En este artículo, te muestro lo que necesitas hacer para empezar a utilizar Excel y controlar MetaTrader 5, pero de una forma muy interesante. Para ello, utilizaremos un complemento de Excel, de modo que no sea necesario utilizar el VBA integrado. Si no sabes de qué complemento se trata, consulta este artículo y aprende a programar en Python directamente en Excel.
Hoy utilizaremos un computadora cuántica de IBM para descubrir todas las variantes del movimiento de los precios. ¿Le suena a ciencia ficción? ¡Bienvenido al mundo de la informática cuántica para el trading!
Este artículo explora una nueva dimensión del análisis utilizando librerías externas diseñadas específicamente para análisis avanzados. Estas librerías, como pandas, proporcionan potentes herramientas para procesar e interpretar datos complejos, lo que permite a los operadores obtener una visión más profunda de la dinámica del mercado. Al integrar estas tecnologías, podemos salvar la brecha entre los datos brutos y las estrategias viables. Únase a nosotros para sentar las bases de este enfoque innovador y liberar el potencial de combinar la tecnología con la experiencia en el comercio.
Aprenda a completar la creación del módulo final en la librería History Manager EX5, centrándose en las funciones responsables de gestionar la orden pendiente cancelada más recientemente. Esto le proporcionará las herramientas necesarias para recuperar y almacenar de manera eficiente los detalles clave relacionados con las órdenes pendientes canceladas con MQL5.
Si hemos empezado a automatizar la optimización periódica, también deberíamos ocuparnos de la actualización automática de los ajustes de los asesores expertos que ya están trabajando en la cuenta comercial. También deberíamos permitirle ejecutar un asesor experto en el simulador de estrategias y cambiar su configuración en una sola pasada.
A muchas personas, especialmente a los no programadores, les resulta muy difícil transferir información entre MetaTrader 5 y otros programas. Uno de esos programas es Excel. Muchos utilizan Excel para gestionar y controlar sus riesgos, ya que es un programa muy bueno y fácil de aprender, incluso para quienes no son programadores de VBA. A continuación, voy a mostrar cómo establecer la comunicación entre MetaTrader 5 y Excel (un método muy sencillo).
Como una de las herramientas de análisis de la acción del precio más potentes, el panel de métricas está diseñado para optimizar el análisis del mercado al proporcionar instantáneamente métricas esenciales del mercado con solo hacer clic en un botón. Cada botón tiene una función específica, ya sea analizar tendencias altas/bajas, volumen u otros indicadores clave. Esta herramienta proporciona datos precisos y en tiempo real cuando más los necesita. Profundicemos en sus características en este artículo.
Este trabajo presenta un nuevo algoritmo metaheurístico de optimización CSA (Circle Search Algorithm) basado en las propiedades geométricas del círculo. El algoritmo usa el principio de desplazamiento de puntos por tangentes para encontrar la solución óptima combinando fases de exploración global y explotación local.
En este artículo, analizaremos la implementación de MQL5 en colaboración con Python para realizar operaciones relacionadas con los brókers. Imagina tener un asesor experto (Expert Advisor, EA) funcionando continuamente alojado en un VPS, ejecutando operaciones en tu nombre. En algún momento, la capacidad de la EA para gestionar fondos se vuelve primordial. Esto incluye operaciones como recargar su cuenta de trading e iniciar retiradas. En este debate, analizaremos las ventajas y la aplicación práctica de estas funciones, garantizando una integración perfecta de la gestión de fondos en su estrategia comercial. ¡Estén atentos!
¿Cómo se desplaza el mercado por una relación basada en los números de Fibonacci? Esta secuencia, en la que cada número sucesivo es igual a la suma de los dos anteriores (1, 1, 2, 3, 3, 5, 8, 13, 21...), no solo describe el crecimiento de la población de conejos. Hoy vamos a analizar la hipótesis de Pitágoras de que todo en el mundo obedece a ciertas relaciones de números....
Seguimos intentando descifrar los movimientos de los precios.... ¿Qué tal un análisis lingüístico del "diccionario de mercado" que obtendríamos convirtiendo el código binario de precios en BIP39? En el presente artículo, nos adentramos en un enfoque innovador del análisis de los datos bursátiles y exploramos cómo pueden aplicarse las modernas técnicas de procesamiento del lenguaje natural al lenguaje del mercado.
La creación de integraciones de intercambio de criptomonedas sin DLL ha sido durante mucho tiempo un reto, pero esta solución proporciona un marco completo para la conectividad directa con el mercado.
En este artículo se desarrolla una clase para gestionar cierres parciales en MQL5 y se integra dentro de un EA de order blocks. Además, se presentan pruebas de backtest comparando la estrategia con y sin parciales, analizando en qué condiciones su uso puede maximizar y asegurar beneficios. Concluimos que especialmente en estilos de trading orientados a movimientos más amplios, el uso de parciales podría ser beneficioso.
Los modelos ocultos de Markov (Hidden Markov Models, HMM) son potentes herramientas estadísticas que identifican los estados subyacentes del mercado mediante el análisis de los movimientos observables de los precios. En el ámbito bursátil, los HMM mejoran la predicción de la volatilidad y proporcionan información para las estrategias de seguimiento de tendencias mediante la modelización y la anticipación de los cambios en los regímenes de mercado. En este artículo, presentaremos el procedimiento completo para desarrollar una estrategia de seguimiento de tendencias que utiliza HMM para predecir la volatilidad como filtro.
Aproveche todo el potencial del análisis multitemporal con «Signal Pulse», un asesor experto MQL5 que integra las bandas de Bollinger y el oscilador estocástico para ofrecer señales de trading precisas y de alta probabilidad. Descubra cómo implementar esta estrategia y visualizar eficazmente las oportunidades de compra y venta utilizando flechas personalizadas. Ideal para operadores que buscan mejorar su capacidad de juicio mediante análisis automatizados en múltiples marcos temporales.
Aprenda a crear un módulo EX5 de funciones exportables que consultan y guardan datos de forma fluida para el pedido pendiente completado más recientemente. En esta guía paso a paso, mejoraremos la librería History Management EX5 desarrollando funciones específicas y compartimentadas para recuperar las propiedades esenciales de la última orden pendiente completada. Estas propiedades incluyen el tipo de orden, el tiempo de configuración, el tiempo de ejecución, el tipo de ejecución y otros detalles críticos necesarios para la gestión y el análisis eficaces del historial de operaciones de las órdenes pendientes.
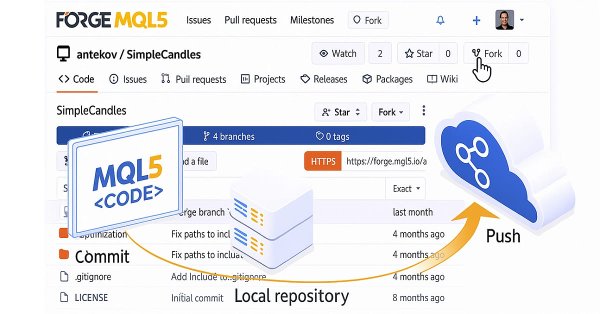
Continuaremos el desarrollo del proyecto Simple Candles y Adwizard describiendo los matices del uso del sistema de control de versiones y el repositorio MQL5 Algo Forge.
En este artículo se implementará la filtración de noticias para eventos de noticias individuales basándose en sus identificadores. Además, se mejorarán las consultas SQL anteriores para proporcionar información adicional o reducir el tiempo de ejecución de la consulta. Además, se hará funcional el código creado en los artículos anteriores.
El algoritmo Royal Flush Optimization del autor ofrece una nueva perspectiva en la resolución de problemas de optimización sustituyendo la clásica codificación binaria de los algoritmos genéticos por un enfoque basado en sectores e inspirado en los principios del póquer. El RFO demuestra cómo la simplificación de los principios básicos puede dar lugar a un método de optimización eficaz y práctico. El artículo presenta un análisis detallado del algoritmo y los resultados de las pruebas.
Soft Actor Critic es un algoritmo de aprendizaje por refuerzo que utiliza tres redes neuronales. Una red de actores y dos redes de críticos. Estos modelos de aprendizaje automático se emparejan en una relación maestro-esclavo en la que los críticos se modelan para mejorar la precisión de las previsiones de la red de actores. Al tiempo que introducimos ONNX en esta serie, exploramos cómo estas ideas podrían ponerse a prueba como una señal personalizada de un asesor experto ensamblado por un asistente.
Descubra cómo crear funciones EX5 exportables para consultar y guardar de forma eficiente datos históricos de posición. En esta guía paso a paso, ampliaremos la libreria de gestión del historial EX5 mediante el desarrollo de módulos que recuperan las propiedades clave de la posición cerrada más recientemente. Entre ellos se incluyen el beneficio neto, la duración de la operación, el stop loss basado en pips, el take profit, los valores de beneficio y otros detalles importantes.
Hoy veremos cómo podemos conectar el código de otra persona desde cualquier repositorio en el almacenamiento MQL5 Algo Forge a nuestro proyecto. En el presente artículo, finalmente abordaremos esta tarea prometedora pero también compleja: cómo conectar y utilizar en la práctica bibliotecas de repositorios de terceros del almacenamiento MQL5 Algo Forge en nuestro proyecto.
Hoy nos familiarizaremos con el Algoritmo Dialéctico (DA), un nuevo método de optimización global inspirado en el concepto filosófico de la dialéctica. El algoritmo explota la singular división de la población en pensadores especulativos y prácticos. Las pruebas demuestran un impresionante rendimiento de hasta el 98% en tareas pequeñas y una eficiencia global del 57,95%. El artículo explica estas métricas y presenta una descripción detallada del algoritmo y resultados experimentales con distintos tipos de características.
Construimos un sistema de neuronas biológicamente correcto para la predicción de series temporales. La introducción de un medio similar al plasma en la arquitectura de una red neuronal ha creado una especie de "mente colectiva", en la que cada neurona influye en el trabajo del sistema no solo a través de conexiones directas, sino también mediante interacciones electromagnéticas de largo alcance. ¿Cómo se comportará el sistema de modelización neural del cerebro en el mercado?
Esta parte explora técnicas avanzadas para integrar MQL5 con potentes herramientas de procesamiento de datos y se centra en el manejo eficiente de grandes volúmenes de datos para mejorar el análisis comercial y la toma de decisiones.
¡Bienvenidos a la tercera entrega de nuestra serie sobre tendencias! Hoy profundizaremos en el uso de la divergencia como estrategia para identificar puntos de entrada óptimos dentro de la tendencia diaria predominante. También presentaremos un mecanismo de bloqueo de ganancias personalizado, similar a un stop-loss dinámico, pero con mejoras únicas. Además, actualizaremos el asesor experto Trend Constraint a una versión más avanzada, incorporando una nueva condición de ejecución comercial para complementar las existentes. A medida que avanzamos, continuaremos explorando la aplicación práctica de MQL5 en el desarrollo algorítmico, brindándole información más detallada y técnicas prácticas.
En este artículo veremos cómo integrar MetaTrader 5 y el servidor Discord para recibir notificaciones de transacciones en tiempo real desde cualquier parte del mundo. Además, aprenderemos a configurar la plataforma y Discord para asegurarnos de que las alertas se envían a Discord, y hablaremos de los problemas de seguridad que surgen al utilizar WebRequest y webhooks para estos métodos de notificación.
Hoy analizaremos uno de los posibles enfoques para organizar el almacenamiento del código fuente de un proyecto en un repositorio público. Utilizando la distribución en diferentes ramas, crearemos reglas claras y cómodas para el desarrollo del proyecto.
Durante décadas, los operadores han utilizado la fórmula del criterio de Kelly para determinar la proporción óptima de capital que se debe asignar a una inversión o apuesta con el fin de maximizar el crecimiento a largo plazo y minimizar el riesgo de ruina. Sin embargo, seguir ciegamente el criterio de Kelly utilizando el resultado de una sola prueba retrospectiva suele ser peligroso para los operadores individuales, ya que en el trading en vivo, la ventaja comercial disminuye con el tiempo y el rendimiento pasado no es un indicador de resultados futuros. En este artículo, presentaré un enfoque realista para aplicar el criterio de Kelly a la asignación de riesgos de uno o más EA en MetaTrader 5, incorporando los resultados de la simulación de Monte Carlo de Python.
Hoy profundizamos en la incorporación de métricas de trading útiles dentro de una ventana especializada integrada en el EA del Panel de Administración.
Este debate se centra en la implementación de MQL5 para desarrollar un panel de análisis y destaca el valor de los datos que proporciona a los administradores de operaciones bursátiles. El impacto es principalmente educativo, ya que se extraen valiosas lecciones del proceso de desarrollo, lo que beneficia tanto a los desarrolladores noveles como a los experimentados. Esta función demuestra las oportunidades ilimitadas que ofrece esta serie de desarrollo al equipar a los gestores comerciales con herramientas de software avanzadas. Además, exploraremos la implementación de las clases PieChart y ChartCanvas como parte de la continua expansión de las capacidades del panel del administrador de operaciones.
Este artículo presenta la transformación del conocido y popular método de optimización ADAM basado en gradientes en un algoritmo basado en poblaciones y su modificación con la introducción de individuos híbridos. El nuevo enfoque permite crear agentes que combinen elementos de soluciones exitosas mediante una distribución de probabilidades. Una innovación clave es la generación de poblaciones híbridas que acumulan de forma adaptativa la información de las soluciones más prometedoras, mejorando la eficacia de la búsqueda en espacios multidimensionales complejos.
Aprenda a recuperar, procesar, clasificar, ordenar, analizar y gestionar posiciones cerradas, órdenes e historiales de operaciones utilizando MQL5 mediante la creación de una amplia biblioteca EX5 de gestión de historiales con un enfoque detallado paso a paso.
Qué son los gráficos de precios multidimensionales en 3D y cómo se crean. Cómo las barras 3D predicen las inversiones de precios, y cómo Python y MetaTrader 5 permiten construir estas barras volumétricas en tiempo real.
Mientras trabajan en proyectos en el MetaEditor, los desarrolladores se enfrentan a la necesidad de gestionar las versiones del código. A pesar de los planes de traslado a GIT y el lanzamiento de MQL5 Algo Forge, la integración aún no está completa. El presente artículo analizará posibles formas de mejorar la usabilidad de las herramientas actuales.
Se trata de un algoritmo propio. En este artículo, le presentaremos el Algoritmo de viaje evolutivo en el tiempo (TETA), inspirado en el concepto de universos paralelos y flujos temporales. La idea básica del algoritmo es que, si bien no es posible viajar en el tiempo en el sentido habitual, podemos elegir una secuencia de acontecimientos que generen realidades distintas.
Hoy le presentamos un innovador algoritmo comercial que combina algoritmos evolutivos con aprendizaje profundo por refuerzo para la negociación de divisas. El algoritmo utiliza un mecanismo de extinción de individuos ineficaces para optimizar la estrategia comercial.
Estamos pasando de simplemente ver las métricas analizadas en gráficos a una perspectiva más amplia que incluye la integración de Telegram. Esta mejora permite que los resultados importantes se envíen directamente a tu dispositivo móvil a través de la aplicación Telegram. Acompáñenos en este viaje que exploraremos juntos en este artículo.
CatBoost es un potente modelo de aprendizaje automático basado en árboles que se especializa en la toma de decisiones basada en características estacionarias. Otros modelos basados en árboles, como XGBoost y Random Forest, comparten características similares en cuanto a su solidez, capacidad para manejar patrones complejos e interpretabilidad. Estos modelos tienen una amplia gama de usos, desde el análisis de características hasta la gestión de riesgos. En este artículo, vamos a explicar el procedimiento para utilizar un modelo CatBoost entrenado como filtro para una estrategia clásica de seguimiento de tendencias con cruce de medias móviles.
Le presentamos MQL5 Algo Forge, un portal especial para desarrolladores de algoritmos comerciales. El portal combina las características de Git con una interfaz fácil de usar para mantener y organizar proyectos dentro del ecosistema MQL5. Aquí podrá suscribirse a autores que le resulten interesantes, crear equipos y llevar a cabo proyectos conjuntos sobre trading algorítmico.
Para continuar avanzando, sería bueno ver si podemos mejorar los resultados realizando periódicamente optimizaciones automáticas repetidas y generando un nuevo asesor experto. El escollo en muchos argumentos sobre el uso de la optimización de parámetros es la cuestión de cuánto tiempo pueden usarse los parámetros obtenidos para operar en el periodo futuro manteniendo los principales indicadores de rentabilidad y reducción en los niveles dados. ¿Es posible en general lograrlo?