Modelos de regresión no lineal en la bolsa de valores: ¿Es posible predecir los mercados financieros? Consideremos la creación de un modelo para pronosticar precios para EURUSD y crear dos robots basados en él: en Python y MQL5.
Los avisos de seguridad, como los que se activan cada vez que actualiza el gráfico, agrega un nuevo par al chat con el EA del Panel de administración o reinicia la terminal, pueden volverse tediosos. En esta discusión, exploraremos e implementaremos una función que rastrea la cantidad de intentos de inicio de sesión para identificar a un usuario confiable. Después de una determinada cantidad de intentos fallidos, la aplicación pasará a un procedimiento de inicio de sesión avanzado, que también facilita la recuperación de la contraseña para los usuarios que la hayan olvidado. Además, cubriremos cómo se puede integrar eficazmente la criptografía en el Panel de administración para mejorar la seguridad.
En este artículo, presentamos el algoritmo de optimización aritmética (AOA) basado en operaciones aritméticas simples: suma, resta, multiplicación y división. Estas operaciones matemáticas básicas sirven como base para encontrar soluciones óptimas a diversos problemas.
¿Cómo aplicar las reglas predictivas del análisis minorista de supermercados al mercado Forex real? ¿Cómo se relacionan las compras de galletas, leche y pan con las transacciones bursátiles? El artículo analiza un enfoque innovador del trading algorítmico basado en el uso de reglas de asociación.
Ya hemos creado bastantes componentes que ayudan a organizar la optimización automática. Durante la creación, seguimos la estructura cíclica tradicional: desde la creación de código mínimo funcional hasta la refactorización y la obtención de código mejorado. Es hora de empezar a limpiar nuestra base de datos, que también es un componente clave en el sistema que estamos creando.
En esta última entrega de nuestra serie de bibliotecas Connexus, exploramos la implementación del patrón Observer, así como refactorizaciones esenciales de rutas de archivos y nombres de métodos. Esta serie cubrió todo el desarrollo de Connexus, diseñado para simplificar la comunicación HTTP en aplicaciones complejas.
En este artículo continuamos con el desarrollo de la biblioteca Connexus. En este capítulo creamos la clase CHttpClient, responsable de enviar una solicitud y recibir un orden. También cubrimos el concepto de simulaciones, dejando la biblioteca desacoplada de la función WebRequest, lo que permite una mayor flexibilidad para los usuarios.
En este artículo se finaliza la implementación del breakeven por atr y rr en MQL5, junto con el desarrollo desde cero de una clase que permite cambiar fácilmente el tipo de breakeven sin necesidad de reingresar los parámetros. Se realizan múltiples backtests para evaluar el rendimiento de cada tipo, analizando sus ventajas y desventajas en el contexto del trading algorítmico.
El artículo analiza el desarrollo de un sistema de negociación inspirado en la cuántica, pasando de un prototipo en Python a una implementación en MQL5 para la negociación en el mundo real. El sistema utiliza principios de computación cuántica, como la superposición y el entrelazamiento, para analizar los estados del mercado, aunque funciona en ordenadores clásicos utilizando simuladores cuánticos. Las características principales incluyen un sistema de tres qubits para analizar ocho estados del mercado simultáneamente, períodos de revisión de 24 horas y siete indicadores técnicos para el análisis del mercado. Aunque los índices de precisión puedan parecer modestos, proporcionan una ventaja significativa cuando se combinan con estrategias adecuadas de gestión de riesgos.
En este artículo, mejoraremos el Panel de Gestión Comercial de nuestro Panel de Administración multifuncional. Hoy introduciremos una potente función de ayuda que simplificará el código, mejorando su legibilidad, su mantenimiento y su eficiencia. También demostraremos cómo integrar sin problemas botones adicionales y mejorar la interfaz para gestionar una gama más amplia de tareas de negociación. Ya sea para gestionar posiciones, ajustar órdenes o simplificar las interacciones de los usuarios, esta guía le ayudará a desarrollar un panel de gestión de operaciones sólido y sencillo de usar.
La función del administrador de operaciones va más allá de las comunicaciones por Telegram; también puede participar en diversas actividades de control, como la gestión de órdenes, el seguimiento de posiciones y la personalización de interfaces. En este artículo, compartiremos información práctica sobre cómo ampliar nuestro programa para admitir múltiples funcionalidades en MQL5. Esta actualización tiene como objetivo superar la limitación actual del Panel de administración, que se centra principalmente en la comunicación, permitiéndole gestionar una gama más amplia de tareas.
Hoy estudiaremos un nuevo enfoque del análisis de las tendencias del mercado basado en la visualización tridimensional y el análisis tensorial de la microestructura del mercado.
Este artículo ampliará la clase de gestión de operaciones para incluir órdenes de compra y venta con límite (buy-stop y sell-stop) con el fin de operar con eventos de noticias e implementar una restricción de vencimiento en estas órdenes para evitar cualquier operación nocturna. Se incorporará una función de deslizamiento (slippage) al experto para intentar prevenir o minimizar el posible deslizamiento que puede producirse al utilizar órdenes stop en las operaciones, especialmente durante eventos noticiosos.
El algoritmo de agujero negro (BHA) utiliza los principios de la gravedad de los agujeros negros para optimizar las soluciones. En este artículo, analizaremos cómo el BHA atrae las mejores soluciones evitando los extremos locales, y por qué este algoritmo se ha convertido en una poderosa herramienta para resolver problemas complejos. Descubra cómo ideas sencillas pueden dar lugar a resultados impresionantes en el mundo de la optimización.
Hoy desarrollaremos un sistema comercial modular que combina Python para el análisis de datos con MQL5 para la ejecución de transacciones. Sus cuatro módulos independientes supervisan en paralelo distintos aspectos del mercado: volúmenes, arbitraje, economía y riesgo, y utilizan RandomForest con 400 árboles para el análisis. Se hace especial hincapié en la gestión del riesgo, porque sin una gestión eficaz del riesgo, ni siquiera los algoritmos comerciales más avanzados sirven de mucho.
En este sexto artículo de la serie de la biblioteca Connexus, nos centraremos en una solicitud HTTP completa, cubriendo cada componente que la conforma. Crearemos una clase que represente la solicitud en su conjunto, lo que nos ayudará a reunir las clases creadas anteriormente.
El número de estrategias que se pueden integrar en un Asesor Experto es prácticamente ilimitado. Sin embargo, cada estrategia adicional aumenta la complejidad del algoritmo. Al incorporar múltiples estrategias, un Asesor Experto puede adaptarse mejor a las condiciones cambiantes del mercado, lo que puede mejorar su rentabilidad. Hoy exploraremos cómo implementar MQL5 para una de las estrategias más destacadas desarrolladas por Richard Donchian, mientras continuamos mejorando la funcionalidad de nuestro Asesor Experto Trend Constraint.
Este artículo analiza la integración de la criptografía en MQL5, mejorando la seguridad y la funcionalidad de los algoritmos de trading. Cubriremos los métodos criptográficos clave y su aplicación práctica en el comercio automatizado.
¿Cómo funciona la negociación de portafolios en Fórex? ¿Cómo pueden sintetizarse la teoría de portafolios de Markowitz para optimizar las proporciones de los portafolios y el modelo VaR para optimizar el riesgo de los portafolios? Hoy crearemos un código de teoría de portafolios en el que, por un lado, obtendremos un riesgo bajo y, por otro, una rentabilidad aceptable a largo plazo.
Hoy descubriremos al lector el nuevo mundo del trading automatizado con barras 3D. ¿Qué aspecto tiene un robot comercial basado en barras de precios multidimensionales, y pueden los clústeres "amarillos" de barras tridimensionales predecir los cambios de tendencia? ¿Cómo es el trading en múltiples dimensiones?
En este artículo, comprenderemos los métodos HTTP y los códigos de estado, dos piezas muy importantes de la comunicación entre el cliente y el servidor en la web. Comprender lo que hace cada método le brinda el control para realizar solicitudes con mayor precisión, informando al servidor qué acción desea realizar y haciéndolo más eficiente.
En la segunda parte del artículo, seguiremos desarrollando una versión modificada del algoritmo AOS (Atomic Orbital Search), centrándonos en operadores específicos para mejorar su eficacia y adaptabilidad. Tras analizar los fundamentos y la mecánica del algoritmo, discutiremos ideas para mejorar el rendimiento y la capacidad de analizar espacios de soluciones complejos, proponiendo nuevos enfoques para ampliar su funcionalidad como herramienta de optimización.
Imagine un actor malicioso infiltrándose en la sala del administrador comercial y obteniendo acceso a las computadoras y al panel de administración que se utilizan para comunicar información valiosa a millones de comerciantes en todo el mundo. Una intrusión de este tipo podría tener consecuencias desastrosas, como el envío no autorizado de mensajes engañosos o clics aleatorios en botones que desencadenan acciones no deseadas. En esta discusión, exploraremos las medidas de seguridad en MQL5 y las nuevas características de seguridad que hemos implementado en nuestro Panel de administración para protegernos contra estas amenazas. Al mejorar nuestros protocolos de seguridad, nuestro objetivo es proteger nuestros canales de comunicación y mantener la confianza de nuestra comunidad comercial global. Encuentre más información en la discusión de este artículo.
En este artículo, realizaremos una visualización de datos mejorada que va más allá de los gráficos básicos, incorporando características como interactividad, datos en capas y elementos dinámicos, lo que permite a los operadores explorar tendencias, patrones y correlaciones de manera más eficaz.
En este artículo, exploramos el concepto de cuerpo en las solicitudes HTTP, que es esencial para enviar datos como JSON y texto sin formato. Discutimos y explicamos cómo usarlo correctamente con los encabezados adecuados. También presentamos la clase ChttpBody, parte de la biblioteca Connexus, que simplificará el trabajo con el cuerpo de las solicitudes.
En este artículo, ampliaremos cuidadosamente la biblioteca Dialog existente para incorporar la lógica de gestión de temas. Además, integraremos métodos para cambiar de tema en las clases CDialog, CEdit y CButton utilizadas en nuestro proyecto de Panel de administración. Continúe leyendo para obtener perspectivas más reveladoras.
Continuamos desarrollando la biblioteca Connexus. En este capítulo, exploramos el concepto de cabeceras en el protocolo HTTP, explicando qué son, para qué sirven y cómo usarlos en las solicitudes. Cubrimos los principales encabezados utilizados en las comunicaciones con API y mostramos ejemplos prácticos de cómo configurarlos en la biblioteca.
¿Cómo se relacionan el clima y el mercado de divisas? La teoría económica clásica no ha reconocido durante mucho tiempo la influencia de estos factores en el comportamiento del mercado. Pero ahora las cosas han cambiado. Hoy intentaremos encontrar conexiones entre el estado del tiempo y la posición de las divisas agrarias en el mercado.
En este artículo seguiremos analizando los métodos restantes de optimización de la biblioteca ALGLIB, prestando especial atención a su comprobación con funciones multivariantes complejas. Esto nos permitirá no solo evaluar el rendimiento de cada algoritmo, sino también identificar sus puntos fuertes y débiles en diferentes condiciones.
En este artículo, exploramos cómo integrar los comandos en Telegram con MQL5 para automatizar la adición de indicadores en los gráficos de trading. Cubrimos el proceso de análisis sintáctico de los comandos del usuario, ejecutándolos en MQL5, y probando el sistema para asegurar un comercio basado en indicadores sin problemas.
Hoy, exploraremos las posibilidades de incorporar múltiples estrategias en un Asesor Experto (Expert Advisor, EA) utilizando MQL5. Los asesores expertos ofrecen capacidades más amplias que solo indicadores y scripts, lo que permite enfoques comerciales más sofisticados que pueden adaptarse a las condiciones cambiantes del mercado. Encuentre más información en este artículo de discusión.
Hasta ahora, hemos analizado la automatización del inicio de los procedimientos de optimización secuencial de los asesores expertos exclusivamente en el simulador de estrategias estándar. Pero, ¿qué ocurrirá si, entre una ejecución y otra, queremos procesar los datos ya adquiridos con otras herramientas? Hoy intentaremos añadir la posibilidad de crear nuevos pasos de optimización ejecutados por programas escritos en Python.
Este artículo explora los fundamentos del protocolo HTTP, cubriendo los métodos principales (GET, POST, PUT, DELETE), los códigos de estado y la estructura de las URL. Además, presenta el inicio de la construcción de la librería Conexus con las clases CQueryParam y CURL, que facilitan la manipulación de URLs y parámetros de consulta en peticiones HTTP.
En este artículo se estudia el uso del breakeven aplicado a estrategias automáticas en MQL5. Se parte de una explicación sencilla sobre qué es, cómo se implementa y cuáles son sus posibles variantes. Luego, se integra la funcionalidad dentro de un bot de Order Blocks, creado en el último artículo sobre gestión de riesgo. Para evaluar su comportamiento, se ejecutaron dos backtest bajo condiciones específicas: uno sin breakeven y otro con esta función activa.
En este artículo, nos centraremos en el estilo visual de la interfaz gráfica de usuario (GUI) de nuestro Panel de Administrador de Trading utilizando MQL5. Exploraremos diversas técnicas y funciones disponibles en MQL5 que permiten personalizar y optimizar la interfaz, garantizando que satisfaga las necesidades de los operadores al tiempo que mantiene una estética atractiva.
Las bandas de Bollinger son un indicador de envolvente muy común utilizado por muchos traders para colocar y cerrar operaciones manualmente. Examinamos este indicador considerando las diferentes señales posibles que genera, y vemos cómo se podrían poner en uso en un Asesor Experto montado por un asistente.
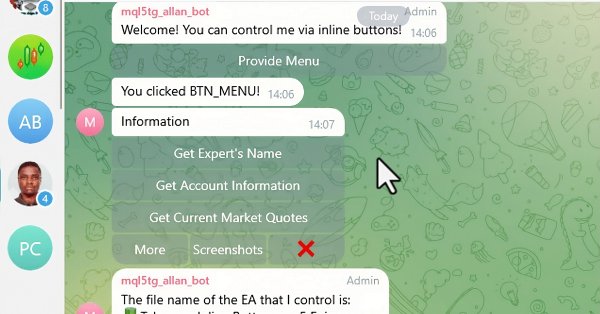
En este artículo, integramos botones interactivos en línea en un Asesor Experto MQL5, permitiendo el control en tiempo real a través de Telegram. Cada pulsación de botón desencadena acciones específicas y envía respuestas al usuario. También modularizamos las funciones para manejar los mensajes de Telegram y las consultas de devolución de llamada de forma eficiente.
Este artículo explora un algoritmo de selección de características introducido en el artículo 'Local Feature Selection for Data Classification' de Narges Armanfard et al. El algoritmo se implementa en Python para construir modelos clasificadores binarios que pueden integrarse con aplicaciones de MetaTrader 5 para la inferencia.
Este artículo es el comienzo de una serie de desarrollos para una biblioteca llamada “Connexus” para facilitar las solicitudes HTTP con MQL5. El objetivo de este proyecto es brindarle al usuario final esta oportunidad y mostrarle cómo utilizar esta biblioteca auxiliar. Mi intención era hacerlo lo más sencillo posible para facilitar el estudio y ofrecer la posibilidad de desarrollos futuros.
En este artículo, vamos a mejorar la capacidad de respuesta del Panel de administración que hemos creado anteriormente. Además, exploraremos la importancia de los mensajes rápidos en el contexto de las señales de negociación.