Dieser Artikel beschreibt die Implementierung von automatischen Zügen im Tic-Tac-Toe-Spiel in Python, integriert mit MQL5-Funktionen und Unit-Tests. Das Ziel ist es, die Interaktivität des Spiels zu verbessern und die Zuverlässigkeit des Systems durch Tests in MQL5 zu gewährleisten. Die Präsentation umfasst die Entwicklung der Spiellogik, die Integration und praktische Tests und schließt mit der Erstellung einer dynamischen Spielumgebung und eines robusten integrierten Systems.
In diesem Artikel befassen wir uns mit dem binären genetischen Algorithmus (BGA), der die natürlichen Prozesse modelliert, die im genetischen Material von Lebewesen in der Natur ablaufen.
In diesem Artikel werden wir verschiedene Methoden untersuchen, die in binären genetischen und anderen Populationsalgorithmen verwendet werden. Wir werden uns die Hauptkomponenten des Algorithmus, wie Selektion, Crossover und Mutation, und ihre Auswirkungen auf die Optimierung ansehen. Darüber hinaus werden wir Methoden der Datendarstellung und ihre Auswirkungen auf die Optimierungsergebnisse untersuchen.
In früheren Artikeln haben wir die Decision-Transformer-Methode und mehrere davon abgeleitete Algorithmen besprochen. Wir haben mit verschiedenen Zielsetzungsmethoden experimentiert. Während der Experimente haben wir mit verschiedenen Arten der Zielsetzung gearbeitet. Die Studie des Modells über die frühere Trajektorie blieb jedoch immer außerhalb unserer Aufmerksamkeit. In diesem Artikel. Ich möchte Ihnen eine Methode vorstellen, die diese Lücke füllt.
In diesem Artikel werden wir uns mit der Theorie des Kausalschlusses unter Verwendung von maschinellem Lernen sowie mit der Implementierung des nutzerdefinierten Ansatzes in Python befassen. Kausalschlüsse und kausales Denken haben ihre Wurzeln in der Philosophie und Psychologie und spielen eine wichtige Rolle für unser Verständnis der Realität.
In diesem Artikel werden wir uns mit einem Algorithmus vertraut machen, der geschlossene Operatoren zur Verbesserung der Politik verwendet, um die Aktionen des Agenten im Offline-Modus zu optimieren.
Beim Offline-Lernen verwenden wir einen festen Datensatz, der die Umweltvielfalt nur begrenzt abdeckt. Während des Lernprozesses kann unser Agent Aktionen generieren, die über diesen Datensatz hinausgehen. Wenn es keine Rückmeldungen aus der Umwelt gibt, wie können wir dann sicher sein, dass die Bewertungen solcher Maßnahmen korrekt sind? Die Beibehaltung der Agentenpolitik innerhalb des Trainingsdatensatzes ist ein wichtiger Aspekt, um die Zuverlässigkeit des Trainings zu gewährleisten. Darüber werden wir in diesem Artikel sprechen.
In diesem Artikel setzen wir unsere Untersuchung der Algorithmenfamilie Group Method of Data Handling mit der Implementierung des Kombinatorischen Algorithmus und seiner verfeinerten Variante, dem Kombinatorischen Selektiven Algorithmus in MQL5 fort.
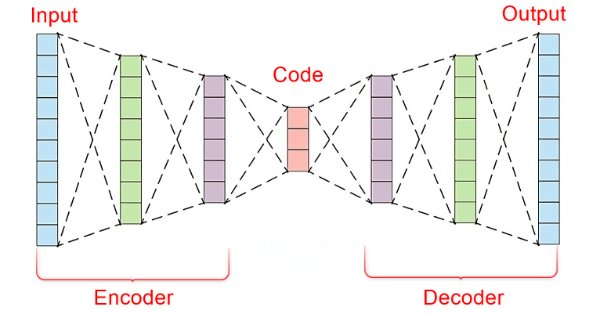
In der schnelllebigen Welt der Finanzmärkte ist es für den erfolgreichen Handel entscheidend, aussagekräftige Signale vom Rauschen zu unterscheiden. Durch den Einsatz hochentwickelter neuronaler Netzwerkarchitekturen sind Autocoder hervorragend in der Lage, verborgene Muster in Marktdaten aufzudecken und verrauschte Daten in verwertbare Erkenntnisse umzuwandeln. In diesem Artikel gehen wir der Frage nach, wie Autoencoders die Handelspraktiken revolutionieren und Händlern ein leistungsfähiges Werkzeug an die Hand geben, um die Entscheidungsfindung zu verbessern und sich auf den dynamischen Märkten von heute einen Wettbewerbsvorteil zu verschaffen.
Die Hauptkomponentenanalyse, ein Verfahren zur Verringerung der Dimensionalität in der Datenanalyse, wird in diesem Artikel untersucht, und es wird gezeigt, wie sie mit Eigenwerten und Vektoren umgesetzt werden kann. Wie immer streben wir die Entwicklung eines Prototyps einer Experten-Signal-Klasse an, die im MQL5-Assistenten verwendet werden kann.
ONNX ist ein großartiges Werkzeug für die Integration von komplexem KI-Code zwischen verschiedenen Plattformen. Es ist ein großartiges Werkzeug, das einige Herausforderungen mit sich bringt, die man angehen muss, um das Beste daraus zu machen.
Support-Vektor-Maschinen klassifizieren Daten auf der Grundlage vordefinierter Klassen, indem sie die Auswirkungen einer Erhöhung der Dimensionalität untersuchen. Es handelt sich um eine überwachte Lernmethode, die angesichts ihres Potenzials, mit mehrdimensionalen Daten umzugehen, ziemlich komplex ist. In diesem Artikel wird untersucht, wie die sehr einfache Implementierung von 2-dimensionalen Daten mit dem Newton'schen Polynom bei der Klassifizierung von Preis-Aktionen effizienter durchgeführt werden kann.
Die räumlich-zeitliche Fusion, bei der sowohl räumliche als auch zeitliche Metriken zur Modellierung von Daten verwendet werden, ist vor allem bei der Fernerkundung und einer Vielzahl anderer visueller Aktivitäten nützlich, um ein besseres Verständnis unserer Umgebung zu erlangen. Dank eines veröffentlichten Artikels verfolgen wir einen neuen Ansatz, indem wir sein Potenzial für Händler untersuchen.
Begeben Sie sich auf die nächste Phase unserer MQL5-Reise. In diesem aufschlussreichen und einsteigerfreundlichen Artikel werden wir die übrigen Array-Funktionen näher beleuchten und komplexe Konzepte entmystifizieren, damit Sie effiziente Handelsstrategien entwickeln können. Wir werden ArrayPrint, ArrayInsert, ArraySize, ArrayRange, ArrarRemove, ArraySwap, ArrayReverse und ArraySort besprechen. Erweitern Sie Ihre Kenntnisse im algorithmischen Handel mit diesen wichtigen Array-Funktionen. Begleiten Sie uns auf dem Weg zur MQL5-Meisterschaft!
Tauchen Sie ein in das Herz der neuronalen Netze, indem wir die Optimierungsalgorithmen, die innerhalb des neuronalen Netzes verwendet werden, entmystifizieren. In diesem Artikel erfahren Sie, mit welchen Schlüsseltechniken Sie das volle Potenzial neuronaler Netze ausschöpfen und Ihre Modelle zu neuen Höhen der Genauigkeit und Effizienz führen können.
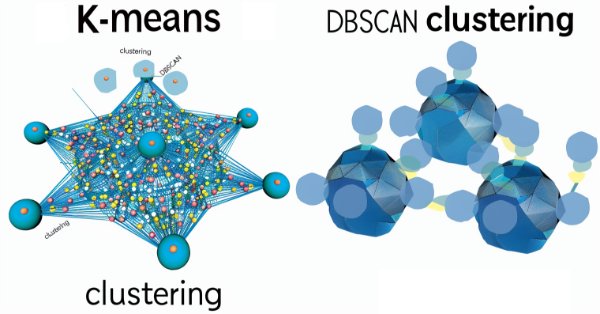
Density Based Spatial Clustering for Applications with Noise (DBSCAN) ist eine unüberwachte Form der Datengruppierung, die kaum Eingabeparameter benötigt, außer 2, was im Vergleich zu anderen Ansätzen wie K-Means ein Segen ist. Wir gehen der Frage nach, wie dies für das Testen und schließlich den Handel mit den von Wizard zusammengestellten Expert Advisers konstruktiv sein kann
Entdecken Sie die Welt der MQL5-Arrays in Teil 5, der sich an absolute Anfänger richtet. Dieser Artikel vereinfacht komplexe Kodierungskonzepte und legt dabei den Schwerpunkt auf Klarheit und Einbeziehung aller Beteiligten. Werden Sie Teil unserer Gemeinschaft von Lernenden, in der Fragen willkommen sind und Wissen geteilt wird!
Können wir bei der Erstellung von Modellen für Deep Learning mit Python von der Saisonalität profitieren? Hilft das Filtern von Daten für die ONNX-Modelle, um bessere Ergebnisse zu erzielen? Welchen Zeitabschnitt sollten wir verwenden? Wir werden all dies in diesem Artikel behandeln.
We will guide you through the entire process of DL with python to make a GRU ONNX model, culminating in the creation of an Expert Advisor (EA) designed for trading, and subsequently comparing GRU model with LSTN model.
Dive into the heart of Artificial Intelligence's enigma as we navigate the tumultuous waters of explainability. In a realm where models conceal their inner workings, our exploration unveils the "disagreement problem" that echoes through the corridors of machine learning.
В статье представлен новый подход к решению оптимизационных задач, путём объединения идей алгоритмов оптимизации бактериального поиска пищи (BFO) и приёмов, используемых в генетическом алгоритме (GA), в гибридный алгоритм BFO-GA. Он использует роение бактерий для глобального поиска оптимального решения и генетические операторы для уточнения локальных оптимумов. В отличие от оригинального BFO бактерии теперь могут мутировать и наследовать гены.
Seit den ersten Artikeln, die sich mit dem Verstärkungslernen befassten, haben wir uns auf die eine oder andere Weise mit zwei Problemen befasst: der Erkundung der Umgebung und der Bestimmung der Belohnungsfunktion. Jüngste Artikel haben sich mit dem Problem der Exploration beim Offline-Lernen befasst. In diesem Artikel möchte ich Ihnen einen Algorithmus vorstellen, bei dem die Autoren die Belohnungsfunktion vollständig eliminiert haben.
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung (labeling) von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!
In this article we will talk about the importance of APIs (Application Programming Interface) for interaction between different applications and software systems. We will see the role of APIs in simplifying interactions between applications, allowing them to efficiently share data and functionality.
Number Walls oder Zahlenwände sind eine Variante der Linear Shift Back Registers, die Sequenzen auf ihre Vorhersagbarkeit hin überprüfen, indem sie auf Konvergenz prüfen. Wir sehen uns an, wie diese Ideen in MQL5 von Nutzen sein könnten.
Der Artikel befasst sich mit einer Optimierungsmethode, die auf den Prinzipien des körpereigenen Immunsystems basiert - Mikro-Künstliches Immunsystem (Micro Artificial Immune System, Micro-AIS) - eine Modifikation von AIS. Micro-AIS verwendet ein einfacheres Modell des Immunsystems und einfache Informationsverarbeitungsprozesse des Immunsystems. In dem Artikel werden auch die Vor- und Nachteile von Mikro-AIS im Vergleich zu herkömmlichen AIS erörtert.
Der Artikel behandelt eine Gruppe von Optimierungsalgorithmen, die als Evolutionsstrategien (ES) bekannt sind. Sie gehören zu den allerersten Populationsalgorithmen, die evolutionäre Prinzipien für die Suche nach optimalen Lösungen nutzen. Wir werden Änderungen an den herkömmlichen ES-Varianten vornehmen und die Testfunktion und die Prüfstandsmethodik für die Algorithmen überarbeiten.
Die Datenformate, die zur Darstellung von Modellen des maschinellen Lernens verwendet werden, spielen eine entscheidende Rolle für deren Effektivität. In den letzten Jahren sind mehrere neue Datentypen aufgetaucht, die speziell für die Arbeit mit Deep-Learning-Modellen entwickelt wurden. In diesem Artikel werden wir uns auf zwei neue Datenformate konzentrieren, die sich in modernen Modellen durchgesetzt haben.
Entdecken Sie die Geheimnisse dieser leistungsstarken Dimensionsreduktionstechniken, indem wir ihre Anwendungen in der MQL5-Handelsumgebung analysieren. Vertiefen Sie sich in die Feinheiten der linearen Diskriminanzanalyse (LDA) und der Hauptkomponentenanalyse (PCA) und gewinnen Sie ein tiefes Verständnis für deren Auswirkungen auf die Strategieentwicklung und Marktanalyse,
Enthüllen wir die Geheimnisse der MQL5-Programmierung in unserem neuesten Artikel! Vertiefen wir uns in die Grundlagen von Strukturen, Klassen und Zeitfunktionen und machen uns mit der Programmierung vertraut. Egal, ob Sie Anfänger oder erfahrener Entwickler sind, unser Leitfaden vereinfacht komplexe Konzepte und bietet wertvolle Einblicke für die Beherrschung von MQL5. Verbessern Sie Ihre Programmierkenntnisse und bleiben Sie in der Welt des algorithmischen Handels an der Spitze!
Entdecken Sie die Grundlagen der MQL5-Programmierung in diesem einsteigerfreundlichen Artikel, in dem wir Arrays, nutzerdefinierte Funktionen, Präprozessoren und die Ereignisbehandlung entmystifizieren, wobei jede Codezeile verständlich erklärt wird. Erschließen wir die Leistungsfähigkeit von MQL5 mit einem einzigartigen Ansatz, der das Verständnis bei jedem Schritt sicherstellt. Dieser Artikel legt den Grundstein für die Beherrschung von MQL5, indem er die Erklärung jeder Codezeile hervorhebt und eine eindeutige und bereichernde Lernerfahrung bietet.
AdaBoost, ein leistungsstarker Boosting-Algorithmus, der die Leistung Ihrer KI-Modelle steigert. AdaBoost, die Abkürzung für Adaptive Boosting, ist ein ausgeklügeltes Ensemble-Lernverfahren, das schwache Lerner nahtlos integriert und ihre kollektive Vorhersagestärke erhöht.
Restriktive Boltzmann-Maschinen (RBM) sind im Grunde genommen ein zweischichtiges neuronales Netz, das durch Dimensionsreduktion eine unbeaufsichtigte Klassifizierung ermöglicht. Wir nehmen die Grundprinzipien und untersuchen, ob wir durch eine unorthodoxe Umgestaltung und ein entsprechendes Training einen nützlichen Signalfilter erhalten können.
Im Rahmen des Projekts wird Python für Deep Learning-basierte Prognosen auf den Finanzmärkten eingesetzt. Wir werden die Feinheiten des Testens der Leistung des Modells anhand von Schlüsselkennzahlen wie dem mittleren absoluten Fehler (MAE), dem mittleren quadratischen Fehler (MSE) und dem R-Quadrat (R2) erkunden und lernen, wie man alles in eine ausführbare Datei verpackt. Wir werden auch eine ONNX-Modelldatei mit seinem EA erstellen.
Begeben wir uns mit Teil zwei unserer MQL5-Serie auf eine aufschlussreiche Reise. Diese Artikel sind nicht einfach nur Anleitungen, sie sind die Tore zu einem verzauberten Reich, in dem Programmieranfänger und Zauberer gleichermaßen zu Hause sind. Was macht diese Reise wirklich magisch? Teil zwei unserer MQL5-Serie zeichnet sich durch seine erfrischende Einfachheit aus, die komplexe Konzepte für alle zugänglich macht. Beantworten Sie Ihre Fragen interaktiv und sorgen Sie so für eine bereichernde und individuelle Lernerfahrung. Lassen Sie uns eine Gemeinschaft aufbauen, in der das Verständnis von MQL5 für jeden ein Abenteuer ist. Willkommen in der Welt der Verzauberung!
Die verkürzte Singulärwertzerlegung (Truncated Singular Value Decomposition, SVD) und die nicht-negative Matrixzerlegung (Non-Negative Matrix Factorization, NMF) sind Verfahren zur Dimensionsreduktion. Beide spielen eine wichtige Rolle bei der Entwicklung von datengesteuerten Handelsstrategien. Entdecken Sie die Kunst der Dimensionalitätsreduzierung, der Entschlüsselung von Erkenntnissen und der Optimierung quantitativer Analysen für einen fundierten Ansatz zur Navigation durch die Feinheiten der Finanzmärkte.
Der erste Teil war dem bekannten und beliebten Algorithmus des Simulated Annealing gewidmet. Wir haben ihre Vor- und Nachteile gründlich abgewogen. Der zweite Teil des Artikels ist der radikalen Umgestaltung des Algorithmus gewidmet, die ihn zu einem neuen Optimierungsalgorithmus macht, dem Simulated Isotropic Annealing (SIA).
Der Artikel untersucht die Auswirkungen einer Formveränderung von Wahrscheinlichkeitsverteilungen auf die Leistung von Optimierungsalgorithmen. Wir werden Experimente mit dem Testalgorithmus Smart Cephalopod (SC) durchführen, um die Effizienz verschiedener Wahrscheinlichkeitsverteilungen im Zusammenhang mit Optimierungsproblemen zu bewerten.