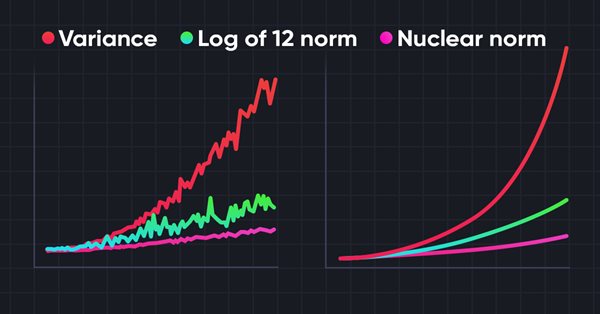
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.
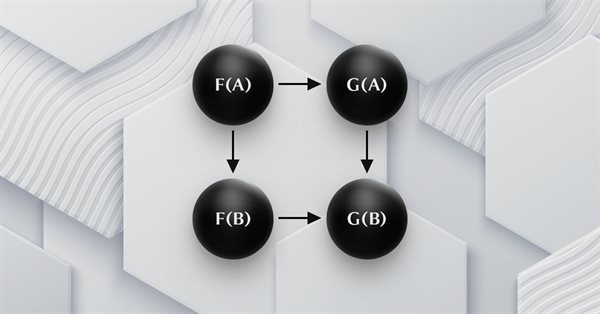
El artículo continúa la serie sobre teoría de categorías, presentando transformaciones naturales que suponen un elemento clave de la teoría. Hoy echaremos un vistazo a su definición (aparentemente compleja) y luego profundizaremos en los ejemplos y métodos de aplicación de las transformaciones para pronosticar la volatilidad.
El aprendizaje contrastivo (Contrastive learning) supone un método de aprendizaje de representación no supervisado. Su objetivo consiste en entrenar un modelo para que destaque las similitudes y diferencias entre los conjuntos de datos. En este artículo, hablaremos del uso de enfoques de aprendizaje contrastivo para investigar las distintas habilidades del Actor.
Este es el último artículo de la serie sobre funtores. En él, revisaremos los monoides como categoría. Los monoides, que ya hemos introducido en esta serie, se utilizan aquí para ayudar a dimensionar la posición junto con los perceptrones multicapa.
Siempre que analizamos métodos de aprendizaje por refuerzo, nos enfrentamos al problema de explorar eficientemente el entorno. Con frecuencia, la resolución de este problema hace que el algoritmo se complique, llevándonos al entrenamiento de modelos adicionales. En este artículo veremos un enfoque alternativo para resolver el presente problema.
Seguimos analizando los funtores y cómo se pueden implementar utilizando redes neuronales artificiales. Dejaremos temporalmente el enfoque que implica el pronóstico de la volatilidad e intentaremos implementar nuestra propia clase de señales para establecer señales de entrada y salida para una posición.
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.
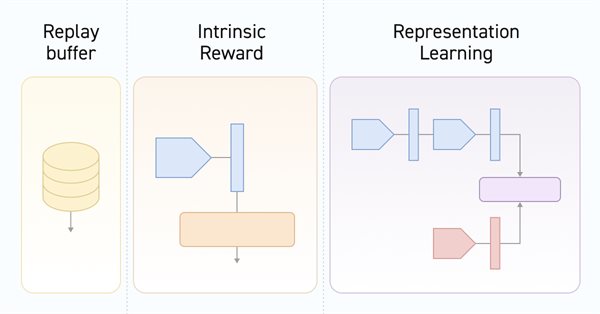
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.
El artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5, analizando los funtores como un puente entre grafos y conjuntos. Volveremos nuevamente a los datos del calendario y, a pesar de sus limitaciones en el uso de un simulador de estrategias, justificaremos el uso de funtores para predecir la volatilidad mediante la correlación.
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.
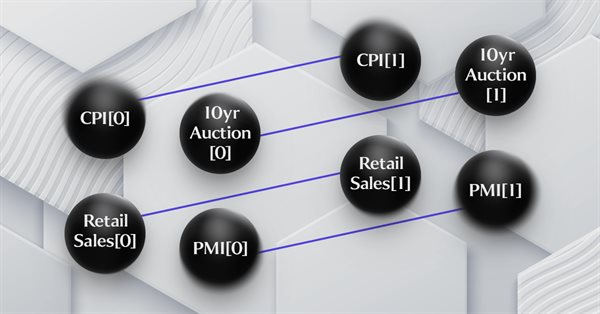
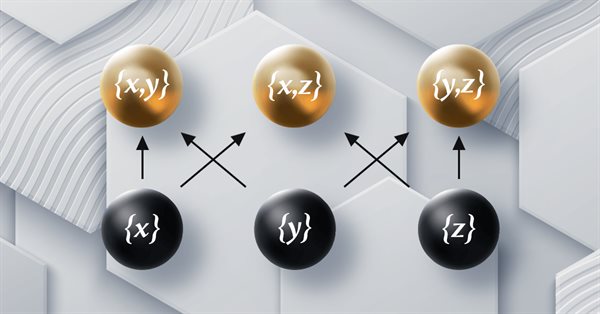
Este artículo de la serie sobre la implementación de la teoría de categorías en MQL5 está dedicado a los funtores. Hoy veremos cómo asignar el orden lineal a un conjunto utilizando funtores al analizar dos conjuntos de datos que parecen no tener relación entre sí.
En el artículo anterior, implementamos el algoritmo Soft Actor-Critic (SAC), pero no pudimos entrenar un modelo rentable. En esta ocasión, optimizaremos el modelo creado previamente para obtener los resultados deseados en su rendimiento.
El artículo analiza cómo se pueden incluir esquemas de bases de datos para la clasificación en MQL5. Vamos a repasar brevemente cómo los conceptos de esquema de base de datos pueden combinarse con la teoría de categorías para identificar información textual (cadenas) relevante para el comercio. La atención se centrará en los eventos del calendario.
Continuamos nuestro análisis de los algoritmos de aprendizaje por refuerzo en problemas de espacio continuo de acciones. En este artículo, le propongo introducir el algoritmo Soft Astog-Critic (SAC). La principal ventaja del SAC es su capacidad para encontrar políticas óptimas que no solo maximicen la recompensa esperada, sino que también tengan la máxima entropía (diversidad) de acciones.
En el artículo anterior, presentamos el método DDPG, que nos permite entrenar modelos en un espacio de acción continuo. Sin embargo, al igual que otros métodos de aprendizaje Q, el DDPG tiende a sobreestimar los valores de la función Q. Con frecuencia, este problema provoca que entrenemos los agentes con una estrategia subóptima. En el presente artículo, analizaremos algunos enfoques para superar el problema mencionado.
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.
En este artículo ampliamos el abanico de tareas de nuestro agente. El proceso de entrenamiento incluirá algunos aspectos de la gestión de capital y del riesgo que forma parte integral de cualquier estrategia comercial.
La regresión es una tarea que consiste en predecir un valor real a partir de un ejemplo sin etiquetar. Para evaluar la precisión de las predicciones de los modelos de regresión, se usan las llamadas métricas de regresión.
En el artículo de hoy, nos familiarizaremos con otra tendencia en el campo del aprendizaje por refuerzo. Se denomina aprendizaje por refuerzo dirigido a objetivos (Goal-conditioned reinforcement learning, GCRL). En este enfoque, el agente se entrenará para alcanzar diferentes objetivos en determinados escenarios.
El entrenamiento de habilidades útiles sin una función de recompensa explícita es uno de los principales desafíos del aprendizaje por refuerzo jerárquico. Ya nos hemos familiarizado antes con dos algoritmos para resolver este problema, pero el tema de la exploración del entorno sigue abierto. En este artículo, veremos un enfoque distinto en el entrenamiento de habilidades, cuyo uso dependerá directamente del estado actual del sistema.
En el artículo anterior, nos familiarizamos con el método DIAYN, que ofrece un algoritmo para el aprendizaje de diversas habilidades. El uso de las habilidades aprendidas puede aprovecharse en diversas tareas, pero estas habilidades pueden resultar bastante impredecibles, lo cual puede dificultar su uso. En este artículo, analizaremos un algoritmo para el aprendizaje de habilidades predecibles.
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. En este artículo examinaremos las acciones de los monoides como un medio de transformación de los monoides descritos en el artículo anterior para aumentar sus aplicaciones.
El problema del aprendizaje por refuerzo reside en la necesidad de definir una función de recompensa, que puede ser compleja o difícil de formalizar. Para resolver esto, se están estudiando enfoques basados en la variedad de acciones y la exploración del entorno que permiten aprender habilidades sin una función de recompensa explícita.
En este artículo, veremos métodos asociados con el análisis de series temporales en el dominio de la frecuencia. También prestaremos atención a los beneficios del estudio de las funciones espectrales de series temporales al construir modelos predictivos. Además, analizaremos algunas perspectivas prometedoras para el análisis de series temporales en el dominio de la frecuencia utilizando la transformada discreta de Fourier (DFT).
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.
Uno de los principales retos del aprendizaje por refuerzo es la exploración del entorno. Con anterioridad, hemos aprendido un método de exploración basado en la curiosidad interior. Hoy queremos examinar otro algoritmo: la exploración mediante el desacuerdo.
En este artículo, describiremos solo uno de los aspectos del aprendizaje automático: las funciones de activación. En las redes neuronales artificiales, las funciones de activación de neuronas calculan el valor de la señal de salida en función de los valores de una señal de entrada o un conjunto de señales de entrada. Hoy le mostraremos lo que hay "debajo del capó".
Ejemplo de utilización de un perceptrón como herramienta autónoma de predicción de precios. En el artículo exploraremos los conceptos generales y veremos un sencillo asesor experto ya preparado, así como los resultados de su optimización.
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.
¿Quiere encontrar un nuevo enfoque comercial que lo ayude a orientarse en mercados complejos y en cambio constante? Eche un vistazo a los mapas de Kohonen, una forma innovadora de redes neuronales artificiales que puede ayudarle a descubrir patrones y tendencias ocultos en los datos del mercado. En este artículo, veremos cómo funcionan los mapas de Kohonen y cómo usarlos para desarrollar estrategias comerciales efectivas. Creo que este nuevo enfoque resultará de interés tanto a los tráders experimentados como para los principiantes.
ONNX (Open Neural Network eXchange) es un estándar abierto para representar redes neuronales. En este artículo, le mostraremos la posibilidad de usar dos modelos ONNX simultáneamente en un asesor experto.
En el artículo anterior, analizamos los modelos relacionales que utilizan mecanismos de atención en su arquitectura. Una de las características de dichos modelos es su mayor uso de recursos informáticos. Este artículo propondrá uno de los posibles mecanismos para reducir el número de operaciones computacionales dentro del bloque Self-Attention o de auto-atención, lo cual aumentará el rendimiento del modelo en su conjunto.
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.
ONNX (Open Neural Network Exchange) es un estándar abierto para representar modelos de redes neuronales. En este artículo, analizaremos el proceso de creación de un modelo CNN-LSTM para pronosticar series temporales financieras, y también el uso del modelo ONNX creado en un asesor experto MQL5.
El artículo describe los principios, métodos y posibilidades del uso del algoritmo electromagnético (EM) en diversos problemas de optimización. El algoritmo EM es una herramienta de optimización eficiente capaz de trabajar con grandes cantidades de datos y funciones multidimensionales.