Búsqueda de arquitectura neuronal, un enfoque automatizado para determinar la configuración ideal de la red neuronal, puede ser una ventaja cuando se enfrentan muchas opciones y grandes conjuntos de datos de prueba. Analizamos cómo, cuando se combinan vectores propios, este proceso puede resultar aún más eficiente.
El algoritmo de Conformer que le mostraremos hoy se desarrolló para la previsión meteorológica, una esfera del saber que, por su constante variabilidad, puede compararse con los mercados financieros. El Conformer es un método completo que combina las ventajas de los modelos de atención y las ecuaciones diferenciales ordinarias.
Daremos un paseo por el arbitraje estadístico, buscaremos con Python símbolos de correlación y cointegración, haremos un indicador para el coeficiente de Pearson y haremos un EA para operar arbitraje estadístico con predicciones hechas con Python y modelos ONNX.
En este artículo, pasaremos rápidamente por algunos métodos para obtener la función que podría representar nuestros datos en la base. No me adentraré en detalles sobre cómo usar estadísticas y estudios de probabilidad para interpretar los resultados. Dejo esto como tarea para aquellos que realmente deseen profundizar en la parte matemática del asunto. De todas formas, estudiar estos temas será crucial para que puedas comprender todo lo que involucra los estudios de redes neuronales. Aquí seré bastante suave con el tema.
Aquí, comenzaremos a ver cómo podemos implementar, utilizando MQL5 puro, el cálculo de la pseudo inversa. A pesar de que el código que veremos será considerablemente más complicado para los principiantes de lo que realmente me gustaría presentar, aún estoy pensando en cómo explicarlo de manera sencilla. Considera esto una oportunidad para estudiar un código poco común. Así que ve con calma. Sin prisa. Aunque no esté enfocado en ser eficiente o de rápida ejecución, el objetivo es ser lo más didáctico posible.
En este artículo presentamos la implementación de un algoritmo de selección de características descrito en un artículo académico titulado "FREL: Un algoritmo de selección de características estable", llamado Ponderación de características como aprendizaje regularizado basado en energía.
Aquí en este artículo, veremos algunas cosas, entre ellas: Cómo muchas veces las fórmulas matemáticas parecen más complicadas cuando las miramos, que cuando las implementamos en código. Además de este hecho, también se mostrará cómo puedes ajustar el cuadrante del gráfico, así como un problema curioso que puede suceder en tu código MQL5. Algo que sinceramente no sé cómo explicar, ya que no lo entendí. A pesar de eso, mostraré cómo corregirlo en el código.
Es muy probable que no te hayas dado cuenta de que el modelado de las matrices era un tanto extraño, ya que no se indicaban filas y columnas, solo columnas. Esto resulta muy raro al leer un código que realiza factorizaciones de matrices. Si esperabas ver las filas y columnas indicadas, podrías haberte sentido bastante confundido al intentar implementar la factorización. Además, esa forma de modelar las matrices no es, ni de cerca, la mejor manera. Esto se debe a que, cuando modelamos matrices de esa forma, nos enfrentamos a ciertas limitaciones que nos obligan a usar otras técnicas o funciones que no serían necesarias si el modelado se realiza de manera más adecuada.
Descubra la guía definitiva para principiantes sobre cómo crear asesores expertos (Expert Advisors, EAs) con MQL5 en nuestro artículo completo. Aprenda paso a paso cómo construir EA usando pseudocódigo y aprovechar el poder del código generado por IA. Ya sea que sea nuevo en el comercio algorítmico o busque mejorar sus habilidades, esta guía proporciona un camino claro para crear EA efectivos.
El algoritmo de optimización de ballenas (WOA) es un algoritmo metaheurístico inspirado en el comportamiento y las estrategias de caza de las ballenas jorobadas. La idea básica del WOA es imitar el método de alimentación denominado "red de burbujas", en el que las ballenas crean burbujas alrededor de la presa para atacarla después en espiral.
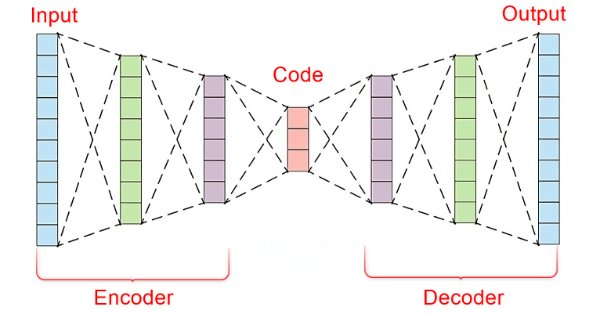
En el vertiginoso mundo de los mercados financieros, separar las señales significativas del ruido es crucial para operar con éxito. Al emplear sofisticadas arquitecturas de redes neuronales, los autocodificadores destacan a la hora de descubrir patrones ocultos en los datos de mercado, transformando datos ruidosos en información práctica. En este artículo, exploramos cómo los autocodificadores están revolucionando las prácticas de negociación, ofreciendo a los operadores una poderosa herramienta para mejorar la toma de decisiones y obtener una ventaja competitiva en los dinámicos mercados actuales.
En este artículo continuamos nuestra exploración de la familia de algoritmos del método de manejo de datos en grupo, con la implementación del algoritmo combinatorio junto con su encarnación refinada, el algoritmo combinatorio selectivo en MQL5.
En el quinto artículo de nuestra serie, nos familiarizaremos con el mundo de los arrays en MQL5. Este artículo ha sido pensado para principiantes. En este artículo intentaremos repasar conceptos complejos de programación de manera simplificada para que el material resulte comprensible para todos. Asimismo, exploraremos conceptos básicos, discutiremos diferentes cuestiones y compartiremos conocimientos.
Desarrollar un robot de trading basado en aprendizaje automático: Una guía detallada. El primer artículo de la serie trata de la recogida y preparación de datos y características. El proyecto se ejecuta utilizando el lenguaje de programación y las librerías Python, así como la plataforma MetaTrader 5.
En este artículo, le presentamos el algoritmo GTGAN, introducido en enero de 2024 para resolver problemas complejos de disposición arquitectónica con restricciones gráficas.
Los algoritmos de agrupamiento en el aprendizaje automático son importantes algoritmos de aprendizaje no supervisado que pueden dividir los datos originales en grupos con observaciones similares. Utilizando estos grupos, puede analizar el mercado de un grupo específico, buscar los grupos más estables utilizando nuevos datos y hacer inferencias causales. El artículo propone un método original de agrupación de series temporales en Python.
En este artículo, analizaremos el generador de números aleatorios Mersenne Twister y lo compararemos con el estándar en MQL5. También determinaremos la influencia de la calidad del generador de números aleatorios en los resultados de los algoritmos de optimización.
En este artículo hablaremos de los problemas relacionados con los explicadores y la explicabilidad en la IA. Los modelos de IA suelen tomar decisiones difíciles de explicar. Además, el uso de múltiples explicadores suele provocar el llamado "problema del desacuerdo". Al fin y al cabo, la comprensión clara del funcionamiento de los modelos resulta fundamental para aumentar la confianza en la IA.
El artículo está dedicado al desarrollo de un modelo de aprendizaje profundo GRU ONNX en Python. En la parte práctica, implementaremos este modelo en un asesor comercial y, a continuación, compararemos el rendimiento del modelo GRU con LSTM (memoria a largo plazo).
Sumérjase en el corazón de las redes neuronales mientras desmitificamos los algoritmos de optimización utilizados dentro de la red neuronal. En este artículo, descubra las técnicas clave que liberan todo el potencial de las redes neuronales, impulsando sus modelos a nuevas cotas de precisión y eficacia.
En este artículo, nos sumergiremos en el mundo de la hibridación de algoritmos de optimización analizando tres tipos clave: la mezcla de estrategias y la hibridación secuencial y paralela. Asimismo, realizaremos una serie de experimentos combinando y probando los algoritmos de optimización correspondientes.
La fusión espacio-temporal, que utiliza métricas espaciales y temporales en la modelización de datos, es útil sobre todo en teledetección y otras muchas actividades visuales para comprender mejor nuestro entorno. Gracias a un artículo publicado, adoptamos un enfoque novedoso en su uso examinando su potencial para los comerciantes.
Hoy continuaremos un experimento cuyo objetivo es investigar el comportamiento de los algoritmos de optimización basados en poblaciones en el contexto de su capacidad para abandonar eficazmente los mínimos locales cuando la diversidad de la población es baja y alcanzar los máximos globales. Resultados del estudio.
En el artículo anterior, nos familiarizamos con uno de los métodos para detectar objetos en una imagen. Sin embargo, el procesamiento de una imagen estática se diferencia ligeramente del trabajo con series temporales dinámicas que incluyen la dinámica de los precios que hemos analizado. En este artículo les presentaré un método de detección de objetos en vídeo que resulta algo más cercano al problema que estamos resolviendo.
En trabajos anteriores, siempre evaluábamos el estado actual del entorno. Al mismo tiempo, la dinámica de los cambios en los indicadores siempre permaneció «entre bastidores». En este artículo quiero presentarle un algoritmo que permite evaluar el cambio directo de los datos entre 2 estados ambientales sucesivos.
Este artículo trata el tema del emparejamiento en la inferencia causal. El emparejamiento se usa para emparejar observaciones similares en un conjunto de datos. Esto es necesario para identificar correctamente los efectos causales, eliminando el sesgo. Hoy explicaremos cómo esto ayuda a crear sistemas comerciales basados en el aprendizaje automático que se vuelven más robustos con nuevos datos en los que no se ha entrenado. El papel principal lo asignaremos a la puntuación de propensión, ampliamente utilizada en la inferencia causal.
¿Podemos beneficiarnos de la estacionalidad al crear modelos para Deep Learning con Python? ¿Ayuda el filtrado de datos para los modelos ONNX a obtener mejores resultados? ¿Qué periodo de tiempo debemos utilizar? Trataremos todo esto a lo largo de este artículo.
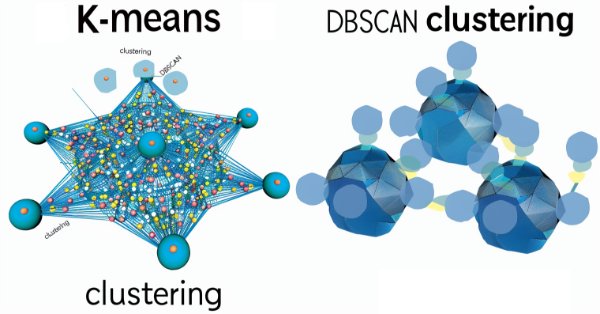
El agrupamiento basado en densidad para aplicaciones con ruido (DBSCAN) es una forma no supervisada de agrupar datos que apenas requiere parámetros de entrada, salvo solo 2, lo cual, en comparación con otros enfoques como k-means, es una ventaja. Profundizamos en cómo esto podría ser constructivo para probar y eventualmente operar con Asesores Expertos montados por Wizard MQL5.
Los formatos de datos usados para representar modelos de aprendizaje automático desempeñan un papel clave en su eficacia. En los últimos años, se han desarrollado varios tipos de datos nuevos específicamente para trabajar con modelos de aprendizaje profundo. En este artículo nos centraremos en dos nuevos formatos de datos que se han generalizado en los modelos modernos.
ONNX es una gran herramienta para la integración de código complejo de IA entre diferentes plataformas, es una gran herramienta que viene con algunos desafíos que uno debe abordar para obtener el máximo provecho de ella, En este artículo se discuten los problemas comunes que podría enfrentar y cómo mitigarlos.
El presente material supone un intento único de investigación para combinar una variedad de algoritmos de población en una sola clase y simplificar la aplicación de técnicas de optimización. Este enfoque no solo descubre oportunidades para el desarrollo de nuevos algoritmos, incluidas variantes híbridas, sino que también crea un banco de pruebas básico y versátil. Este banco se convertirá así en una herramienta clave para seleccionar el algoritmo óptimo según un problema específico.
En este artículo, le propongo abordar la creación de una estrategia comercial desde una perspectiva diferente. Hoy no pronosticaremos los movimientos futuros de los precios, sino que trataremos de construir un sistema comercial basado en el análisis de datos históricos.
Las máquinas de vectores de soporte clasifican los datos en función de clases predefinidas explorando los efectos de aumentar su dimensionalidad. Se trata de un método de aprendizaje supervisado bastante complejo dado su potencial para tratar datos multidimensionales. Para este artículo consideramos cómo su implementación muy básica de datos bidimensionales puede hacerse más eficientemente con el polinomio de Newton al clasificar precio-acción.
En este artículo analizaremos los métodos de reducción de la dimensionalidad y su aplicación en el entorno comercial MQL5. En concreto, exploraremos los matices del análisis discriminante lineal (LDA) y el análisis de componentes principales (PCA) y analizaremos su impacto en el desarrollo de estrategias y el análisis de mercados.
Embárquese en la siguiente fase de nuestro viaje MQL5. En este artículo para principiantes analizaremos el resto de funciones de la matriz y desmitificaremos conceptos complejos para que pueda elaborar estrategias de negociación eficaces. Hablaremos de ArrayPrint, ArrayInsert, ArraySize, ArrayRange, ArrarRemove, ArraySwap, ArrayReverse y ArraySort. Aumente su experiencia en negociación algorítmica con estas funciones de matriz esenciales. ¡Únase a nosotros en el camino hacia el dominio de MQL5!
En nuestros modelos, a menudo utilizamos varios algoritmos de atención. Y, probablemente, lo más frecuente es utilizar transformadores. Su principal desventaja es la necesidad de recursos. En este artículo, estudiaremos un nuevo algoritmo que puede ayudar a reducir los costes informáticos sin perder calidad.
Este artículo continúa con el tema de la predicción del próximo movimiento de los precios. Le invito a conocer la arquitectura del Transformador Multifuturo. Su idea principal es descomponer la distribución multimodal del futuro en varias distribuciones unimodales, lo que permite simular eficazmente varios modelos de interacción entre agentes en la escena.
Los modelos que creamos son cada vez más grandes y complejos. Esto aumenta los costes no sólo de su formación, sino también de su funcionamiento. Sin embargo, el tiempo necesario para tomar una decisión suele ser crítico. A este respecto, consideremos los métodos para optimizar el rendimiento del modelo sin pérdida de calidad.