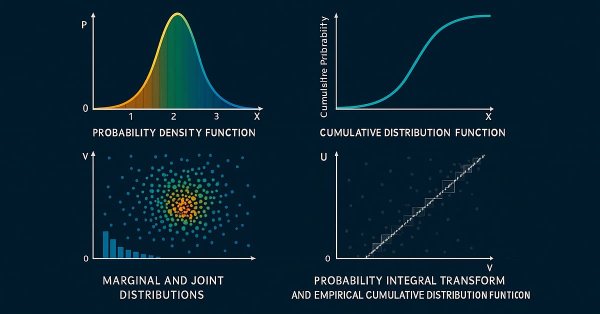
In the second installment of the series, we discuss the properties of bivariate Archimedean copulae and their implementation in MQL5. We also explore applying copulae to the development of a simple pairs trading strategy.
This article describes two additional scoring criteria used for selection of baskets of stocks to be traded in mean-reversion strategies, more specifically, in cointegration based statistical arbitrage. It complements a previous article where liquidity and strength of the cointegration vectors were presented, along with the strategic criteria of timeframe and lookback period, by including the stability of the cointegration vectors and the time to mean reversion (half-time). The article includes the commented results of a backtest with the new filters applied and the files required for its reproduction are also provided.
The article presents a new metaheuristic optimization Circle Search Algorithm (CSA) based on the geometric properties of a circle. The algorithm uses the principle of moving points along tangents to find the optimal solution, combining the phases of global exploration and local exploitation.
Sequential bootstrapping reshapes bootstrap sampling for financial machine learning by actively avoiding temporally overlapping labels, producing more independent training samples, sharper uncertainty estimates, and more robust trading models. This practical guide explains the intuition, shows the algorithm step‑by‑step, provides optimized code patterns for large datasets, and demonstrates measurable performance gains through simulations and real backtests.
In this article, I will explain how Chart Trade, together with the Expert Advisor, will process a request to close all of the users' open positions. This may sound simple, but there are a few complications that you need to know how to manage.
This article introduces the “Multi-Timeframe Harmony Index”—an advanced Expert Advisor for MetaTrader 5 that calculates a weighted bias from multiple timeframes, smooths the readings using EMA, and displays the results in a clean chart panel dashboard. It includes customizable alerts and automatic buy/sell signal plotting when strong bias thresholds are crossed. Suitable for traders who use multi-timeframe analysis to align entries with overall market structure.
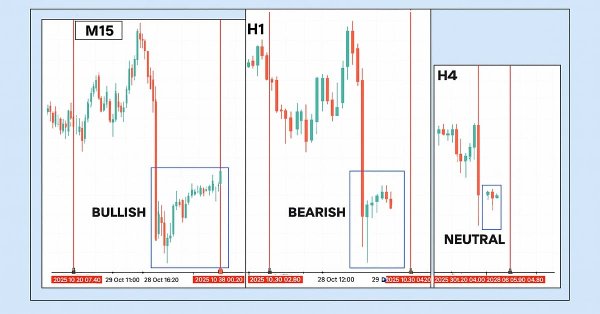
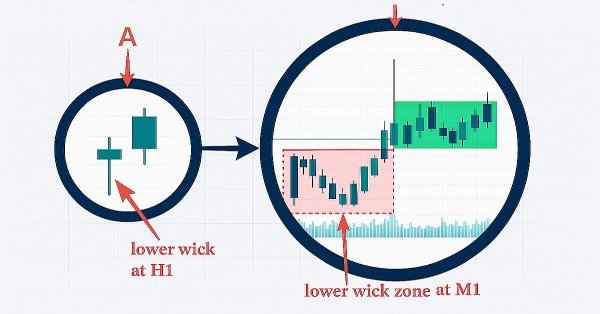
In this discussion, we take a step forward to uncover the underlying price action hidden within candlestick wicks. By integrating a wick visualization feature into the Market Periods Synchronizer, we enhance the tool with greater analytical depth and interactivity. This upgraded system allows traders to visualize higher-timeframe price rejections directly on lower-timeframe charts, revealing detailed structures that were once concealed within the shadows.
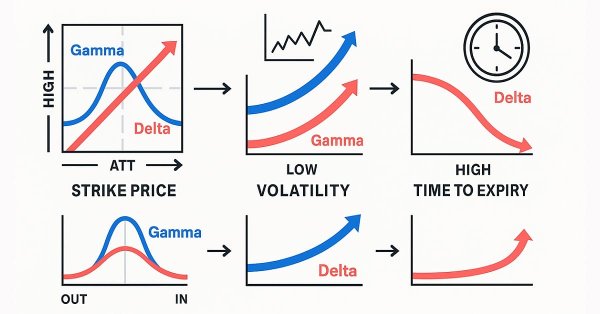
Gamma and Delta measure how an option’s value reacts to changes in the underlying asset’s price. Delta represents the rate of change of the option’s price relative to the underlying, while Gamma measures how Delta itself changes as price moves. Together, they describe an option’s directional sensitivity and convexity—critical for dynamic hedging and volatility-based trading strategies.
Discover how to fix a critical flaw in financial machine learning that causes overfit models and poor live performance—label concurrency. When using the triple-barrier method, your training labels overlap in time, violating the core IID assumption of most ML algorithms. This article provides a hands-on solution through sample weighting. You will learn how to quantify temporal overlap between trading signals, calculate sample weights that reflect each observation's unique information, and implement these weights in scikit-learn to build more robust classifiers. Learning these essential techniques will make your trading models more robust, reliable and profitable.
Global market sessions shape the rhythm of the trading day, and understanding their overlap is vital to timing entries and exits. In this article, we’ll build an interactive trading sessions EA that brings those global hours to life directly on your chart. The EA automatically plots color‑coded rectangles for the Asia, Tokyo, London, and New York sessions, updating in real time as each market opens or closes. It features on‑chart toggle buttons, a dynamic information panel, and a scrolling ticker headline that streams live status and breakout messages. Tested on different brokers, this EA combines precision with style—helping traders see volatility transitions, identify cross‑session breakouts, and stay visually connected to the global market’s pulse.
In this article, we propose a scoring system for mean-reversion strategies based on statistical arbitrage of cointegrated stocks. The article suggests criteria that go from liquidity and transaction costs to the number of cointegration ranks and time to mean-reversion, while taking into account the strategic criteria of data frequency (timeframe) and the lookback period for cointegration tests, which are evaluated before the score ranking properly. The files required for the reproduction of the backtest are provided, and their results are commented on as well.
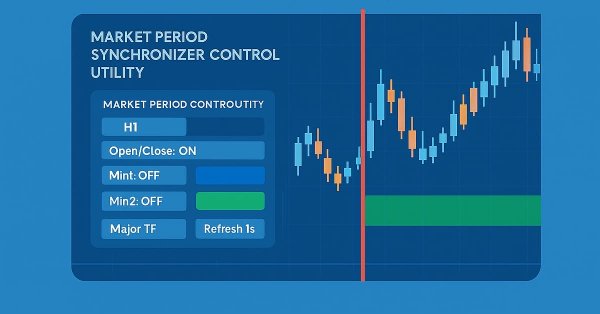
Imagine transforming the traditional EA or indicator input properties into a real-time, on-chart control interface. This discussion builds upon our foundational work in the Market Periods Synchronizer indicator, marking a significant evolution in how we visualize and manage higher-timeframe (HTF) market structures. Here, we turn that concept into a fully interactive utility—a dashboard that brings dynamic control and enhanced multi-period price action visualization directly onto the chart. Join us as we explore how this innovation reshapes the way traders interact with their tools.
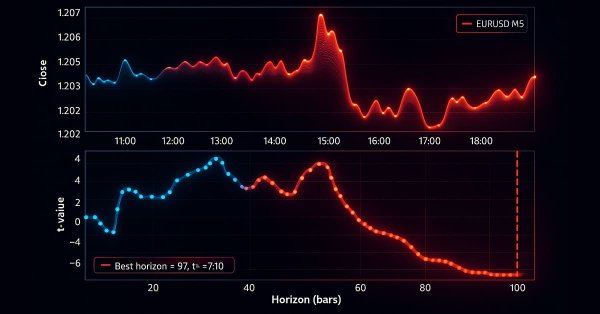
In this discussion, we contrast the classical approach to time series cross-validation with modern alternatives that challenge its core assumptions. We expose key blind spots in the traditional method—especially its failure to account for evolving market conditions. To address these gaps, we introduce Effective Memory Cross-Validation (EMCV), a domain-aware approach that questions the long-held belief that more historical data always improves performance.
In this article, we will start creating the C_Orders class to be able to send orders to the trading server. We'll do this little by little, as our goal is to explain in detail how this will happen through the messaging system.
The original Royal Flush Optimization algorithm offers a new approach to solving optimization problems, replacing the classic binary coding of genetic algorithms with a sector-based approach inspired by poker principles. RFO demonstrates how simplifying basic principles can lead to an efficient and practical optimization method. The article presents a detailed analysis of the algorithm and test results.
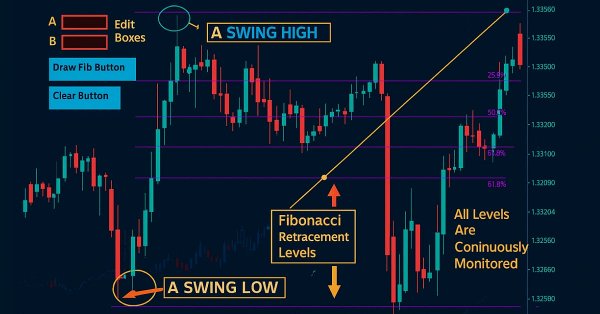
Fibonacci tools are among the most popular instruments used by technical analysts. In this article, we’ll build an Interactive Fibonacci EA that draws retracement and extension levels that react dynamically to price movement, delivering real‑time alerts, stylish lines, and a scrolling news‑style headline. Another key advantage of this EA is flexibility; you can manually type the high (A) and low (B) swing values directly on the chart, giving you exact control over the market range you want to analyze.
The article introduces the dialectical algorithm (DA), a new global optimization method inspired by the philosophical concept of dialectics. The algorithm exploits a unique division of the population into speculative and practical thinkers. Testing shows impressive performance of up to 98% on low-dimensional problems and overall efficiency of 57.95%. The article explains these metrics and presents a detailed description of the algorithm and the results of experiments on different types of functions.
For many traders, it's a familiar pain point: watching a trade come within a whisker of your profit target, only to reverse and hit your stop-loss. Or worse, seeing a trailing stop close you out at breakeven before the market surges toward your original target. This article focuses on using multiple entries at different Reward-to-Risk Ratios to systematically secure gains and reduce overall risk exposure.
We will build a biologically correct system of neurons for time series forecasting. The introduction of a plasma-like environment into the neural network architecture creates a kind of "collective intelligence," where each neuron influences the system's operation not only through direct connections, but also through long-range electromagnetic interactions. Let's see how the neural brain modeling system will perform in the market.
In this article, we explore a powerful MQL5 tool that let's you test any price level you desire with just one click. Simply enter your chosen level and press analyze, the EA instantly scans historical data, highlights every touch and breakout on the chart, and displays statistics in a clean, organized dashboard. You'll see exactly how often price respected or broke through your level, and whether it behaved more like support or resistance. Continue reading to explore the detailed procedure.
In this article, we will forecast future extreme volatility using binary classification. Besides, we will develop an extreme volatility forecast indicator using machine learning.
This is the first part of an article series presenting the implementation of bivariate copulae in MQL5. This article presents code implementing Gaussian and Student's t-copulae. It also delves into the fundamentals of statistical copulae and related topics. The code is based on the Arbitragelab Python package by Hudson and Thames.
In this discussion, we introduce a Higher-to-Lower Timeframe Synchronizer tool designed to solve the problem of analyzing market patterns that span across higher timeframe periods. The built-in period markers in MetaTrader 5 are often limited, rigid, and not easily customizable for non-standard timeframes. Our solution leverages the MQL5 language to develop an indicator that provides a dynamic and visual way to align higher timeframe structures within lower timeframe charts. This tool can be highly valuable for detailed market analysis. To learn more about its features and implementation, I invite you to join the discussion.
Often we have to take a step back and then move forward. In this article, we will show all the changes necessary to ensure that the Mouse and Chart Trade indicators do not break. As a bonus, we'll also cover other changes that have occurred in other header files that will be widely used in the future.
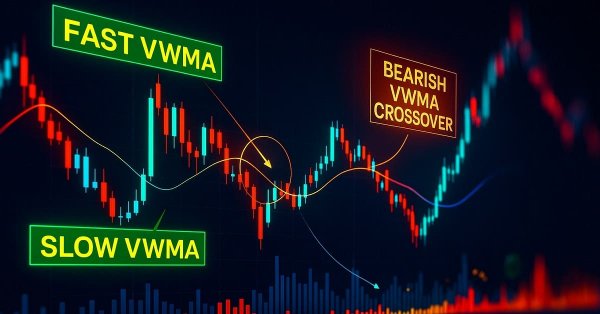
This article introduces a VWMA crossover signal tool for MetaTrader 5, designed to help traders identify potential bullish and bearish reversals by combining price action with trading volume. The EA generates clear buy and sell signals directly on the chart, features an informative panel, and allows for full user customization, making it a practical addition to your trading strategy.
This is my own algorithm. The article presents the Time Evolution Travel Algorithm (TETA) inspired by the concept of parallel universes and time streams. The basic idea of the algorithm is that, although time travel in the conventional sense is impossible, we can choose a sequence of events that lead to different realities.
Many traders have experienced this situation, often stick to their entry criteria but struggle with trade management. Even with the right setups, emotional decision-making—such as panic exits before trades reach their take-profit or stop-loss levels—can lead to a declining equity curve. How can traders overcome this issue and improve their results? This article will address these questions by examining random win-rates and demonstrating, through Monte Carlo simulation, how traders can refine their strategies by taking profits at reasonable levels before the original target is reached.
In this article, I introduce an innovative trading algorithm that combines evolutionary algorithms with deep reinforcement learning for Forex trading. The algorithm uses the mechanism of extinction of inefficient individuals to optimize the trading strategy.
In this article, we explore a data-driven approach to discovering and validating non-standard Fibonacci retracement levels that markets may respect. We present a complete workflow tailored for implementation in MQL5, beginning with data collection and bar or swing detection, and extending through clustering, statistical hypothesis testing, backtesting, and integration into an MetaTrader 5 Fibonacci tool. The goal is to create a reproducible pipeline that transforms anecdotal observations into statistically defensible trading signals.
Unlike what was done in the previous article, here we will test the selection option using an Expert Advisor. Although this is not a final solution yet, it will be enough for now. With the help of this article, you will be able to understand how to implement one of the possible solutions.
We have built a robust feature engineering pipeline using proper tick-based bars to eliminate data leakage and solved the critical problem of labeling with meta-labeled triple-barrier signals. This installment covers the advanced labeling technique, trend-scanning, for adaptive horizons. After covering the theory, an example shows how trend-scanning labels can be used with meta-labeling to improve on the classic moving average crossover strategy.
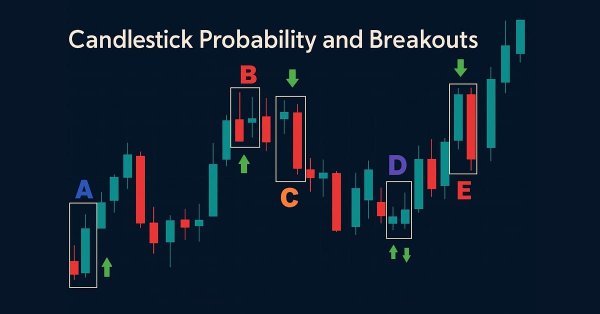
Enhance your market analysis with the MQL5-native Candlestick Probability EA, a lightweight tool that transforms raw price bars into real-time, instrument-specific probability insights. It classifies Pinbars, Engulfing, and Doji patterns at bar close, uses ATR-aware filtering, and optional breakout confirmation. The EA calculates raw and volume-weighted follow-through percentages, helping you understand each pattern's typical outcome on specific symbols and timeframes. On-chart markers, a compact dashboard, and interactive toggles allow easy validation and focus. Export detailed CSV logs for offline testing. Use it to develop probability profiles, optimize strategies, and turn pattern recognition into a measurable edge.
We will look at price discretization methods using Python + MQL5. In this article, I will share my practical experience developing a Python library that implements a wide range of approaches to bar formation — from classic Volume and Range bars to more exotic methods like Renko and Kagi. We will consider three-line breakout candles and range bars analyzing their statistics and trying to define how else the prices can be represented discretely.
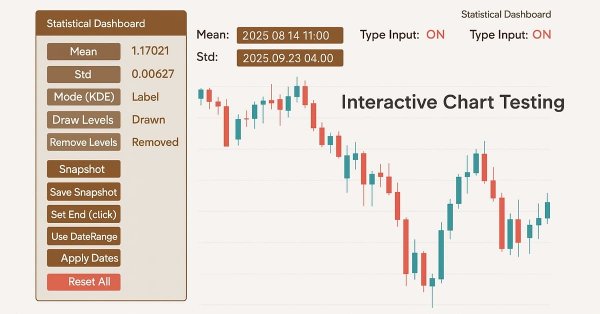
In a world where speed and precision matter, analysis tools need to be as smart as the markets we trade. This article presents an EA built on button logic—an interactive system that instantly transforms raw price data into meaningful statistical levels. With a single click, it calculates and displays mean, deviation, percentiles, and more, turning advanced analytics into clear on-chart signals. It highlights the zones where price is most likely to bounce, retrace, or break, making analysis both faster and more practical.
The article considers a new population optimization algorithm - Cyclic Parthenogenesis Algorithm (CPA), inspired by the unique reproductive strategy of aphids. The algorithm combines two reproduction mechanisms — parthenogenesis and sexual reproduction — and also utilizes the colonial structure of the population with the possibility of migration between colonies. The key features of the algorithm are adaptive switching between different reproductive strategies and a system of information exchange between colonies through the flight mechanism.
This article proposes an asset screening process for a statistical arbitrage trading strategy through cointegrated stocks. The system starts with the regular filtering by economic factors, like asset sector and industry, and finishes with a list of criteria for a scoring system. For each statistical test used in the screening, a respective Python class was developed: Pearson correlation, Engle-Granger cointegration, Johansen cointegration, and ADF/KPSS stationarity. These Python classes are provided along with a personal note from the author about the use of AI assistants for software development.
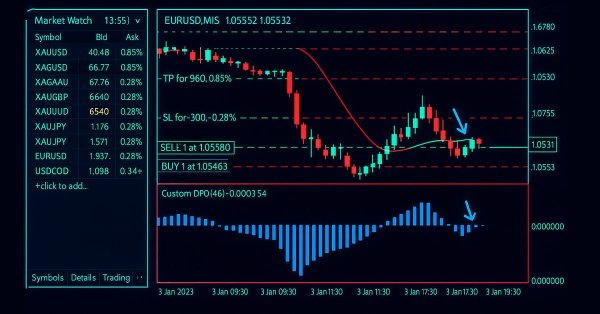
This article explains how to design and optimise a trading system using the Detrended Price Oscillator (DPO) in MQL5. It outlines the indicator's core logic, demonstrating how it identifies short-term cycles by filtering out long-term trends. Through a series of step-by-step examples and simple strategies, readers will learn how to code it, define entry and exit signals, and conduct backtesting. Finally, the article presents practical optimization methods to enhance performance and adapt the system to changing market conditions.
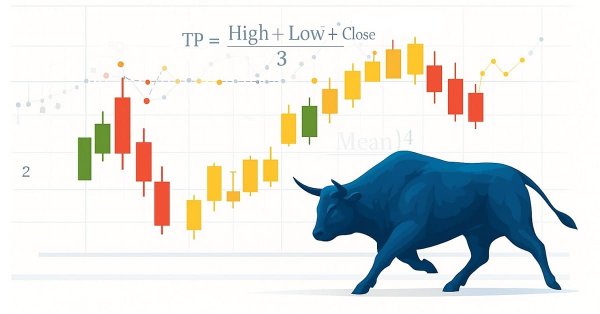
Statistics has always been at the heart of financial analysis. By definition, statistics is the discipline that collects, analyzes, interprets, and presents data in meaningful ways. Now imagine applying that same framework to candlesticks—compressing raw price action into measurable insights. How helpful would it be to know, for a specific period of time, the central tendency, spread, and distribution of market behavior? In this article, we introduce exactly that approach, showing how statistical methods can transform candlestick data into clear, actionable signals.
The article describes the experience of developing a hybrid trading system that combines classical technical analysis with neural networks. The author provides a detailed analysis of the system architecture from basic pattern analysis and neural network structure to the mechanisms behind trading decisions, and shares real code and practical observations.
This article presents a study of the interaction of different activation functions with optimization algorithms in the context of neural network training. Particular attention is paid to the comparison of the classical ADAM and its population version when working with a wide range of activation functions, including the oscillating ACON and Snake functions. Using a minimalistic MLP (1-1-1) architecture and a single training example, the influence of activation functions on the optimization is isolated from other factors. The article proposes an approach to manage network weights through the boundaries of activation functions and a weight reflection mechanism, which allows avoiding problems with saturation and stagnation in training.