
MQL5中的范畴论(第23部分):对双重指数移动平均的不同看法
MQL5中的范畴论(第22部分):对移动平均的不同看法

MQL5中的范畴论(第21部分):使用LDA的自然变换
神经网络变得轻松(第五十五部分):对比内在控制(CIC)
将ML模型与策略测试器集成(结论):实现价格预测的回归模型
MQL5中的范畴论(第20部分):自我注意的迂回与转换

MQL5 中的范畴论 (第 17 部分):函子与幺半群

神经网络变得轻松(第五十四部分):利用随机编码器(RE3)进行高效研究
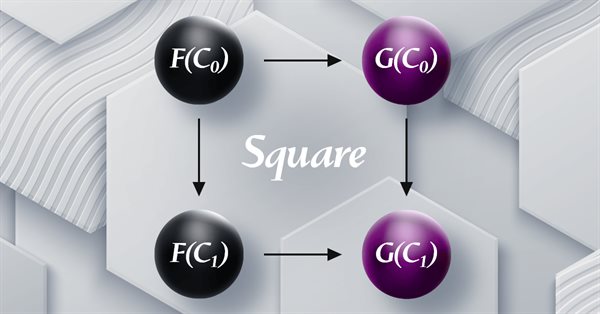
MQL5中的范畴论(第19部分):自然性四边形归纳法
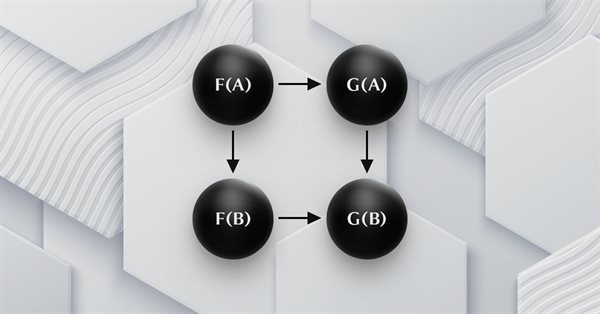
MQL5中的范畴论(第18部分):自然性四边形
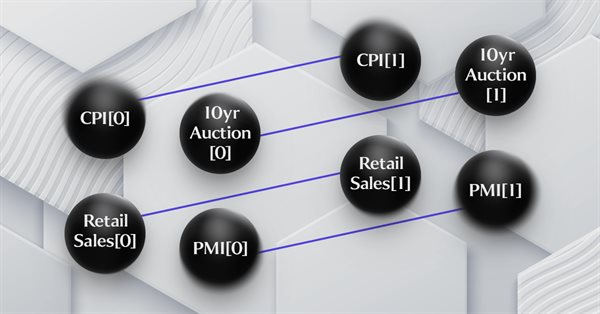
MQL5 中的范畴论 (第 16 部分):多层感知器函子

神经网络变得轻松(第五十三部分):奖励分解

神经网络变得轻松(第五十二部分):研究乐观情绪和分布校正

在 ONNX 模型中使用 float16 和 float8 格式

MQL5 中的范畴论 (第 15 部分):函子与图论

时间序列挖掘的数据标签(第4部分):使用标签数据的可解释性分解

神经网络变得轻松(第五十一部分):行为-指引的扮演者-评论者(BAC)

MQL5 中的范畴论 (第 14 部分):线性序函子

将您自己的LLM集成到EA中(第1部分):硬件和环境部署

掌握ONNX:MQL5交易者的游戏规则改变者

神经网络变得轻松(第五十部分):软性扮演者-评价者(模型优化)

时间序列挖掘的数据标签(第3部分):使用标签数据的示例

MQL5 中的范畴论 (第 13 部分):数据库制程的日历事件

神经网络变得轻松(第四十九部分):软性扮演者-评价者
时间序列挖掘的数据标签(第2部分):使用Python制作带有趋势标记的数据集

时间序列挖掘的数据标签(第1部分):通过EA操作图制作具有趋势标记的数据集

神经网络变得轻松(第四十八部分):降低 Q-函数高估的方法
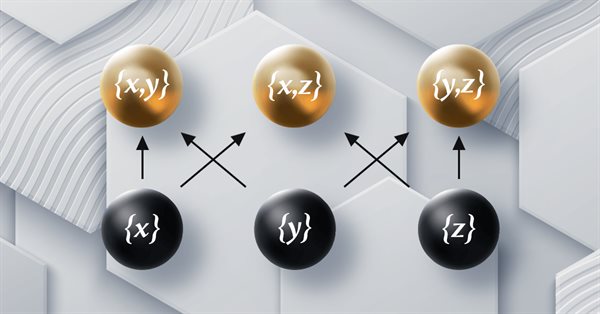
MQL5 中的范畴论 (第 12 部分):秩序(Orders)

神经网络变得轻松(第四十七部分):连续动作空间

神经网络变得轻松(第四十六部分):条件导向目标强化学习(GCRL)

MQL5 中的范畴论 (第 9 部分):幺半群(Monoid)— 动作
神经网络变得轻松(第四十五部分):训练状态探索技能
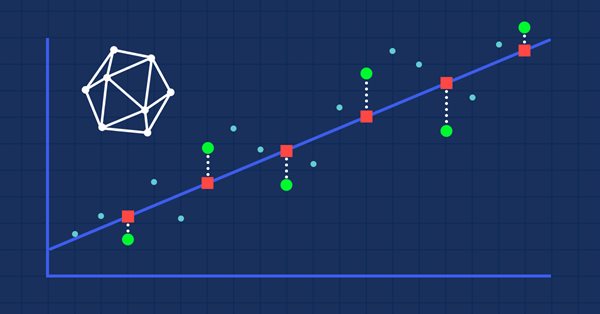
利用回归衡量度评估 ONNX 模型
神经网络变得轻松(第四十四部分):动态学习技能
时间序列的频域表示:功率谱

神经网络变得轻松(第四十三部分):无需奖励函数精通技能

神经网络变得轻松(第四十二部分):模型拖延症、原因和解决方案

神经网络变得轻松(第四十部分):在大数据上运用 Go-Explore
