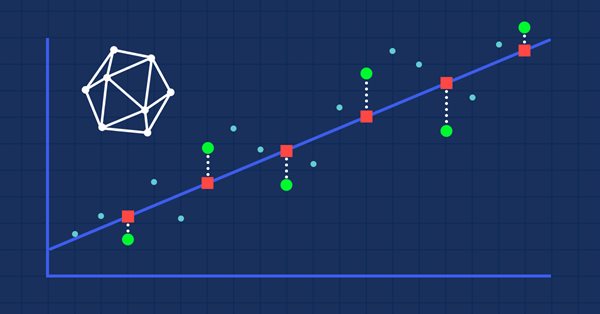
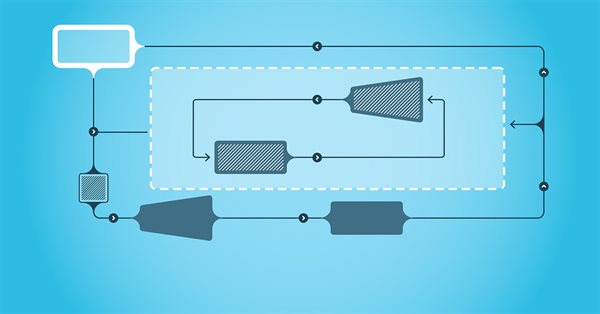
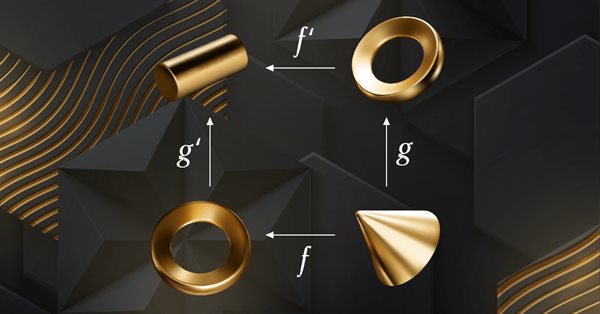Convido você a conhecer mais uma abordagem no campo do aprendizado por reforço. É chamada de aprendizado por reforço condicionado a metas, conhecida pela sigla GCRL (Goal-conditioned reinforcement learning). Nessa abordagem, o agente é treinado para alcançar diferentes metas em cenários específicos.
A regressão é uma tarefa de prever um valor real a partir de um exemplo não rotulado. Para avaliar a precisão das previsões de modelos de regressão, são utilizadas as chamadas métricas de regressão.
Aprender habilidades úteis sem uma função de recompensa explícita é um dos principais desafios do aprendizado por reforço hierárquico. Anteriormente, já nos familiarizamos com dois algoritmos para resolver esse problema. Mas a questão da completa exploração do ambiente ainda está em aberto. Neste artigo, é apresentada uma abordagem diferente para o treinamento de habilidades, cujo uso depende diretamente do estado atual do sistema.
No artigo anterior, apresentamos o método DIAYN, que oferece um algoritmo para aprender uma variedade de habilidades. O uso das habilidades adquiridas pode ser usado para diversas tarefas. Mas essas habilidades podem ser bastante imprevisíveis, o que pode dificultar seu uso. Neste artigo, veremos um algoritmo para ensinar habilidades previsíveis.
Este artigo descreve a implementação de um modelo de regressão de árvores de decisão para prever preços de ativos financeiros. Foram realizadas etapas de preparação dos dados, treinamento e avaliação do modelo, com ajustes e otimizações. No entanto, é importante destacar que o modelo é apenas um estudo e não deve ser usado em negociações reais.
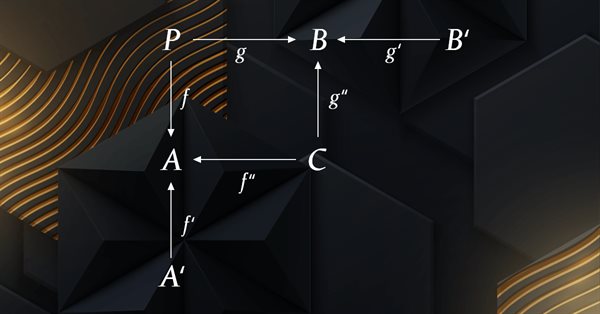
Esse artigo é a continuação da série sobre a implementação da teoria das categorias em MQL5. Nele são discutidas as ações de monoides como um meio de transformar os monoides descritos no artigo anterior para aumentar suas aplicações.
Neste artigo, analisaremos os métodos relacionados à análise de séries temporais no domínio da frequência. Ele também se concentrará na utilidade do estudo de funções espectrais de séries temporais na criação de modelos preditivos. Além disso, discutimos algumas perspectivas promissoras para a análise de séries temporais no domínio da frequência usando a transformada discreta de Fourier (DFT).
O problema com o aprendizado por reforço é a necessidade de definir uma função de recompensa, que pode ser complexa ou difícil de formular, porém abordagens baseadas no tipo de ação e na exploração do ambiente que permitem que as habilidades sejam aprendidas sem uma função de recompensa explícita estão sendo exploradas para resolver esse problema.
A procrastinação de modelos no contexto do aprendizado por reforço pode ser causada por vários motivos, e a solução desse problema requer medidas apropriadas. Este artigo discute algumas das possíveis causas da procrastinação do modelo e métodos para superá-las.
Este artigo descreve modelos hierárquicos de aprendizado que propõem uma abordagem eficaz para resolver tarefas complexas de aprendizado de máquina. Os modelos hierárquicos consistem em vários níveis, cada um responsável por aspectos diferentes da tarefa.
Neste artigo, discutiremos a aplicação do algoritmo Go-Explore ao longo de um período de treinamento prolongado, uma vez que uma estratégia de seleção aleatória de ações pode não levar a uma passagem lucrativa à medida que o tempo de treinamento aumenta.
Continuamos com o tema da exploração do ambiente no aprendizado por reforço. Neste artigo, abordaremos mais um algoritmo, o Go-Explore, que permite explorar eficazmente o ambiente durante a fase de treinamento do modelo.
Veja um exemplo do uso do perceptron como um meio autossuficiente de previsão de preços. Esse artigo aborda conceitos gerais, apresenta um Expert Advisor simples e pronto para uso e os resultados de sua otimização.
Neste artigo, descrevemos apenas um aspecto do aprendizado de máquina, em particular as funções de ativação. Em redes neurais artificiais, a função de ativação de neurônio calcula o valor de um sinal de saída com base nos valores de um sinal de entrada ou de um conjunto de sinais de entrada. Vamos mergulhar nos detalhes internos do processo.
Deseja descobrir uma nova metodologia de negociação que facilite a orientação em mercados complexos e voláteis? Explore os mapas de Kohonen - uma versão inovadora de redes neurais artificiais, capazes de identificar regularidades e tendências ocultas nos dados do mercado. Neste texto, analisaremos a funcionalidade dos mapas de Kohonen e a forma de utilizá-los na elaboração de estratégias de negociação eficazes. Estou convencido de que esta abordagem inédita será do interesse de traders novatos e experientes.
Um dos principais desafios do aprendizado por reforço é a exploração do ambiente. Anteriormente, já nos iniciamos no método de exploração baseado na curiosidade interna. E hoje proponho considerar outro algoritmo, o de exploração por desacordo.
As redes neurais são tudo para nós. E vamos verificar na prática se é assim, indagando se MetaTrader 5 é uma ferramenta autossuficiente para implementar redes neurais na negociação. A explicação vai ser simples.
A teoria das categorias é um ramo diversificado e em expansão da matemática que só recentemente começou a ser abordado na comunidade MQL5. Esta série de artigos tem como objetivo analisar alguns de seus conceitos para criar uma biblioteca aberta e utilizar ainda mais essa maravilhosa seção na criação de estratégias de negociação.
O ONNX (Open Neural Network Exchange) é um padrão aberto para a representação de modelos de redes neurais. Neste artigo, mostraremos a possibilidade de usar dois modelos ONNX simultaneamente em um Expert Advisor.
No artigo anterior, abordamos modelos relacionais que usavam mecanismos de atenção. Uma das características desses modelos era o aumento do uso de recursos computacionais. O artigo de hoje apresenta um dos mecanismos para reduzir o número de operações computacionais dentro do bloco Self-Attention, o que aumenta o desempenho geral do modelo.
A teoria das categorias é um ramo diversificado e em expansão da matemática que só recentemente começou a ser abordado na comunidade MQL5. Esta série de artigos tem como objetivo analisar alguns de seus conceitos para criar uma biblioteca aberta e utilizar ainda mais essa maravilhosa seção na criação de estratégias de negociação.
O ONNX (Open Neural Network Exchange) é um padrão aberto para a representação de modelos de redes neurais. Neste artigo, consideraremos o processo de criação do modelo SNN-LSTM para previsão de séries temporais financeiras e o uso do modelo ONNX criado em um Expert Advisor MQL5.
O artigo descreve os princípios, os métodos e as possibilidades de aplicação do EM a diferentes problemas de otimização. Ele uma ferramenta de otimização eficiente, capaz de lidar com grandes quantidades de dados e funções multidimensionais.
A teoria das categorias representa um segmento diversificado e em constante expansão da matemática, que até agora está relativamente pouco explorado na comunidade MQL5. Esta série de artigos tem como objetivo descrever alguns de seus conceitos a fim de criar uma biblioteca aberta e utilizar ainda mais essa seção notável na criação de estratégias de negociação.
O algoritmo de “mudas, semeadura e crescimento” (Saplings Sowing and Growing up, SSG) é inspirado em um dos organismos mais resistentes do planeta, um exemplo notável de sobrevivência em inúmeras condições.
Vamos tentar melhorar qualitativamente nossa análise dos mercados financeiros usando a análise de componentes principais (PCA). Aprenderemos como essa técnica pode ajudar a identificar padrões ocultos nos dados, identificar tendências de mercado ocultas e otimizar estratégias de investimento. Neste artigo, veremos como o PCA oferece uma nova perspectiva para a análise de dados financeiros complexos, ajudando-nos a ver informações que não percebemos usando abordagens tradicionais. Veremos se sua aplicação aos dados do mercado financeiro proporciona uma vantagem sobre a concorrência e nos ajuda a ficar um passo à frente.
Nos modelos de aprendizado por reforço discutidos anteriormente, usamos diferentes variantes de redes convolucionais, que são capazes de identificar diferentes corpos nos dados brutos. A principal vantagem das redes convolucionais é sua capacidade de identificar objetos independentemente de sua localização. No entanto, as redes convolucionais nem sempre são capazes de lidar com as diversas deformações e ruídos que os objetos apresentam. Mas esses problemas podem ser resolvidos pelo modelo relacional.
As redes neurais são tudo para nós. E vamos verificar na prática se é assim, indagando se MetaTrader 5 é uma ferramenta autossuficiente para implementar redes neurais na negociação. A explicação vai ser simples.
Certamente muitas pessoas estão cansadas de tentar constantemente prever o mercado de ações. Você gostaria de ter uma bola de cristal que o ajudasse a tomar melhores decisões de investimento? As redes neurais autoaprendentes podem ser a solução para isso. Neste artigo, vamos ver se esses algoritmos poderosos podem ajudar a surfar na onda e ser mais espertos que o mercado de ações. Ao analisar grandes volumes de dados e identificar padrões, as redes neurais autoaprendentes podem fazer previsões que geralmente são mais precisas do que as previsões dos traders. Vamos descobrir se essas tecnologias avançadas podem ser utilizadas para tomar decisões de investimento mais inteligentes e obter mais lucros.
Neste artigo, estaremos analisando o algoritmo do macaco (Monkey Algorithm, MA). A habilidade destes animais ágeis para superar obstáculos complexos e atingir as partes mais inacessíveis das árvores foi a inspiração para a concepção do MA.
A Teoria das Categorias representa um segmento diversificado e em constante expansão da matemática, que até agora está relativamente pouco explorado na comunidade MQL5. Esta sequência de artigos visa elucidar algumas das suas concepções com o intuito de constituir uma biblioteca aberta e potencializar ainda mais o uso deste notável setor na elaboração de estratégias de negociação.
A negociação com base em probabilidades pode ser comparada a caminhar sobre uma corda bamba - ela requer precisão, equilíbrio e uma compreensão clara do risco envolvido. No mundo do trading, a probabilidade é fundamental. É ela que determina o resultado: sucesso ou fracasso, lucro ou prejuízo. Ao aproveitar as possibilidades da probabilidade, os traders podem tomar decisões mais fundamentadas, gerenciar os riscos de maneira mais eficiente e alcançar seus objetivos financeiros. Não importa se você é um investidor experiente ou um trader iniciante, entender a probabilidade pode ser a chave para desbloquear seu potencial de negociação. Neste artigo, exploraremos o fascinante mundo do trading baseado em probabilidades e mostraremos como levar seu modo de negociar a um nível superior.
Hoje, estudaremos e testaremos o algoritmo de otimização mais avançado, a busca harmônica (HS), que é inspirada no processo de procura da harmonia sonora perfeita. Então, qual algoritmo é agora o líder em nossa classificação?
Este artigo trata da teoria e prática do uso do algoritmo de retropropagação de erros no MQL5 através de matrizes. Oferecemos classes prontas e exemplos de scripts, indicadores e EAs.
O GSA é um algoritmo populacional inspirado na natureza inanimada. Sua capacidade de modelar com alta precisão a interação entre corpos físicos, através da lei da gravidade de Newton incorporada no algoritmo, permite contemplar um espetáculo fascinante de dança entre sistemas planetários e aglomerados galácticos, representado de forma impressionante em animações. Hoje vamos discutir um dos algoritmos de otimização mais interessantes e originais. Um simulador de movimento de objetos espaciais está incluído.
O aprendizado de máquina se tornou uma técnica popular de desenvolvimento de estratégias. Na negociação, tradicionalmente, mais atenção é dada à maximização da lucratividade e à precisão das previsões. Enquanto isso, o processamento de dados usado para construir modelos preditivos permanece na periferia. Neste artigo, discutimos o uso do conceito de entropia para avaliar a adequação de indicadores na construção de modelos preditivos, conforme descrito no livro Testing and Tuning Market Trading Systems escrito por Timothy Masters.
A surpreendente capacidade das plantas daninhas de sobreviver em uma ampla variedade de condições foi a inspiração para o desenvolvimento de um poderoso algoritmo de otimização. O IWO (Invasive Weed Optimization) é considerado um dos melhores entre os analisados até o momento.
A base da estratégia de forrageamento de E. coli (E. coli) inspirou cientistas a desenvolverem o algoritmo de otimização BFO. Esse algoritmo apresenta ideias originais e abordagens promissoras para otimização e merece um estudo mais aprofundado.
As redes neurais são tudo para nós. E vamos verificar na prática se é assim, indagando se MetaTrader 5 é uma ferramenta autossuficiente para implementar redes neurais na negociação. A explicação vai ser simples.