importantes no solo en la programación MQL5, sino también en cualquier lenguaje de programación. Las variables y los tipos de datos de MQL5 pueden dividirse en simples y extendidos. Aquí veremos las variables y los tipos de datos extendidos. Ya analizamos los sencillos en un artículo anterior.
En este artículo, proporcionaremos otro indicador basado en la volatilidad llamado Chaikin Volatility. Entenderemos cómo construir un indicador personalizado después de identificar cómo se puede utilizar y construir. Compartiremos algunas estrategias sencillas que se pueden utilizar y luego las pondremos a prueba para entender cuál puede ser mejor.
Desarrollar un robot de trading basado en aprendizaje automático: Una guía detallada. El primer artículo de la serie trata de la recogida y preparación de datos y características. El proyecto se ejecuta utilizando el lenguaje de programación y las librerías Python, así como la plataforma MetaTrader 5.
En este artículo, le presentamos el algoritmo GTGAN, introducido en enero de 2024 para resolver problemas complejos de disposición arquitectónica con restricciones gráficas.
Los algoritmos de agrupamiento en el aprendizaje automático son importantes algoritmos de aprendizaje no supervisado que pueden dividir los datos originales en grupos con observaciones similares. Utilizando estos grupos, puede analizar el mercado de un grupo específico, buscar los grupos más estables utilizando nuevos datos y hacer inferencias causales. El artículo propone un método original de agrupación de series temporales en Python.
En la tercera parte, volveremos a los Asesores Expertos Simple Hedge y Simple Grid que hemos desarrollado anteriormente. En esta ocasión, mejoraremos el Simple Hedge Expert Advisor usando el análisis matemático y el enfoque de fuerza bruta para utilizar de manera óptima la estrategia. Este artículo profundizará en la optimización matemática de estrategias, sentando las bases para futuras investigaciones sobre la optimización basada en códigos de partes posteriores.
En este artículo hablaremos sobre el paradigma de la POO y su aplicación en el código MQL5. Este será el segundo artículo de la serie. En él aprenderemos las características de la programación orientada a objetos y analizaremos ejemplos prácticos. La última vez escribimos un Asesor Experto basado en la Acción del Precio (Price Action) utilizando el indicador EMA y datos de velas. Ahora convertiremos su código procedimental en un código orientado a objetos.
En este artículo vamos a discutir en detalle cómo escribir una clase de gestor de riesgos para el comercio manual a partir de cero. Esta clase también puede utilizarse como clase base para que la hereden los traders algorítmicos que utilizan programas automatizados.
La fusión espacio-temporal, que utiliza métricas espaciales y temporales en la modelización de datos, es útil sobre todo en teledetección y otras muchas actividades visuales para comprender mejor nuestro entorno. Gracias a un artículo publicado, adoptamos un enfoque novedoso en su uso examinando su potencial para los comerciantes.
Hoy continuaremos un experimento cuyo objetivo es investigar el comportamiento de los algoritmos de optimización basados en poblaciones en el contexto de su capacidad para abandonar eficazmente los mínimos locales cuando la diversidad de la población es baja y alcanzar los máximos globales. Resultados del estudio.
En el artículo anterior, nos familiarizamos con uno de los métodos para detectar objetos en una imagen. Sin embargo, el procesamiento de una imagen estática se diferencia ligeramente del trabajo con series temporales dinámicas que incluyen la dinámica de los precios que hemos analizado. En este artículo les presentaré un método de detección de objetos en vídeo que resulta algo más cercano al problema que estamos resolviendo.
En este artículo, intentaremos desarrollar nuestra propia estrategia de trading. Toda estrategia de trading debe basarse en algún tipo de ventaja estadística. Además, esta ventaja debería existir durante mucho tiempo.
En trabajos anteriores, siempre evaluábamos el estado actual del entorno. Al mismo tiempo, la dinámica de los cambios en los indicadores siempre permaneció «entre bastidores». En este artículo quiero presentarle un algoritmo que permite evaluar el cambio directo de los datos entre 2 estados ambientales sucesivos.
En las partes anteriores, el Asesor Experto (EA) en desarrollo sólo podía utilizar un tamaño de posición fijo para operar. Esto es aceptable para las pruebas, pero no es aconsejable cuando se opera en una cuenta real. Hagamos posible el comercio utilizando tamaños de posición variables.
Este artículo trata el tema del emparejamiento en la inferencia causal. El emparejamiento se usa para emparejar observaciones similares en un conjunto de datos. Esto es necesario para identificar correctamente los efectos causales, eliminando el sesgo. Hoy explicaremos cómo esto ayuda a crear sistemas comerciales basados en el aprendizaje automático que se vuelven más robustos con nuevos datos en los que no se ha entrenado. El papel principal lo asignaremos a la puntuación de propensión, ampliamente utilizada en la inferencia causal.
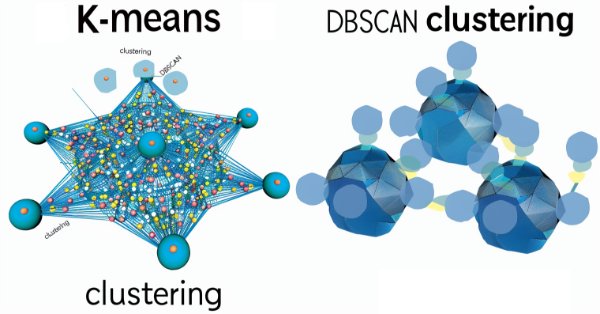
El agrupamiento basado en densidad para aplicaciones con ruido (DBSCAN) es una forma no supervisada de agrupar datos que apenas requiere parámetros de entrada, salvo solo 2, lo cual, en comparación con otros enfoques como k-means, es una ventaja. Profundizamos en cómo esto podría ser constructivo para probar y eventualmente operar con Asesores Expertos montados por Wizard MQL5.
Tras empezar a desarrollar un EA multidivisa, ya hemos obtenido algunos resultados y hemos conseguido realizar varias iteraciones de mejora del código. Sin embargo, nuestro EA fue incapaz de trabajar con órdenes pendientes y reanudar la operación después del reinicio del terminal. Añadamos estas características.
Este artículo está dirigido a principiantes y desarrolladores avanzados de MQL5. Proporciona un fragmento de código para definir y limitar los indicadores generadores de señales a tendencias en plazos superiores. De este modo, los operadores pueden mejorar sus estrategias incorporando una perspectiva de mercado más amplia, lo que da lugar a señales de negociación potencialmente más sólidas y fiables.
ONNX es una gran herramienta para la integración de código complejo de IA entre diferentes plataformas, es una gran herramienta que viene con algunos desafíos que uno debe abordar para obtener el máximo provecho de ella, En este artículo se discuten los problemas comunes que podría enfrentar y cómo mitigarlos.
En este artículo, le propongo abordar la creación de una estrategia comercial desde una perspectiva diferente. Hoy no pronosticaremos los movimientos futuros de los precios, sino que trataremos de construir un sistema comercial basado en el análisis de datos históricos.
Las máquinas de vectores de soporte clasifican los datos en función de clases predefinidas explorando los efectos de aumentar su dimensionalidad. Se trata de un método de aprendizaje supervisado bastante complejo dado su potencial para tratar datos multidimensionales. Para este artículo consideramos cómo su implementación muy básica de datos bidimensionales puede hacerse más eficientemente con el polinomio de Newton al clasificar precio-acción.
Desarrollando el tema del artículo anterior sobre el multibot, hemos decidido crear una plantilla más flexible y funcional, que tenga grandes posibilidades, y que se pueda utilizar eficazmente en freelance, además de como base para desarrollar asesores de divisa y periodo múltiple con posibilidad de integración con soluciones externas.
En este artículo analizaremos los métodos de reducción de la dimensionalidad y su aplicación en el entorno comercial MQL5. En concreto, exploraremos los matices del análisis discriminante lineal (LDA) y el análisis de componentes principales (PCA) y analizaremos su impacto en el desarrollo de estrategias y el análisis de mercados.
El polinomio de Newton, que crea ecuaciones cuadráticas a partir de un conjunto de unos pocos puntos, es un enfoque arcaico pero interesante para observar una serie temporal. En este artículo tratamos de explorar qué aspectos podrían ser de utilidad para los operadores desde este enfoque, así como abordar sus limitaciones.
En nuestros modelos, a menudo utilizamos varios algoritmos de atención. Y, probablemente, lo más frecuente es utilizar transformadores. Su principal desventaja es la necesidad de recursos. En este artículo, estudiaremos un nuevo algoritmo que puede ayudar a reducir los costes informáticos sin perder calidad.
Este artículo continúa con el tema de la predicción del próximo movimiento de los precios. Le invito a conocer la arquitectura del Transformador Multifuturo. Su idea principal es descomponer la distribución multimodal del futuro en varias distribuciones unimodales, lo que permite simular eficazmente varios modelos de interacción entre agentes en la escena.
En este artículo examinaremos los sistemas comerciales que utilizan un concepto muy importante de los mercados financieros: la volatilidad. Asimismo, estudiaremos un sistema comercial basado en el Canal de Keltner, incluyendo su implementación en código y sus pruebas con varios activos.
En este artículo, discutiremos cómo utilizar el coeficiente generalizado de Hurst y la prueba del coeficiente de varianza para analizar el comportamiento de las series de precios en MQL5.
Los modelos que creamos son cada vez más grandes y complejos. Esto aumenta los costes no sólo de su formación, sino también de su funcionamiento. Sin embargo, el tiempo necesario para tomar una decisión suele ser crítico. A este respecto, consideremos los métodos para optimizar el rendimiento del modelo sin pérdida de calidad.
En este artículo, examinaremos la teoría de la inferencia causal utilizando el aprendizaje automático, así como la implementación del enfoque personalizado en Python. La inferencia causal y el pensamiento causal tienen sus raíces en la filosofía y la psicología y desempeñan un papel importante en nuestra comprensión de la realidad.