En este artículo, profundizaremos en la preparación detallada de nuestro indicador para el desarrollo del Asesor Experto (EA). Nuestro debate abarcará mejoras adicionales en la versión actual del indicador para mejorar su precisión y funcionalidad. Además, introduciremos nuevas características que marcan puntos de salida, abordando una limitación de la versión anterior, que solo identificaba puntos de entrada.
En este artículo, vamos a discutir cómo podemos construir Asesores Expertos capaces de seleccionar de forma autónoma y cambiar las estrategias de negociación en función de las condiciones imperantes en el mercado. Aprenderemos sobre las cadenas de Markov y cómo pueden sernos útiles como operadores algorítmicos.
Una forma de mejorar la eficacia del proceso de aprendizaje y la convergencia de los modelos es mejorar los métodos de optimización. Adam-mini es un método de optimización adaptativa desarrollado para mejorar el algoritmo Adam básico.
En este artículo, hablaremos sobre el uso de transformaciones espacio-temporales para predecir el próximo movimiento de los precios de manera eficaz. Para mejorar la precisión de la predicción numérica en el STNN, hemos propuesto un mecanismo de atención continua que permite al modelo considerar en mayor medida aspectos importantes de los datos.
Este artículo explora una estrategia comercial que integra el análisis discriminante lineal (Linear Discriminant Analysis, LDA) con las Bandas de Bollinger, aprovechando las predicciones de zonas categóricas para obtener señales estratégicas de entrada al mercado.
La Tasa de Aprendizaje, es un tamaño de paso hacia un objetivo de entrenamiento en muchos procesos de entrenamiento de algoritmos de aprendizaje automático. Examinamos el impacto que sus múltiples horarios y formatos pueden tener en el rendimiento de una Red Generativa Adversarial, un tipo de red neuronal que ya habíamos examinado en un artículo anterior.
Continuamos la conversación sobre el uso de la representación lineal por partes de las series temporales iniciada en el artículo anterior. Y hoy hablaremos de la combinación de este método con otros enfoques del análisis de series temporales para mejorar la calidad de la previsión de la tendencia del movimiento de precios.
El libro de órdenes —Depth of Market— es, sin duda, un elemento muy relevante para la ejecución de operaciones rápidas, especialmente en algoritmos de alta frecuencia (HFT). En esta serie de artículos, exploraremos este tipo de evento comercial que podemos obtener a través del bróker en muchos de los símbolos negociados. Empezaremos con un indicador en el que se pueden configurar la paleta de colores, la posición y el tamaño del histograma que se mostrará directamente en el gráfico. También veremos cómo generar eventos BookEvent para probar el indicador en condiciones específicas. Otros posibles temas que trataremos en artículos futuros son el almacenamiento de estas distribuciones de precios y las formas de utilizarlas en el simulador de estrategias.
Este artículo es algo distinto de los anteriores de esta serie. En él, hablaremos de una representación alternativa de las series temporales. La representación lineal por partes de series temporales es un método de aproximación de una serie temporal usando funciones lineales en intervalos pequeños.
Un reto importante es la gestión de varias ventanas de gráficos del mismo par que ejecutan el mismo programa con diferentes funciones. Vamos a discutir cómo consolidar varias integraciones en un programa principal. Además, compartiremos ideas sobre la configuración del programa para imprimir en un diario y comentar el éxito de la emisión de señales en la interfaz de gráficos. Encontrará más información en este artículo a medida que avancemos en la serie de artículos.
Al estudiar las distintas arquitecturas de construcción de modelos, prestamos poca atención al proceso de entrenamiento de los mismos. En este artículo intentaremos rellenar ese vacío.
Este artículo aborda preguntas comunes de principiantes en los foros de MQL5 y demuestra soluciones prácticas. Aprenda a realizar tareas esenciales como comprar y vender, obtener precios de velas y administrar aspectos del trading automatizado como límites de trading, períodos de trading y umbrales de ganancias/pérdidas. Obtenga orientación paso a paso para mejorar su comprensión e implementación de estos conceptos en MQL5.
Extraer y combinar eficazmente las dependencias a largo plazo y las características a corto plazo sigue siendo una tarea importante en el análisis de series temporales. Para crear modelos predictivos precisos y fiables deberemos comprender e integrar estos adecuadamente.
En este artículo, exploraremos una forma interesante y diferente de crear un indicador en MQL5. En lugar de centrarnos en una tendencia o patrón gráfico, el objetivo será gestionar nuestras propias posiciones, incluyendo las entradas y salidas parciales. Utilizaremos intensivamente matrices dinámicas y algunas funciones comerciales (Trade) relacionadas con el historial de transacciones y las posiciones abiertas para indicar en el gráfico dónde se llevaron a cabo estas operaciones.
Este artículo describe los pasos para crear un Asesor Experto (EA) que aproveche las rupturas de precios después de los períodos de consolidación. Al identificar rangos de consolidación y establecer niveles de ruptura, los operadores pueden automatizar sus decisiones comerciales basándose en esta estrategia. El Asesor Experto tiene como objetivo proporcionar puntos de entrada y salida claros y evitar rupturas falsas.
Seguimos automatizando los pasos que antes realizábamos manualmente. Esta vez regresaremos a la automatización de la segunda etapa, es decir, a la selección del grupo óptimo de instancias únicas de estrategias comerciales, complementándola con la posibilidad de considerar los resultados de las instancias en el periodo anterior.
Los modelos basados en la arquitectura de transformadores demuestran una gran eficacia, pero su uso se complica por el elevado coste de los recursos tanto en la fase de formación como durante el funcionamiento. En este artículo, propongo familiarizarse con los algoritmos que permiten reducir el uso de memoria de tales modelos.
Ahora nuestro EA utiliza una base de datos para recuperar las cadenas de inicialización de instancias individuales de estrategias comerciales. Sin embargo, la base de datos es bastante voluminosa y contiene mucha información innecesaria para el funcionamiento real del asesor experto. Vamos a intentar que el EA funcione sin conexión obligatoria a la base de datos.
Continuamos nuestra inmersión en la teoría del caos en los mercados financieros: hoy analizaremos su aplicabilidad al análisis de divisas y otros activos.
El asesor experto que estamos desarrollando debería mostrar buenos resultados al negociar con diferentes brókeres. Pero hasta ahora hemos usado las cotizaciones de la cuenta demo de MetaQuotes para las pruebas. Veamos si nuestro asesor experto está listo para trabajar en una cuenta comercial con cotizaciones diferentes a las utilizadas durante las pruebas y la optimización.
En la primera parte de este artículo, nos sumergiremos en el mundo de las reacciones químicas y descubriremos un nuevo enfoque de la optimización. La optimización de reacciones químicas (Chemical Reaction Optimization, CRO) utiliza principios derivados de las leyes de la termodinámica para lograr resultados eficientes. Desvelaremos los secretos de la descomposición, la síntesis y otros procesos químicos que se convirtieron en la base de este innovador método.
Aquí vamos a desarrollar un script desde cero que simplifica la descarga de pantallas de impresión de operaciones para analizar las entradas de operaciones. Toda la información necesaria sobre una operación debe mostrarse cómodamente en un gráfico con la posibilidad de dibujar distintos plazos.
Al acercarnos gradualmente un asesor experto listo, debemos prestar atención a las cuestiones que son secundarias en la etapa de prueba de la estrategia comercial, pero que se vuelven importantes al pasar a la negociación real.
¿Puede aplicarse la teoría del caos a los mercados financieros? En este artículo analizaremos en qué se diferencian la teoría clásica del caos y los sistemas caóticos del concepto propuesto por Bill Williams.
Al trabajar con series temporales, siempre utilizamos los datos de origen en su secuencia histórica. Pero, ¿es ésta la mejor opción? Existe la opinión de que cambiar la secuencia de los datos de entrada mejorará la eficacia de los modelos entrenados. En este artículo te invito a conocer uno de los métodos para optimizar la secuencia de entrada.
Aquí entenderemos por qué necesitamos utilizar la función iSpread. Al mismo tiempo, comprenderemos cómo el sistema nos informa del tiempo restante de la barra cuando no hay ticks disponibles para hacerlo. El contenido presentado aquí tiene como único propósito la enseñanza y la didáctica. En ningún caso debe considerarse una aplicación cuya finalidad no sea el aprendizaje y el estudio de los conceptos mostrados.
En este artículo, aprenderás a desarrollar un indicador de Order Blocks basado en el volumen de la profundidad de mercado y a optimizarlo mediante buffers para mejorar su precisión. Concluimos esta fase del proyecto y nos preparamos para las siguientes, en las que implementaremos una clase de gestión de riesgos y un bot de trading que aprovechará las señales generadas por el indicador.
En este artículo, analizaremos las modificaciones necesarias para que el sistema de repetición/simulación pueda operar de manera más eficiente y segura. También mostraré algo de interés para quienes deseen aprovechar al máximo el uso de clases. Además, abordaré un problema específico de MQL5 que reduce el rendimiento del código al trabajar con clases y explicaré cómo resolverlo.
En este artículo, continuamos la aplicación de los planteamientos del modelo ATFNet, que combina de forma adaptativa los resultados de 2 bloques (frecuencia y tiempo) dentro de la predicción de series temporales.
Los autores del método FreDF confirmaron experimentalmente la ventaja de la previsión combinada en los ámbitos de la frecuencia y el tiempo. Sin embargo, el uso del hiperparámetro de peso no es óptimo para series temporales no estacionarias. En este artículo, nos familiarizaremos con el método de combinación adaptativa de previsiones en los ámbitos de la frecuencia y el tiempo.
La correcta comprensión de las cosas nos permite hacer más con menos esfuerzo. En este artículo, explicaré por qué es necesario ajustar la aplicación de la plantilla antes de que el servicio comience a interactuar realmente con el gráfico. Además, ¿qué tal si mejoramos el indicador del mouse para que podamos hacer más cosas con él?
En este artículo, se introducirá la herencia en nuestro código anterior. Se implementará un nuevo diseño de base de datos para brindar eficiencia. Además, se creará una clase de gestión de riesgos para abordar los cálculos de volumen.
Aquí vamos a desarrollar un script desde cero que simplifica la descarga de pantallas de impresión de transacciones para analizar entradas comerciales. Toda la información necesaria sobre una única operación se puede mostrar cómodamente en un gráfico con la posibilidad de dibujar diferentes marcos temporales.
El gestor de riesgos que hemos desarrollado en los últimos artículos solo contiene funciones básicas. Hoy trataremos de analizar sus posibles formas de desarrollo, lo que nos permitirá aumentar los resultados comerciales sin interferir con la lógica de las estrategias de negociación.
Descubra cómo aprovechar MQL5 para pronosticar el S&P 500 con precisión, combinando análisis técnico clásico para lograr mayor estabilidad y algoritmos con principios probados en el tiempo para obtener información sólida del mercado.
Hoy vamos a continuar con la serie de artículos sobre la creación de un robot comercial en Python y MQL5. En esta ocasión, resolveremos el problema relacionado con la creación de un algoritmo comercial en Python.
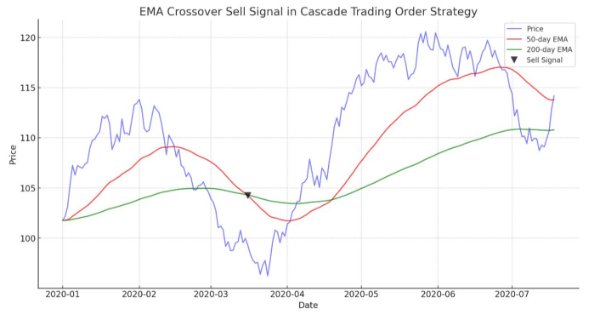
El artículo guía en la demostración de un algoritmo automatizado basado en cruces de EMA para MetaTrader 5. Información detallada sobre todos los aspectos de la demostración de un Asesor Experto en MQL5 y su prueba en MetaTrader 5, desde el análisis del comportamiento del rango de precios hasta la gestión de riesgos.
Ya hemos puesto en marcha la primera fase del proceso de optimización automatizada. Para distintos símbolos y marcos temporales, realizamos la optimización utilizando varios criterios y almacenamos información sobre los resultados de cada pasada en la base de datos. Ahora vamos a seleccionar los mejores grupos de conjuntos de parámetros de entre los encontrados en la primera etapa.
Mejorar el panel GUI de MQL5 con funciones dinámicas puede mejorar significativamente la experiencia comercial de los usuarios. Al incorporar elementos interactivos, efectos de desplazamiento y actualizaciones de datos en tiempo real, el panel se convierte en una herramienta poderosa para los traders modernos.
Ya disponemos de un cierto mecanismo de control de la reducción en el asesor experto que estamos desarrollando. Pero este es de naturaleza probabilística, ya que se basa en resultados de pruebas sobre los datos históricos de los precios. Por lo tanto, las reducciones, aunque con una probabilidad pequeña, pueden superar a veces los valores máximos previstos. Vamos a intentar añadir un mecanismo que garantice el nivel de reducción especificado.