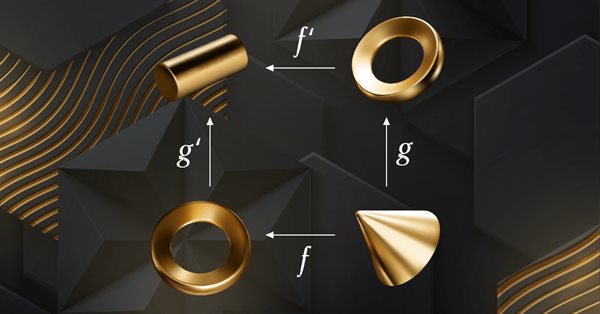Dieses Material bietet eine vollständige Anleitung zur Erstellung einer Klasse in MQL5 für die effiziente Verwaltung von CSV-Dateien. Wir werden die Implementierung von Methoden zum Öffnen, Schreiben, Lesen und Umwandeln von Daten sehen. Wir werden auch überlegen, wie wir sie zum Speichern und Abrufen von Informationen nutzen können. Darüber hinaus werden wir die Grenzen und die wichtigsten Aspekte bei der Verwendung einer solchen Klasse erörtern. Dieser Artikel kann eine wertvolle Ressource für diejenigen sein, die lernen wollen, wie man CSV-Dateien in MQL5 verarbeitet.
Hier wird nur einer der Aspekte des maschinellen Lernens beschrieben — die Aktivierungsfunktionen. In künstlichen neuronalen Netzen berechnet eine Neuronenaktivierungsfunktion einen Ausgangssignalwert auf der Grundlage der Werte eines Eingangssignals oder eines Satzes von Eingangssignalen. Wir werden uns mit den inneren Abläufen des Prozesses befassen.
Der Artikel liefert ein Beispiel für die Verwendung eines Perzeptrons als autarkes Preisprognoseinstrument, indem er allgemeine Konzepte und den einfachsten vorgefertigten Expert Advisor vorstellt und anschließend die Ergebnisse seiner Optimierung zeigt.
Neuronale Netze sind ein ultimatives Instrument im Werkzeugkasten der Händler. Prüfen wir, ob diese Annahme zutrifft. MetaTrader 5 ist als autarkes Medium für den Einsatz neuronaler Netze im Handel konzipiert. Dazu gibt es eine einfache Erklärung.
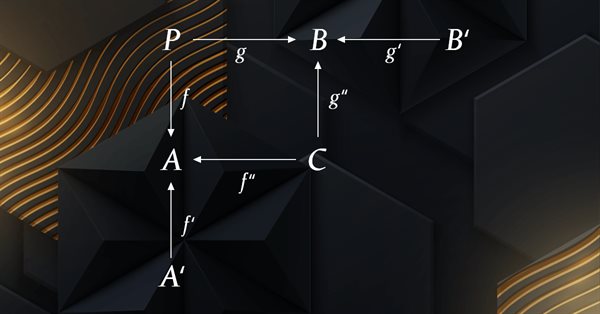
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der erst seit kurzem in der MQL5-Gemeinschaft Beachtung findet. In dieser Artikelserie sollen einige der Konzepte und Axiome erforscht und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die Einblicke gewährt und hoffentlich auch die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung von Händlern fördert.
Der Artikel beschreibt die Prinzipien, Methoden und Möglichkeiten der Anwendung des elektromagnetischen Algorithmus bei verschiedenen Optimierungsproblemen. Der EM-Algorithmus ist ein effizientes Optimierungswerkzeug, das mit großen Datenmengen und mehrdimensionalen Funktionen arbeiten kann.
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der erst seit kurzem in der MQL5-Gemeinschaft Beachtung findet. In dieser Artikelserie sollen einige der Konzepte und Axiome erforscht und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die Einblicke gewährt und hoffentlich auch die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung von Händlern fördert.
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die Einblicke gewährt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung von Händlern fördert.
Revolutionieren Sie Ihre Finanzmarktanalyse mit der Principal Component Analysis (PCA, Hauptkomponentenanalyse)! Entdecken Sie, wie diese leistungsstarke Technik verborgene Muster in Ihren Daten entschlüsseln, latente Markttrends aufdecken und Ihre Anlagestrategien optimieren kann. In diesem Artikel untersuchen wir, wie die PCA eine neue Sichtweise für die Analyse komplexer Finanzdaten bieten kann, die Erkenntnisse zutage fördert, die bei herkömmlichen Ansätzen übersehen würden. Finden Sie heraus, wie die Anwendung von PCA auf Finanzmarktdaten Ihnen einen Wettbewerbsvorteil verschaffen und Ihnen helfen kann, der Zeit voraus zu sein
Sind Sie es leid, ständig zu versuchen, den Aktienmarkt vorherzusagen? Hätten Sie gerne eine Kristallkugel, die Ihnen hilft, fundiertere Investitionsentscheidungen zu treffen? Selbst trainierte neuronale Netze könnten die Lösung sein, nach der Sie schon lange gesucht haben. In diesem Artikel gehen wir der Frage nach, ob diese leistungsstarken Algorithmen Ihnen helfen können, „die Welle zu reiten“ und den Aktienmarkt zu überlisten. Durch die Analyse großer Datenmengen und die Erkennung von Mustern können selbst trainierte neuronale Netze Vorhersagen treffen, die oft genauer sind als die von menschlichen Händlern. Entdecken Sie, wie Sie diese Spitzentechnologie nutzen können, um Ihre Gewinne zu maximieren und intelligentere Investitionsentscheidungen zu treffen.
Der Algorithmus Saplings Sowing and Growing up (SSG, Setzen, Säen und Wachsen) wurde von einem der widerstandsfähigsten Organismen der Erde inspiriert, der unter den verschiedensten Bedingungen überleben kann.
In diesem Artikel werde ich den Optimierungsalgorithmus Affen-Algorithmus (MA, Monkey Algorithmus) betrachten. Die Fähigkeit dieser Tiere, schwierige Hindernisse zu überwinden und die unzugänglichsten Baumkronen zu erreichen, bildete die Grundlage für die Idee des MA-Algorithmus.
In den Verstärkungslernmodellen, die wir im vorherigen Artikel besprochen haben, haben wir verschiedene Varianten von Faltungsnetzwerken verwendet, die in der Lage sind, verschiedene Objekte in den Originaldaten zu identifizieren. Der Hauptvorteil von Faltungsnetzen ist die Fähigkeit, Objekte unabhängig von ihrer Position zu erkennen. Gleichzeitig sind Faltungsnetzwerke nicht immer leistungsfähig, wenn es zu verschiedenen Verformungen von Objekten und Rauschen kommt. Dies sind die Probleme, die das relationale Modell lösen kann.
In diesem Artikel werde ich mit Hilfe von Experimenten und unkonventionellen Ansätzen ein profitables Handelssystem entwickeln und prüfen, ob Neuronale Netze für Händler eine Hilfe sein können. Der MetaTrader 5 als ein autarkes Tool für den Einsatz Neuronaler Netze im Handel. Einfache Erklärung.
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die Einblicke gewährt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung von Händlern fördert.
Der Handel mit Wahrscheinlichkeiten ist wie ein Drahtseilakt - er erfordert Präzision, Ausgewogenheit und ein ausgeprägtes Risikobewusstsein. In der Welt des Handels ist die Wahrscheinlichkeit alles. Das ist der Unterschied zwischen Erfolg und Misserfolg, Gewinn und Verlust. Indem sie sich die Macht der Wahrscheinlichkeit zunutze machen, können Händler fundierte Entscheidungen treffen, Risiken effektiv verwalten und ihre finanziellen Ziele erreichen. Ob Sie nun ein erfahrener Anleger oder ein Anfänger sind, das Verständnis der Wahrscheinlichkeit ist der Schlüssel zur Entfaltung Ihres Handelspotenzials. In diesem Artikel werden wir die aufregende Welt des Handels mit Wahrscheinlichkeiten erkunden und Ihnen zeigen, wie Sie Ihr Handelsspiel auf die nächste Stufe heben können.
In diesem Artikel werde ich den leistungsstärksten Optimierungsalgorithmus untersuchen und testen - die Harmonie-Suche (HS), inspiriert durch den Prozess der Suche nach der perfekten Klangharmonie. Welcher Algorithmus ist nun der führende in unserer Bewertung?
ONNX (Open Neural Network eXchange) ist ein offenes Format zur Darstellung neuronaler Netze. In diesem Artikel zeigen wir Ihnen, wie Sie zwei ONNX-Modelle gleichzeitig in einem Expert Advisor verwenden können.
Der Artikel beschreibt die Theorie und Praxis der Anwendung des Backpropagation-Algorithmus in MQL5 unter Verwendung von Matrizen. Es bietet vorgefertigte Klassen zusammen mit Beispielen von Skripten, Indikatoren und Expert Advisors.
ONNX (Open Neural Network Exchange) ist ein offenes Format, das zur Darstellung von Modellen des maschinellen Lernens entwickelt wurde. In diesem Artikel wird untersucht, wie ein CNN-LSTM-Modell zur Vorhersage von Finanzzeitreihen erstellt werden kann. Wir werden auch zeigen, wie man das erstellte ONNX-Modell in einem MQL5 Expert Advisor verwendet.
GSA ist ein von der unbelebten Natur inspirierter Populationsoptimierungsalgorithmus. Dank des in den Algorithmus implementierten Newton'schen Gravitationsgesetzes können wir dank der hohen Zuverlässigkeit der Modellierung der Interaktion physikalischer Körper den bezaubernden Tanz von Planetensystemen und Galaxienhaufen beobachten. In diesem Artikel möchte ich einen der interessantesten und originellsten Optimierungsalgorithmen vorstellen. Der Simulator für die Bewegung von Raumobjekten ist ebenfalls vorhanden.
Wir untersuchen weiterhin Algorithmen für das verstärkte Lernen. Alle bisher betrachteten Algorithmen erfordern die Erstellung einer Belohnungspolitik, die es dem Agenten ermöglicht, jede seiner Aktionen bei jedem Übergang von einem Systemzustand in einen anderen zu bewerten. Dieser Ansatz ist jedoch ziemlich künstlich. In der Praxis gibt es eine gewisse Zeitspanne zwischen einer Handlung und einer Belohnung. In diesem Artikel werden wir einen Algorithmus zum Trainieren eines Modells kennenlernen, der mit verschiedenen Zeitverzögerungen zwischen Aktion und Belohnung arbeiten kann.
Wir untersuchen weiterhin verteilte Q-Learning-Algorithmen. In früheren Artikeln haben wir verteilte und Quantil-Q-Learning-Algorithmen besprochen. Im ersten Algorithmus haben wir die Wahrscheinlichkeiten für bestimmte Wertebereiche trainiert. Im zweiten Algorithmus haben wir Bereiche mit einer bestimmten Wahrscheinlichkeit trainiert. In beiden Fällen haben wir a priori Wissen über eine Verteilung verwendet und eine andere trainiert. In diesem Artikel wenden wir uns einem Algorithmus zu, der es dem Modell ermöglicht, für beide Verteilungen trainiert zu werden.
Die Ridge-Regression ist ein einfaches Verfahren zur Reduzierung der Modellkomplexität und zur Vermeidung einer Überanpassung, die bei einer einfachen linearen Regression auftreten kann.
Maschinelles Lernen hat sich zu einer beliebten Methode für die Strategieentwicklung entwickelt. Während die Maximierung der Rentabilität und der Vorhersagegenauigkeit stärker in den Vordergrund gerückt wurde, wurde der Bedeutung der Verarbeitung der Daten, die zur Erstellung von Vorhersagemodellen verwendet werden, nicht viel Aufmerksamkeit geschenkt. In diesem Artikel befassen wir uns mit der Verwendung des Konzepts der Entropie zur Bewertung der Eignung von Indikatoren für die Erstellung von Prognosemodellen, wie sie in dem Buch Testing and Tuning Market Trading Systems von Timothy Masters dokumentiert sind.
Wir setzen die Untersuchung des verteilten Q-Learnings fort. Heute wollen wir diesen Ansatz von der anderen Seite her betrachten. Wir werden die Möglichkeit prüfen, die Quantilsregression zur Lösung von Preisvorhersageaufgaben einzusetzen.
Die Strategie der Nahrungssuche des Bakteriums E. coli inspirierte die Wissenschaftler zur Entwicklung des BFO-Optimierungsalgorithmus. Der Algorithmus enthält originelle Ideen und vielversprechende Optimierungsansätze und ist es wert, weiter untersucht zu werden.
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die zu Kommentaren und Diskussionen anregt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung der Händler fördert.
Die erstaunliche Fähigkeit von Unkräutern, unter verschiedensten Bedingungen zu überleben, wurde zur Idee für einen leistungsstarken Optimierungsalgorithmus. IWO (Invasive Weed Optimization) ist einer der besten Algorithmen unter den bisher geprüften.
In dieser Artikelserie entwickle ich mit Hilfe von Experimenten und unkonventionellen Ansätzen ein profitables Handelssystem und prüfe, ob neuronale Netze für Trader eine Hilfe sein können. MetaTrader 5 ist als autarkes Werkzeug für den Einsatz neuronaler Netze im Handel konzipiert.
In diesem Artikel werde ich die Optimierungsmethode des Firefly-Algorithmus (FA) betrachten. Dank der Änderung hat sich der Algorithmus von einem Außenseiter zu einem echten Tabellenführer entwickelt.
Matrizen dienen als Grundlage für Algorithmen des maschinellen Lernens und für Computer im Allgemeinen, da sie große mathematische Operationen effektiv verarbeiten können. Die Standardbibliothek bietet alles, was man braucht, aber wir wollen sehen, wie wir sie erweitern können, indem wir in der Datei utils mehrere Funktionen einführen, die in der Bibliothek noch nicht vorhanden sind
Fish School Search (FSS, Suche mittels Fischschulen) ist ein neuer Optimierungsalgorithmus, der durch das Verhalten von Fischen in einem Schwarm inspiriert wurde, von denen die meisten (bis zu 80 %) in einer organisierten Gemeinschaft von Verwandten schwimmen. Es ist erwiesen, dass Fischansammlungen eine wichtige Rolle für die Effizienz der Nahrungssuche und den Schutz vor Räubern spielen.
Der nächste Algorithmus, den ich besprechen werde, ist die Optimierung der Kuckuckssuche (Cockoo) mit Levy-Flügen. Dies ist einer der neuesten Optimierungsalgorithmen und ein neuer Spitzenreiter in der Rangliste.
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die zu Kommentaren und Diskussionen anregt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung der Händler fördert.
Betrachten wir einen der neuesten modernen Optimierungsalgorithmen - die Grey-Wolf-Optimierung. Das originelle Verhalten bei Testfunktionen macht diesen Algorithmus zu einem der interessantesten unter den zuvor besprochenen Algorithmen. Dies ist einer der besten Algorithmen für das Training neuronaler Netze, glatte Funktionen mit vielen Variablen.
In diesem Artikel werden wir den Algorithmus eines künstlichen Bienenvolkes untersuchen und unser Wissen durch neue Prinzipien zur Untersuchung funktionaler Räume ergänzen. In diesem Artikel werde ich meine Interpretation der klassischen Version des Algorithmus vorstellen.
Wir haben die Q-Learning-Methode in einem der früheren Artikel dieser Serie kennengelernt. Bei dieser Methode werden die Belohnungen für jede Aktion gemittelt. Im Jahr 2017 wurden zwei Arbeiten vorgestellt, die einen größeren Erfolg bei der Untersuchung der Belohnungsverteilungsfunktion zeigen. Wir sollten die Möglichkeit in Betracht ziehen, diese Technologie zur Lösung unserer Probleme einzusetzen.
Dieses Mal werde ich den Algorithmus der Ameisenkolonie-Optimierung analysieren. Der Algorithmus ist sehr interessant und komplex. In diesem Artikel versuche ich, eine neue Art von ACO zu schaffen.