

RestAPIを統合したMQL5強化学習エージェントの開発(第3回):MQL5で自動手番とテストスクリプトを作成する
母集団最適化アルゴリズム:2進数遺伝的アルゴリズム(BGA)(第2回)

母集団最適化アルゴリズム:2進数遺伝的アルゴリズム(BGA)(第1回)

ニューラルネットワークが簡単に(第71回):目標条件付き予測符号化(GCPC)

ニューラルネットワークが簡単に(第70回):閉形式方策改善演算子(CFPI)

ニューラルネットワークが簡単に(第69回):密度に基づく行動方策の支持制約(SPOT)
GMDH (The Group Method of Data Handling):MQL5で組合せアルゴリズムを実装する

知っておくべきMQL5ウィザードのテクニック(第16回):固有ベクトルによる主成分分析
ONNX統合の課題を克服する
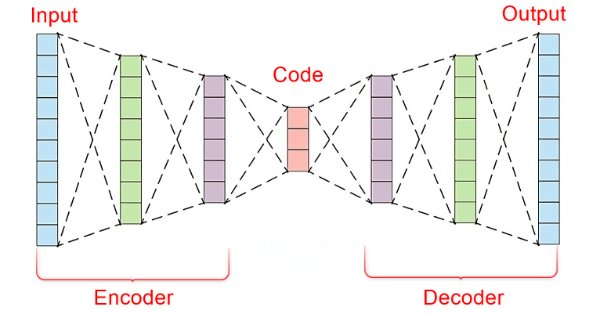
データサイエンスと機械学習(第22回):オートエンコーダニューラルネットワークを活用してノイズからシグナルへと移行することで、よりスマートな取引を実現する

知っておくべきMQL5ウィザードのテクニック(第15回):ニュートンの多項式を用いたサポートベクトルマシン
GMDH (The Group Method of Data Handling):MQL5で多層反復アルゴリズムを実装する

知っておくべきMQL5ウィザードのテクニック(第14回):STFによる多目的時系列予測

データサイエンスと機械学習(第21回):ニューラルネットワークと最適化アルゴリズムの解明

MQL5入門(第6部):MQL5における配列関数の入門ガイド (II)
Pythonを使用したEA用ディープラーニングONNXモデルの季節性フィルタと期間
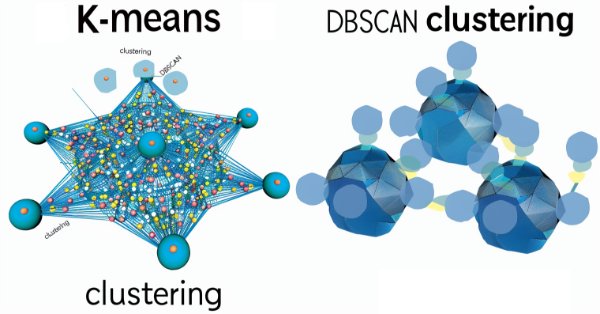
知っておくべきMQL5ウィザードのテクニック(第13回):ExpertSignalクラスのためのDBSCAN

不一致問題(Disagreement Problem):AIにおける複雑性の説明可能性を深く掘り下げる

Pythonを使用した深層学習GRUモデルとEAによるONNX、GRUとLSTMモデルの比較

MQL5入門(第5部):MQL5における配列関数の入門ガイド

ニューラルネットワークが簡単に(第68回):オフライン選好誘導方策最適化
RestAPIを統合したMQL5強化学習エージェントの開発(第1回):MQL5でRestAPIを使用する方法

母集団最適化アルゴリズム:微小人工免疫系(Micro-AIS)
母集団最適化アルゴリズム:細菌採餌最適化-遺伝的アルゴリズム(BFO-GA)

母集団最適化アルゴリズム:進化戦略、(μ,λ)-ESと(μ+λ)-ES
PythonとMetaTrader5 Pythonパッケージを使用した深層学習による予測と注文とONNXモデルファイル

知っておくべきMQL5ウィザードのテクニック(第11回):ナンバーウォール

知っておくべきMQL5ウィザードのテクニック(第10回):型破りなRBM

float16およびfloat8形式のONNXモデルを扱う
時系列マイニングのためのデータラベル(第6回):ONNXを使用したEAへの応用とテスト

データサイエンスと機械学習(第18回):市場複雑性を極める戦い - 打ち切りSVD v.s. NMF

時系列マイニングのためのデータラベル(第5回):ソケットを使用したEAへの応用とテスト

データサイエンスと機械学習(第20回):アルゴリズム取引の洞察、MQL5でのLDAとPCAの対決

データサイエンスと機械学習(第19回):AdaBoostでAIモデルをパワーアップ

MQL5入門(第4部):構造体、クラス、時間関数をマスターする

MQL5入門(第3部):MQL5のコア要素をマスターする

MQL5入門(第2部):定義済み変数、共通関数、制御フロー文の操作

母集団最適化アルゴリズム:スマート頭足類(SC、Smart Cephalopod)を使用した変化する形状、確率分布の変化とテスト
