Desta vez, veremos exemplos de passagem de indicadores ao perceptron. Abordaremos conceitos gerais, um Expert Advisor simples pronto, os resultados de sua otimização e testes forward.
As últimas 2 partes foram dedicadas ao método transformador de decisões (DT), que modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. Neste artigo, vamos considerar outro algoritmo de otimização deste método.
Os modelos de linguagem são uma parte importante da inteligência artificial que evolui rapidamente, por isso devemos pensar em como integrar LLMs poderosos em nossa negociação algorítmica. Para a maioria das pessoas, é desafiador configurar esses poderosos modelos de acordo com suas necessidades, implementá-los localmente e, em seguida, aplicá-los à negociação algorítmica. Esta série de artigos explorará uma abordagem passo a passo para alcançar esse objetivo.
Mergulhe no mundo do ONNX, um poderoso formato aberto para compartilhar modelos de aprendizado de máquina. Descubra como o uso do ONNX pode revolucionar a negociação algorítmica em MQL5, permitindo que os traders integrem sem obstáculos modelos avançados de inteligência artificial e elevem suas estratégias a um novo patamar. Desvende os segredos da compatibilidade entre plataformas e aprenda a desbloquear todo o potencial do ONNX em sua negociação no MQL5. Melhore sua negociação com este guia detalhado sobre ONNX.
Neste artigo, exploraremos o uso de todos os modelos de classificação do pacote Scikit-learn para resolver o problema de classificação dos íris de Fisher, tentaremos convertê-los para o formato ONNX e usaremos os modelos resultantes em programas MQL5. Também compararemos a precisão dos modelos originais e suas versões ONNX no Iris dataset completo.
No artigo anterior, nos familiarizamos com o transformador de decisões. Porém, o complexo ambiente estocástico do mercado de moedas não permitiu revelar totalmente o potencial do método apresentado. Hoje, quero apresentar a vocês um algoritmo focado em melhorar o desempenho dos algoritmos em ambientes estocásticos.
Como o intuito aqui é ser didático. Vou manter a coisa no seu padrão mais simples. Ou seja, iremos implementar apenas e somente o que será preciso. A multiplicação de matrizes. E você verá que isto será o suficiente para simular a multiplicação de uma matriz por um escalar. A grande dificuldade que muita gente tem em implementar um código usando fatoração de matrizes, é que diferente de uma fatoração escalar, onde em quase todos os casos a ordem dos fatores não altera o resultado. Quando se usa matrizes, a coisa não é bem assim.
O artigo aborda a busca por difusão estocástica, SDS, um algoritmo de otimização muito poderoso e prático, baseado nos princípios de passeio aleatório. O algoritmo permite encontrar soluções ótimas em espaços multidimensionais complexos, possuindo uma alta velocidade de convergência e a capacidade de evitar extremos locais.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
Neste artigo, continuamos a explorar indicadores de negociação populares sob uma nova ótica. Vamos processar a composição horizontal de transformações naturais. O melhor indicador para isso é a média móvel exponencial dupla (Double Exponential Moving Average, DEMA).
Continuamos a explorar os métodos de aprendizado por reforço. Neste artigo, proponho apresentar um algoritmo ligeiramente diferente que considera a política do agente sob a perspectiva de construir uma sequência de ações.
Neste artigo, tentaremos simplificar a descrição dos conceitos discutidos nesta série, focando apenas em um indicador, o mais comum e, provavelmente, o mais fácil de entender. Estamos falando da média móvel. Também examinaremos o significado e as possíveis aplicações das transformações naturais verticais.
Como foi explicado na parte teórica. Precisamos usar regressões lineares e derivadas, quando o assunto é rede neural. Mas por que ?!?! O motivo disto, é que a regressão linear é uma das fórmulas mais simples que existe. Basicamente uma regressão linear, é apenas uma função afim. Porém quando falamos em rede neural, não estamos interessados na reta, que a regressão linear cria. Estamos interessados é na equação que gera tal reta. A reta gerada pouco importa. Mas você sabe qual é a equação principal a ser compreendida ?!?! Se não veja este artigo para começar a entender.
Este artigo discute um algoritmo da família MEC, denominado algoritmo simples de evolução da mente (Simple MEC, SMEC). O algoritmo se destaca pela beleza da ideia subjacente e pela simplicidade de implementação.
Este artigo, o 21º de nossa série, continua nossa análise das transformações naturais e de como elas podem ser implementadas usando a análise discriminante linear. Assim como no artigo anterior, a implementação é apresentada no formato de uma classe de sinal.
O artigo apresenta uma descrição detalhada do algoritmo salto de sapo embaralhado (Shuffled Frog Leaping Algorithm, SFL) e suas capacidades na solução de problemas de otimização. O algoritmo SFL é inspirado no comportamento dos sapos em seu ambiente natural e oferece uma nova abordagem para a otimização de funções. O algoritmo SFL é uma ferramenta eficaz e flexível, capaz de lidar com diversos tipos de dados e alcançar soluções ótimas.
Vamos nos afastar um pouco de nossos tópicos mais comuns e analisar uma parte do algoritmo do ChatGPT. Ele possui algumas semelhanças ou conceitos emprestados das transformações naturais? Vamos tentar responder a essas e outras perguntas usando nosso código no formato de classe de sinal.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
Apresentamos um algoritmo relativamente novo, o Stochastic Marginal Actor-Critic (SMAC), que permite a construção de políticas de variáveis latentes no contexto da maximização da entropia.
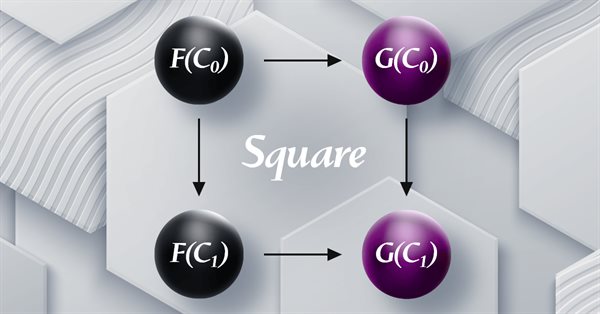
Continuamos a análise das transformações naturais, examinando a indução do quadrado de naturalidade. Por causa das limitações na implementação de várias moedas para os Expert Advisors desenvolvidos com o assistente MQL5, temos de buscar soluções criativas e eficientes para a classificação de dados usando scripts. As principais áreas de aplicação consideradas são a classificação de variações de preço e, consequentemente, sua previsão.
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!
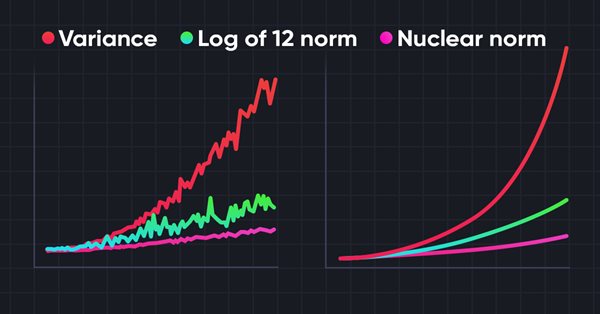
A pesquisa do ambiente em tarefas de aprendizado por reforço é um problema atual. Anteriormente, já examinamos algumas abordagens. E hoje, eu proponho que nos familiarizemos com mais um método, baseado na maximização da norma nuclear. Ele permite que os agentes destaquem estados do ambiente com alto grau de novidade e diversidade.
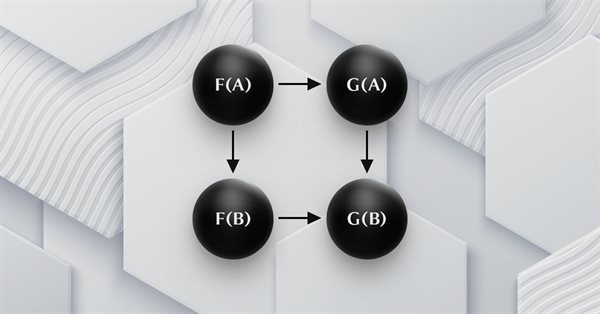
Este artigo dá continuidade à série sobre a teoria das categorias, abordando as transformações naturais, que são um elemento fundamental da teoria. Vamos examinar a definição que parece complexa à primeira vista, depois mergulhar em exemplos e formas de aplicar as transformações na previsão de volatilidade.
O aprendizado contrastivo é um método de aprendizado de representação sem supervisão. Seu objetivo é ensinar o modelo a identificar semelhanças e diferenças nos conjuntos de dados. Neste artigo, discutiremos o uso de abordagens de aprendizado contrastivo para explorar diferentes habilidades do Ator.
Este é o último artigo da série dedicada a funtores. Nele, reconsideramos monoides como uma categoria. Os monoides, que já apresentamos nesta série, são usados aqui para ajudar na definição do tamanho da posição juntamente com perceptrons multicamadas.
A cada vez que consideramos métodos de aprendizado por reforço, nos deparamos com a questão da exploração eficiente do ambiente. A solução deste problema frequentemente leva à complexificação do algoritmo e ao treinamento de modelos adicionais. Neste artigo, vamos considerar uma abordagem alternativa para resolver esse problema.
Continuamos a examinar funtores e como eles podem ser implementados usando redes neurais artificiais. Vamos temporariamente deixar de lado a abordagem que incluía a previsão de volatilidade, e tentar implementar nossa própria classe de sinais para estabelecer sinais para entrar e sair de uma posição.
Já falamos várias vezes sobre a importância de escolher corretamente a função de recompensa que usamos para incentivar o comportamento desejável do Agente, adicionando recompensas ou penalidades por ações específicas. Mas a questão de como o Agente interpreta nossos sinais permanece em aberto. Neste artigo, discutiremos a decomposição da recompensa em termos de transmissão de sinais individuais ao Agente a ser treinado.
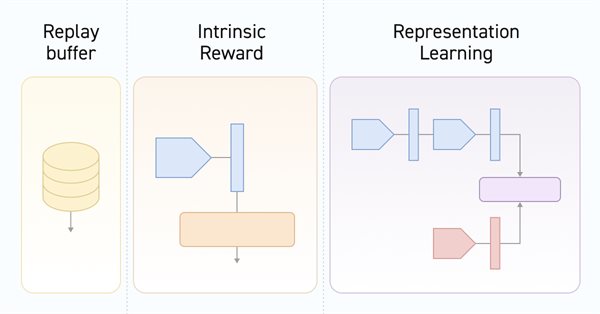
À medida que a política do Ator se afasta cada vez mais dos exemplos armazenados no buffer de reprodução de experiências, a eficácia do treinamento do modelo, baseado nesse buffer, diminui. Neste artigo, examinamos um algoritmo que aumenta a eficácia do uso de amostras em algoritmos de aprendizado por reforço.
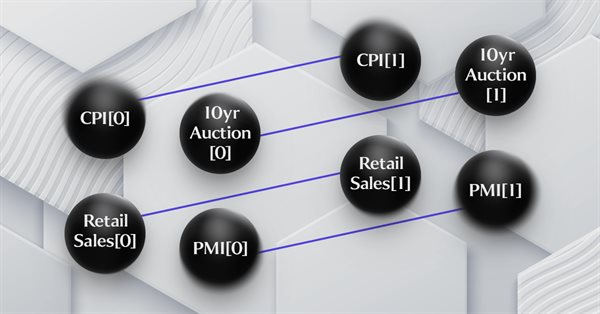
Este artigo continua a série sobre a implementação da teoria de categorias no MQL5, ele aborda os funtores como uma ponte entre grafos e conjuntos. Nesse escopo, voltaremos a analisar os dados de calendário e, apesar de suas limitações no uso do testador de estratégias, justificaremos o uso de funtores na previsão de volatilidade mediante correlação.
Este artigo explora a implementação de jogadas automáticas no jogo da velha Python, integrado com funções MQL5 e testes unitários. O objetivo é aprimorar a interatividade do jogo e garantir a robustez do sistema através de testes MQL5. Ele aborda desde o desenvolvimento da lógica de jogo até a integração e testes práticos, culminando na criação de um ambiente de jogo dinâmico e um sistema integrado confiável.
Nos últimos dois artigos, discutimos o algoritmo Soft Actor-Critic, que incorpora regularização de entropia na função de recompensa. Essa abordagem permite equilibrar a exploração do ambiente e a exploração do modelo, mas é aplicável apenas a modelos estocásticos. Neste artigo, exploraremos uma abordagem alternativa que é aplicável tanto a modelos estocásticos quanto determinísticos.
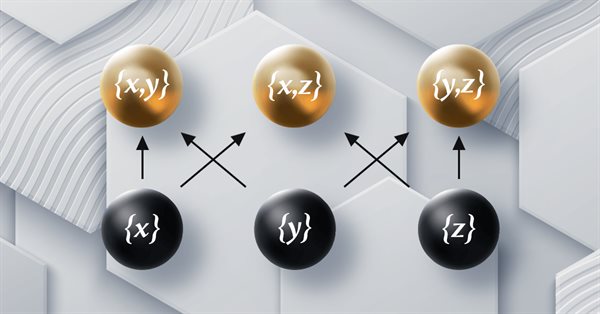
Este artigo, parte de uma série de artigos sobre a implementação da teoria das categorias no MQL5, é dedicado aos funtores. Vamos explorar como a ordem linear pode ser mapeada em um conjunto de dados através dos funtores ao analisar dois conjuntos de dados que, à primeira vista, parecem não ter nenhuma conexão entre si.
No artigo anterior, implementamos o algoritmo Soft Actor-Critic, mas não conseguimos treinar um modelo lucrativo. Neste artigo, vamos realizar a otimização do modelo previamente criado para obter os resultados desejados a nível de seu funcionamento.
Neste artigo, discutimos como os esquemas de banco de dados podem ser incorporados para categorização em MQL5. Analisaremos brevemente como os conceitos de esquema de banco de dados podem ser combinados com a teoria da categoria na identificação de informações de texto (string) relevantes para a negociação. O foco será em eventos de calendário.
Continuamos nossa exploração dos algoritmos de aprendizado por reforço na resolução de problemas em espaços de ação contínua. Neste artigo, apresento o algoritmo Soft Actor-Critic (SAC). A principal vantagem do SAC está em sua capacidade de encontrar políticas ótimas que não apenas maximizam a recompensa esperada, mas também têm a máxima entropia (diversidade) de ações.
Este artigo aborda a importância das APIs (Interfaces de Programação de Aplicativos) na comunicação entre diferentes aplicativos e sistemas de software. Ele destaca o papel das APIs na simplificação da interação entre aplicativos, permitindo que eles compartilhem dados e funcionalidades de maneira eficiente.
No artigo anterior, nós exploramos o método DDPG, projetado para treinar modelos em espaços de ação contínua. No entanto, como outros métodos de aprendizado Q, ele está sujeito ao problema da sobreavaliação dos valores da função Q. Esse problema geralmente leva eventualmente ao treinamento de um agente com uma estratégia não otimizada. Neste artigo, examinaremos algumas abordagens para superar o problema mencionado.
Este artigo faz parte de uma série sobre a implementação de grafos usando a teoria das categorias no MQL5 e é dedicado à teoria da ordem (Order Theory). Consideraremos dois tipos básicos de ordenação e exploraremos como os conceitos de relação de ordem podem auxiliar os conjuntos monoidais na tomada de decisões de negociação.
Neste artigo, estamos ampliando o escopo das tarefas do nosso agente. No processo de treinamento, incluiremos alguns aspectos de gerenciamento de dinheiro e risco, que são partes integrantes de qualquer estratégia de negociação.